
大規模言語モデル(LLM)の進化が停滞期を迎えるかもしれない――。「データウォール」、すなわち高品質な人間生成データの枯渇が、業界の専門家たちの間で深刻な懸念として囁かれ始めている。AIが賢くなるための「教科書」が尽きてしまうのだ。この根源的な課題に対し、マサチューセッツ工科大学(MIT)の研究者たちが、そうしたAIのあり方を根本から覆しかねない画期的なフレームワーク「SEAL(Self-Adapting Language Models)」を発表した。
これは、AIがもはや静的な知識の集合体ではなく、自ら新しい情報を学び、自身の思考回路を書き換え、永続的に成長し続ける「生命体」のような存在になる可能性を示唆するものとも言われている。SEALは、AIに自らの訓練データ、いわば「自分専用の参考書」を生成させ、強化学習を通じてその学習方法自体を最適化させるのだ。
実験では、SEALを搭載した比較的小規模なモデルが、知識の統合タスクにおいて巨大なGPT-4.1が生成したデータで学習したモデルを上回る精度を達成。さらに、難解な推論タスクでは、従来手法を圧倒する72.5%という成功率を叩き出した。
AIが自ら学び、進化する時代は本当に到来するのか。本記事では、この革新的な技術「SEAL」の仕組みから、その驚異的な能力、そして実用化に向けた「破滅的忘却」という深刻な課題まで見てみよう。
AI開発の「壁」を打ち破る、自己適応という新発想
現代のLLMは、その驚異的な能力にもかかわらず、二つの大きな制約を抱えている。一つは、一度事前学習を終えると、その知識が基本的に「静的」になってしまうことだ。新しい情報やタスクに適応させるには、人間がファインチューニングやプロンプトエンジニアリングといった手間のかかる作業を行う必要があった。

そしてもう一つが、冒頭で触れた「データウォール」問題である。AIの性能向上は、インターネット上に存在する膨大なテキストデータを学習することに大きく依存してきた。しかし、この「燃料」とも言える高品質なデータは、数年以内に枯渇すると予測されている。AIがAIの生成した低品質なデータを学び始めると、性能が劣化する「モデル崩壊」のリスクも指摘されており、AI開発は大きな岐路に立たされているのだ。
MITの研究チームが提示したSEALは、これらの課題に対する根本的な解決策となりうる。その核心は、AIを情報の「受動的な消費者」から、「能動的な学習者」へと変えることにある。
MITが示した解決策「SEAL」とは何か?
SEALのコンセプトは、驚くほど人間的な学習プロセスに似ている。優秀な学生が、ただ講義ノートを読むだけでなく、情報を再整理し、自分なりの言葉でまとめ直して理解を深めるように、SEALはLLMに自らの学習プロセスを管理させる。
AIが自作する「自分だけの教科書」:セルフエディットの仕組み
SEALの中核をなすのが「セルフエディット(Self-Edit)」と呼ばれるプロセスだ。新しい情報(例えば、あるトピックに関する文章)が与えられると、LLMはそれをただ記憶するのではない。自らその情報を再構築し、学習に最適な形式の「合成データ」を生成するのである。
これは、元の文章から論理的な帰結を導き出したり、情報を質疑応答(QA)形式に書き換えたり、あるいは学習効率を高めるための技術的な指示(ハイパーパラメータの設定など)を定義したりと、多岐にわたる。いわば、LLMが自分にとって最も理解しやすい「自分だけの教科書」や「パーソナライズされた学習プラン」を自ら作り出すのだ。
試行錯誤で「賢い勉強法」を見つける:強化学習と二重ループ
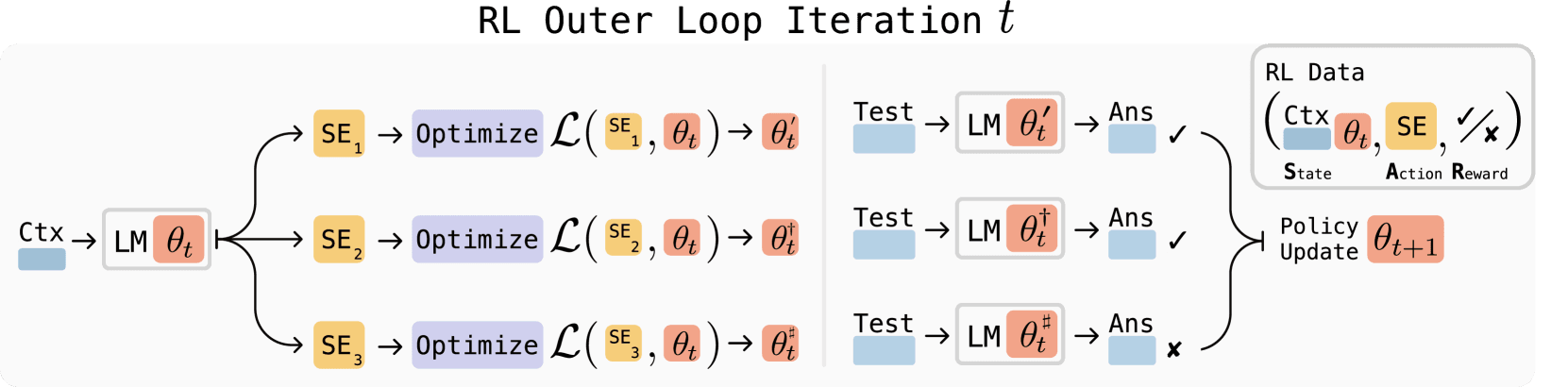
では、どうすればAIは「効果的な教科書」の作り方を学べるのだろうか。ここで登場するのが「強化学習(Reinforcement Learning)」だ。SEALは、巧妙な二重ループシステムを採用している。
- 内側ループ(学習の実践): モデルは生成した「セルフエディット」に基づき、LoRA(Low-Rank Adaptation)のような軽量な手法で自身の重み(パラメータ)を一時的に更新する。これは、学生が新しい勉強法を試してみる段階にあたる。
- 外側ループ(学習法の評価と改善): 更新されたモデルが、特定のタスク(例:関連する質問に答える)でどれだけ性能が向上したかを評価する。良い結果が出れば、その「セルフエディット」を生成した行動に「報酬」が与えられる。このフィードバックを通じて、モデルは徐々に、より効果的なセルフエディット、すなわち「賢い勉強法」を生み出す術を学習していくのだ。
この試行錯誤のプロセス全体を最適化するために、研究チームはGoogle DeepMindなどが開発した「ReST^EM」というアルゴリズムを採用。これにより、効果のあった学習法だけを効率的に強化していくことが可能になった。
実験で証明された驚異的な学習能力
SEALの有効性は、机上の空論ではない。MITの研究チームは、複数の実験を通じてその驚異的な学習能力を具体的に証明している。
小規模モデルがGPT-4.1超えを達成した「知識統合」タスク
最初の実験は、新しい事実をモデルの知識として恒久的に統合する能力を試すものだ。Alibabaが開発した「Qwen2.5-7B」というモデルに、SQuADデータセットの文章を学習させ、その内容に関する質問に文脈なしで答えられるかをテストした。
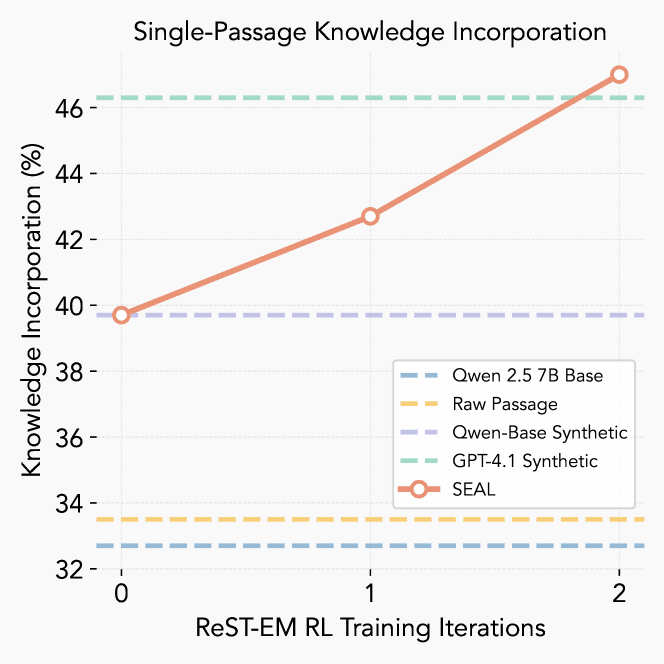
結果は目覚ましいものだった。
- 従来のファインチューニング: 元の文章だけで学習した場合の正解率は33.5%と、ほとんど向上しなかった。
- GPT-4.1の支援: より高性能なGPT-4.1に合成データを生成させて学習した場合、正解率は46.3%に向上した。
- SEALによる自己学習: SEALを適用し、Qwen2.5-7B自身が生成した合成データで学習した場合、正解率は47.0%に達し、格上のGPT-4.1の助けを借りた場合を上回ったのだ。
これは、モデルが外部から与えられたデータよりも、自らのために最適化したデータの方が学習効率が高いことを示唆する、非常に重要な結果である。
成功率72.5%を記録した「少数ショット学習」
もう一つの実験では、非常に少数の例から新しいタスクのルールを学び取る「少数ショット学習」の能力が試された。ここでは、視覚的なパズルを解く「Abstract Reasoning Corpus (ARC)」というタスクに、「Llama-3.2-1B」という小型モデルが用いられた。
- 文脈内学習(ICL): 従来の手法では成功率0%。
- 基本的な自己編集: 強化学習なしで自己編集を行った場合でも20%の成功率。
- SEALの適用: 強化学習を通じて自己編集の方法を最適化したSEALは、72.5%という圧倒的な成功率を記録した。
SEALが、単に知識を記憶するだけでなく、未知の課題に対する「学び方」そのものを学習する能力を持つことを、この結果は明確に示している。
夢の技術か、それとも絵に描いた餅か?実用化への3つの壁
SEALが描く未来は輝かしいものだが、その実用化に向けた現実的な課題にも目を向けなければならない。MITの研究チーム自身も、いくつかの重要な限界点を率直に認めている。
学ぶほどに忘れていく「破滅的忘却」というジレンマ
最も深刻な課題が「破滅的忘却(Catastrophic Forgetting)」だ。これは、AIが新しい知識を学習する過程で、以前に習得した知識を破壊的に忘れてしまう現象を指す。人間で言えば、新しい科目を一夜漬けで勉強したら、得意だったはずの科目の公式をすっかり忘れてしまった、という状態に近いかもしれない。
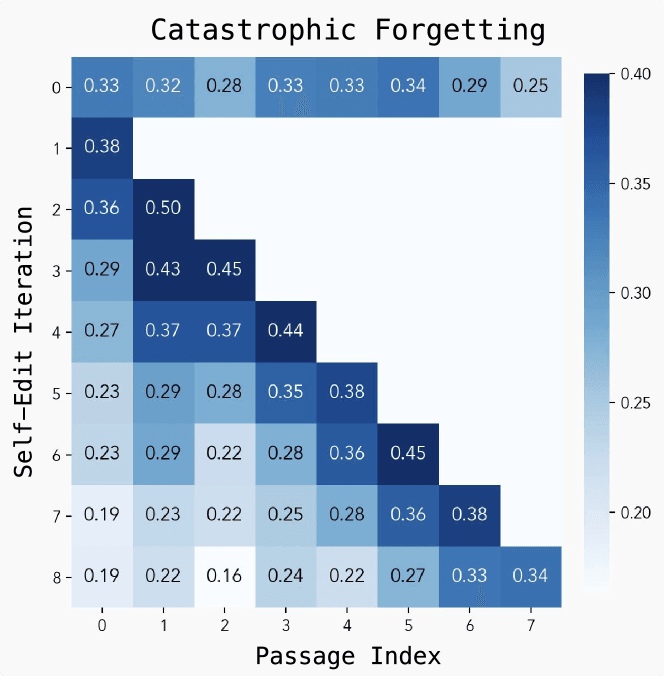
研究チームが連続して新しい情報を学習させるシミュレーションを行ったところ、学習を重ねるごとに、初期に学んだタスクの性能が徐々に低下していくことが確認された。自己改善を続けた結果、かえって能力が劣化する可能性があるという、このジレンマの解決は、SEALが真に継続的な学習を実現するための最大のハードルと言えるだろう。
1回の学習に数十分?無視できない「計算コスト」の問題
SEALの学習ループは、1回の評価(セルフエディットを生成し、モデルを更新し、性能をテストする)に30〜45秒という、決して短くない時間を要する。これは、リアルタイムでの継続的な自己改善が、現在のハードウェアでは非常に困難であることを意味する。
この点について、論文の共著者であるJyo Pari氏は、より現実的な導入モデルを提案している。
「システムが一定期間(例えば、数時間や1日)データを収集し、その後、スケジュールされた更新間隔中に的を絞った自己編集を実行する、というアプローチが考えられます」
これにより、企業は適応コストを管理しつつ、SEALの恩恵を受けることができるというわけだ。
RAGとの共存:自己改善AIの現実的な着地点
Pari氏はさらに、もう一つの現実的な解決策として、既存の技術であるRAG(Retrieval-Augmented Generation)とのハイブリッドアプローチを提唱する。
- 頻繁に変化する事実情報: 顧客の最新の注文履歴など、変わりやすいデータは外部データベースに置き、RAGで都度参照する。
- 長期的・行動的な知識: 企業の理念や、ユーザーの根本的な好みといった、モデルの振る舞いを形成するような永続的な知識は、SEALを使ってモデルの重みに直接「焼き付ける」。
このハイブリッド戦略により、破滅的忘却のリスクを抑えつつ、計算コストを管理しながら、モデルに重要な知識を永続的に統合することが可能になるかもしれない。
企業、そして社会へ―SEALがもたらす未来の展望
これらの課題を乗り越えた先には、SEALはどのような未来をもたらすのだろうか。その影響は、単一の企業アプリケーションに留まらない、より広範なものになる可能性がある。
「永遠のβ版」としてのAIエージェントの誕生
企業にとって最も魅力的な応用先の一つが、自律的に動作する「AIエージェント」だろう。SEALを搭載したエージェントは、環境との相互作用を通じて得た学びを、その都度自身の知識として内在化できる。失敗から学び、経験に基づいてパフォーマンスを向上させ、人間による継続的な指導への依存を減らしていく。
これは、常に最新の社内フレームワークを理解したコーディングアシスタントや、対話を重ねるごとにユーザーの意図を深く理解していく顧客対応AIなど、まさに「永遠のβ版」として進化し続けるAIの誕生を意味する。
データウォールの先へ:AIが自律的に知識を拡張する時代
そして、より大きな視点で見れば、SEALはAI開発のパラダイムそのものを変える可能性を秘めている。データウォールが現実のものとなった世界で、AI開発の進歩は、モデルが「自ら高品質な学習シグナルを生成する能力」にかかってくるだろう。
学術論文や金融レポートといった複雑な文書を読み込み、AIが自ら何千もの説明や含意を生成して理解を深める。このような自己表現と自己洗練の反復ループは、人間による追加の監督がなくても、AIが希少なトピックや未開拓の分野について自律的に知識を拡張し続ける未来を描き出す。
SEALは、まだ研究段階の技術であり、解決すべき課題も多い。しかし、それはもはやSFの世界の話ではなく、AIが自ら知性の階段を築き上げていく未来への、具体的かつ重要な一歩であることは間違いない。我々はこの技術の進歩を注意深く見守ると同時に、自ら進化するAIと共存する社会のあり方について、今から思考を始める必要があるだろう。
論文
参考文献


