
IntelがAI時代のデータセンターに向けて、新たな一手となるIntel Xeon 6 P-coreプロセッサー3機種を発表した。特筆すべきは、NVIDIAの最新AIシステム「DGX B300」にその一つである「Xeon 6776P」が採用された点だ。新技術「Priority Core Turbo (PCT)」と「Intel Speed Select Technology – Turbo Frequency (SST-TF)」を搭載し、GPU主導のAIワークロードにおけるCPUの役割を再定義する。この動きは、AI処理におけるCPUボトルネック解消への期待を高めるものと言えるだろう。
AIの心臓部を支えるIntelの新たな一手、Xeon 6 P-coreプロセッサー群
Intelは2025年5月22日(現地時間)、データセンター向けCPUの最新ラインナップとして、Intel Xeon 6シリーズに新たに3つのP-core(Performance-core)搭載モデルを追加投入したことを明らかにした。これらは特に、高度なGPUアクセラレーテッドAIシステムの管理と性能最大化を目的として設計されている。
発表された主なモデルは以下の通りである。
| プロセッサー名 | 総コア数 | 最大ターボ周波数 | ベース周波数 | L3キャッシュ | TDP |
|---|---|---|---|---|---|
| Intel Xeon 6776P | 64 | 3.90 GHz | 2.30 GHz | 336 MB | 350 W |
| Intel Xeon 6774P | 64 | 3.90 GHz | 2.50 GHz | 336 MB | 350 W |
| Intel Xeon 6732P | 32 | 4.3 GHz | 3.8 GHz | 144 MB | 350 W |
中でも「Intel Xeon 6776P」は、NVIDIAの最新世代AIシステム「DGX B300」のホストCPUとして採用されており、16基のBlackwell Ultra GPUを搭載するこの強力なAIプラットフォームにおいて、データの管理、処理のオーケストレーション、そしてシステム全体のサポートという極めて重要な役割を担う。Intelによれば、Xeon 6776Pの堅牢なメモリ容量と帯域幅は、増大し続けるAIモデルとデータセットの要求に応えるために不可欠だという。
Intelのデータセンターグループ担当コーポレートバイスプレジデント兼暫定ジェネラルマネージャーであるKarin Eibschitz Segal氏は、「これらの新しいXeon SKUは、Intel Xeon 6の比類なき性能を実証するものであり、次世代のGPUアクセラレーテッドAIシステムにとって理想的なCPUです。NVIDIAとの協業を深め、業界最高性能のAIシステムの一つを提供できることを嬉しく思います」とコメントしている。
GPU性能を解き放つ新技術「Priority Core Turbo (PCT)」と「SST-TF」の威力
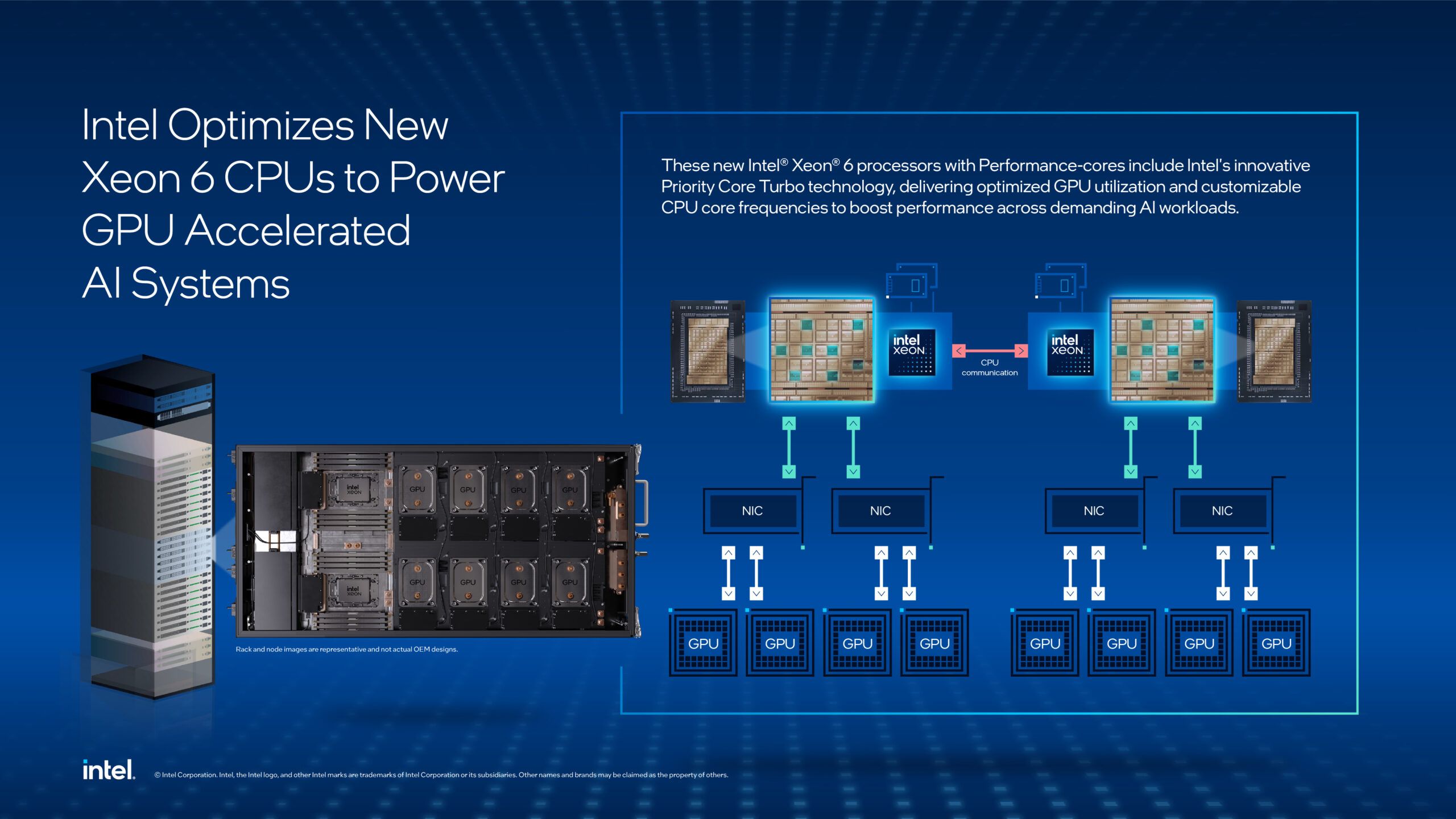
今回の発表で特に注目されるのが、AIシステム性能の飛躍的向上を目的とした新技術「Priority Core Turbo (PCT)」と「Intel Speed Select Technology – Turbo Frequency (Intel SST-TF)」の導入だ。
Priority Core Turbo (PCT) は、CPU内の特定の「優先コア」を動的に選定し、それらのコアをより高いターボ周波数で動作させる技術である。IntelのXeon部門シニアプロダクトプランナーであるMilan Mehta氏によれば、この技術により、ソケットあたり最大8つの優先コアを、定格の最大ターボ周波数を700MHz上回る4.6GHzで動作させることが可能になるという。一方で、残りのコアはベース周波数で動作し、CPUリソースの最適な配分を実現する。
Intel Speed Select Technology – Turbo Frequency (SST-TF) は、このPCTと連携し、ワークロードの需要に応じて各コアの周波数をきめ細かく調整する。
これらの技術の組み合わせは、特に逐次処理やシリアル処理がボトルネックとなりやすいAIワークロードにおいて、GPUへのデータ供給を高速化し、システム全体の効率を大幅に改善する鍵となる。これまでGPUの性能をフルに引き出せずにいたCPU側の制約を緩和し、AIモデルの学習や推論を加速させることが期待される。
AIワークロードを加速するXeon 6 P-coreの進化点
新しいXeon 6 P-coreプロセッサー群は、PCTやSST-TF以外にも、AIワークロードの処理能力を高めるための数多くの進化を遂げている。
圧倒的なコア数と優れたシングルスレッド性能
今回発表されたモデルでは最大64個のP-coreを搭載(Xeon 6シリーズ全体では最大128 Pコアまで対応)。これにより、要求の厳しいAIタスクにおいてもバランスの取れたワークロード分散が可能となる。
最大30%高速化されたメモリ性能
競合製品と比較して最大30%高速なメモリ速度を実現。これは、大容量構成時において特に顕著であり、MRDIMM(Multiplexed Rank DIMMs)やCXL(Compute Express Link)といった最先端のメモリ技術をサポートすることで、広帯域なメモリアクセスを可能にする。一部情報では、前世代と比較して最大2.3倍のメモリ帯域幅向上も謳われている。また、2DIMM per Channel (2DPC) 構成では最大8TBのシステムメモリをサポートする。
20%増のPCIeレーンでI/O性能を強化
前世代のXeonプロセッサーと比較して最大20%多いPCIeレーン数を実現。2ソケットサーバー構成時には最大192レーンものPCIeをサポートし、I/O負荷の高いワークロードにおけるデータ転送速度を大幅に向上させる。これは、巨大なデータセットを扱うAI処理において極めて重要だ。
Intel AMXの進化とFP16サポート
CPUに特定のタスクをオフロードできるIntel Advanced Matrix Extensions (AMX) は、新たにFP16(16ビット浮動小数点数)精度演算をサポート。これにより、AIワークロードにおけるデータの前処理やCPUが担う重要なタスクをより効率的に実行できるようになる。
高い信頼性と保守性
ミッションクリティカルなAIシステムを支えるため、これらのプロセッサーは最大限の稼働時間を実現するよう設計されており、ビジネスの中断を最小限に抑えるための堅牢な信頼性、可用性、保守性(RAS)機能を備えている。
NVIDIAとの協業強化とAI市場へのインパクト
NVIDIA DGX B300へのXeon 6776Pの採用は、IntelとNVIDIAという業界の巨人同士の協業関係がさらに深化していることを示す象徴的な出来事と言えるだろう。NVIDIAはDGX H100、H200、そしてB200プラットフォームでもIntel Xeonプロセッサーを採用しており、x86アーキテクチャのCPUがAIシステムにおいて依然として重要な役割を担っていることを示している。
NVIDIAは自社でArmベースのGrace CPUも開発・展開しているが、今回の選択は、特定のワークロードやシステム構成においては、Intel Xeonのような高性能x86 CPUが最適であるという判断があったものと考えられる。AIシステムにおいてCPUは、単にGPUにデータを供給するだけでなく、モデルの短期記憶にあたるキー・バリューキャッシュの管理、RAG(Retrieval Augmented Generation)パイプラインで利用されるベクトルデータベースの処理など、多岐にわたる重要なタスクを担っている。
AIインフラの展望
企業がAI技術の導入と活用を加速させる中で、AIインフラの近代化は喫緊の課題となっている。Intel Xeon 6 P-coreプロセッサーは、その性能とエネルギー効率の理想的な組み合わせにより、AIに最適化されたCPUソリューションとしてのIntelの優位性を高めることにも繋がるかもしれない。
データセンターにおけるCPUの役割は、汎用的な処理から、よりAIワークロードに特化した機能へとシフトしつつある。Intelの今回の発表は、そのトレンドを明確に反映したものと言え、今後のAIコンピューティング市場におけるCPUの進化の方向性を示す重要なマイルストーンとなるのではないだろうか。
Intelが発表した新しいXeon 6 P-coreプロセッサー群、特にNVIDIA DGX B300への採用が決定したXeon 6776Pは、AI時代におけるCPUの重要性を改めて浮き彫りにした。Priority Core TurboやSST-TFといった新技術は、GPUの性能を最大限に引き出すためのCPU側のボトルネック解消に大きく貢献することが期待される。メモリ性能やI/O性能の大幅な向上と合わせて、これらのプロセッサーは、より複雑で大規模なAIモデルの学習と推論を加速させ、AI技術のさらなる発展を支える基盤となるだろう。
Sources


