中国のテクノロジー大手Alibabaは、最新の大規模言語モデル(LLM)ファミリー「Qwen3」を発表した。複数のベンチマーク評価において、OpenAIの「o1」やDeepSeekの「R1」といった競合モデルを上回る性能を示し、Googleの最新鋭モデル「Gemini 2.5 Pro」に匹敵する結果も報告されている。
Qwen3:新世代AIモデルファミリーの登場
AlibabaのQwenチームが発表したQwen3は、複数のモデルから構成されるAIモデルファミリーだ。 特筆すべきは、8つの新モデルのうち2つが「Mixture of Experts(MoE)」アーキテクチャを採用している点となる。 MoEは、複数の専門家(小規模なモデル)を組み合わせ、タスクに応じて関連する専門家のみを活性化させることで、計算効率を高める技術で、フランスのAIスタートアップMistral AIなどが採用し、注目を集めている技術だ。
今回リリースされたQwen3ファミリーのラインナップは以下の通りだ。
- MoEモデル:
- Qwen3-235B-A22B: 総パラメータ数2350億、活性化パラメータ数220億のフラッグシップモデル。
- Qwen3-30B-A3B: 総パラメータ数300億、活性化パラメータ数30億の小型MoEモデル。
- Denseモデル(密結合型モデル):
- Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, Qwen3-0.6B
これらのモデルの多くは、Apache 2.0ライセンスの下でオープンソースとして公開されており、GitHub、Hugging Face、ModelScope、Kaggleなどのプラットフォームからアクセス可能である。 これにより、研究者や開発者は、最先端のAIモデルを比較的自由に利用し、独自のソリューション開発に活用できる。
ベンチマークで競合を凌駕:Qwen3の性能評価
Qwen3は、様々な第三者ベンチマークにおいて、既存の有力モデルと比較して優れた性能を示している。
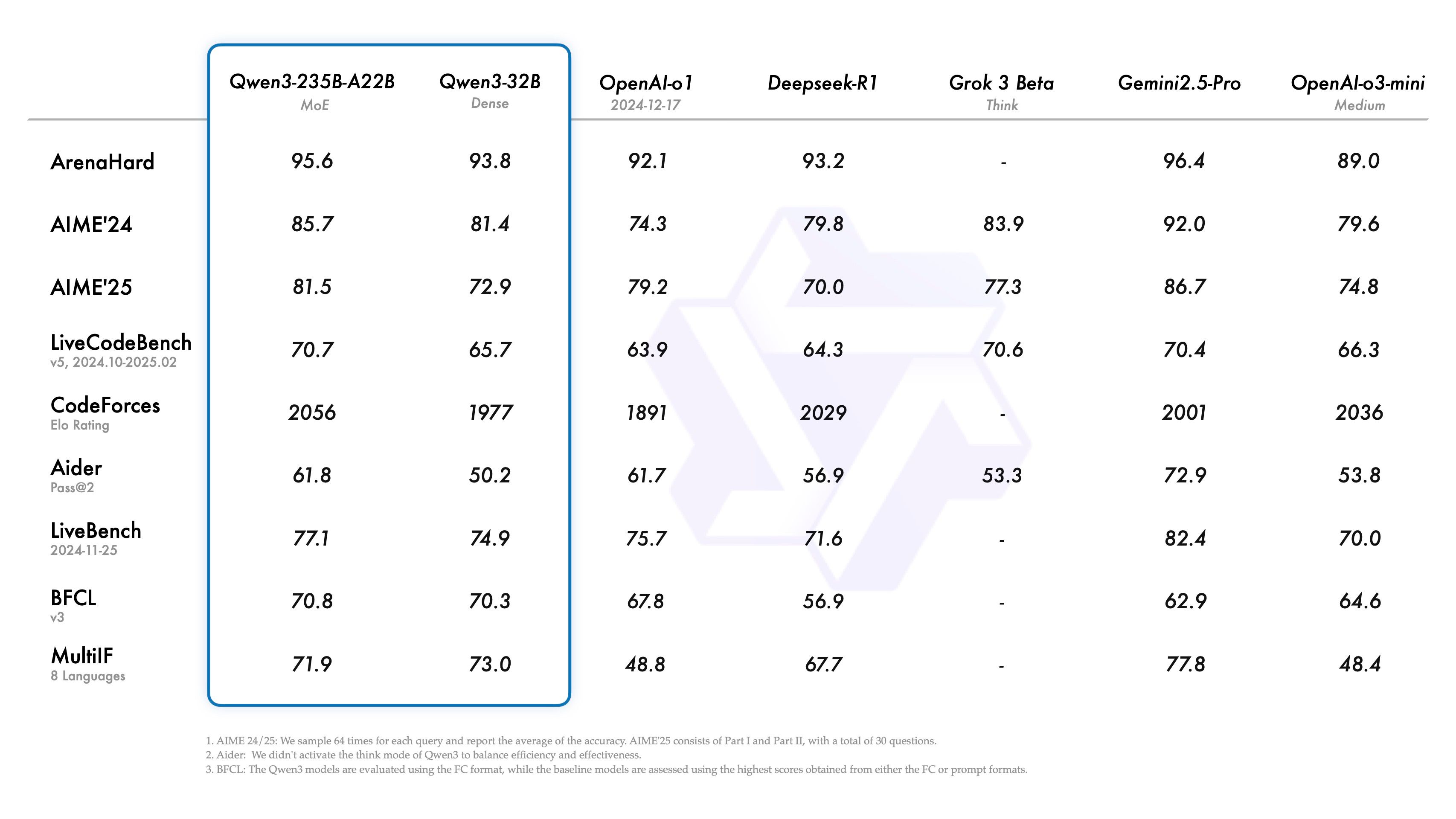
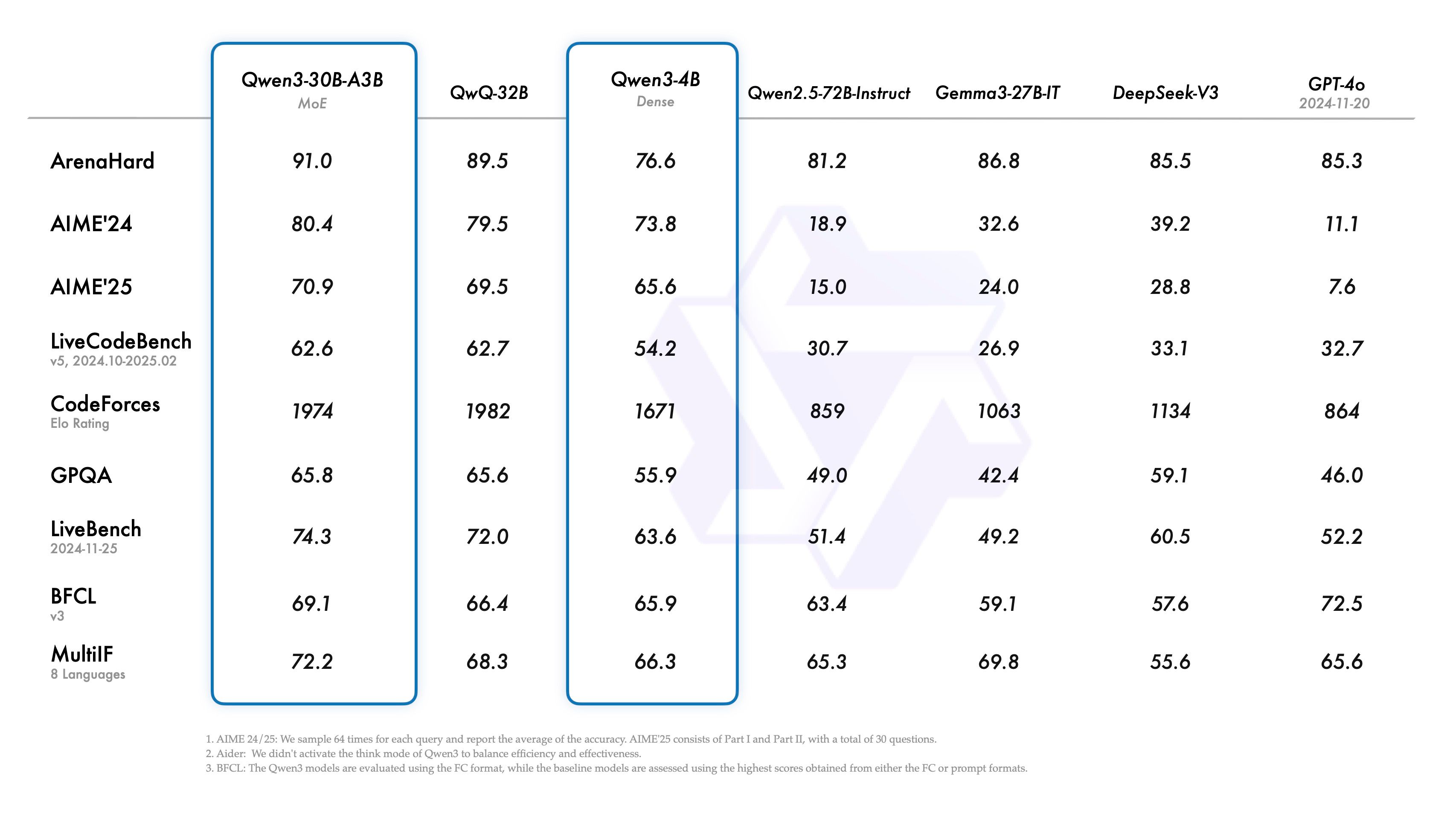
- フラッグシップモデル (Qwen3-235B-A22B):
- Alibabaの発表によると、コーディング、数学、一般能力などのベンチマーク評価で、DeepSeek-R1、o1、o3-mini、Grok-3、Gemini-2.5-Proといったトップクラスのモデルと比較して競争力のある結果を達成した。
- 特に、ソフトウェア工学や数学に関する500のユーザー質問で構成される「ArenaHard」ベンチマークでは、DeepSeek R1やOpenAIのプロプライエタリモデルo1を上回り、GoogleのGemini 2.5-Proに迫る性能を示したと報告されている。
- プログラミングコンテストプラットフォーム「Codeforces」では、OpenAIのo3-miniやGoogleのGemini 2.5 Proをわずかに上回った。
- 難解な数学ベンチマーク「AIME」の最新版や、モデルの推論能力を評価する「BFCL」テストでも、o3-miniを上回った。
- これらの結果から、Qwen3-235B-A22Bは、現在公開されているモデルの中で最も強力なものの一つとして位置づけられる。 ただし、TechCrunchの記事執筆時点では、この235Bモデルはまだ一般公開されていない可能性が示唆されている。
- 小型MoEモデル (Qwen3-30B-A3B):
- 活性化パラメータ数が10分の1であるにもかかわらず、Qwenの旧モデルであるQwQ-32Bを凌駕する性能を持つ。
- 小型Denseモデル (Qwen3-4B):
- 旧世代のQwen2.5-72B-Instructに匹敵する性能を持つとされている。
- 公開されている最大モデル (Qwen3-32B):
- DeepSeek R1と競合する性能を持ち、コーディングベンチマーク「LiveCodeBench」を含むいくつかのテストでOpenAIのo1モデルを上回っている。
- Qwen3 Baseモデル全般:
- モデルアーキテクチャの進化、トレーニングデータの増加、より効果的なトレーニング手法により、Qwen3のDense Baseモデルは、より多くのパラメータを持つQwen2.5 Baseモデルと同等以上の性能を達成している。 特にSTEM(科学・技術・工学・数学)、コーディング、推論の分野では、より大規模なQwen2.5モデルをも上回る場合がある。
- Qwen3のMoE Baseモデルは、活性化パラメータがわずか10%でありながら、Qwen2.5のDense Baseモデルと同等の性能を実現しており、トレーニングと推論の両方で大幅なコスト削減につながる。
これらの結果は、Qwen3がオープンソースおよびプロプライエタリなAIモデルの最前線に位置することを示しており、特にコーディングや推論能力において高い競争力を持っていることを裏付けている。
思考を操る「ハイブリッド思考モード」
Qwen3の最も注目すべき新機能の一つが、「ハイブリッド思考モード」である。 これは、ユーザーがモデルの思考プロセスを制御できる画期的なアプローチだ。
- Thinking Mode(思考モード): 複雑な問題に対して、モデルが段階的に推論を進め、最終的な回答を導き出す。深い思考が求められるタスクに適している。
- Non-Thinking Mode(非思考モード): 単純な質問に対して、迅速かつほぼ瞬時に応答する。速度が重視される場合に有効。
この2つのモードを切り替えることで、ユーザーはタスクの難易度に応じてモデルの「思考時間」(計算リソース)を調整できる。 例えば、難問には十分な推論時間を割り当て、簡単な質問には即座に答えるよう指示できる。
このハイブリッドアプローチは、OpenAIの「o」シリーズや、Google Gemini 2.5 Flashの「思考予算」の考え方に類似している。 Qwen3では、このモード統合により、安定かつ効率的な「思考バジェット制御」が可能になった。 割り当てられた計算推論バジェットに応じて、パフォーマンスがスケーラブルかつスムーズに向上することが示されており、ユーザーはコスト効率と推論品質の最適なバランスを容易に見つけることができる。
具体的な操作としては、Qwen ChatのWebサイトでは専用ボタンで切り替えが可能。 APIやローカル環境で利用する場合は、プロンプト内に/thinkや/no_thinkといった指示を追加することで、対話ターンごとにモードを動的に変更できる。モデルは複数ターンの対話において、最新の指示に従う。
119言語対応と強化されたエージェント機能
Qwen3は、多言語対応能力も大幅に強化された。インド・ヨーロッパ語族、シナ・チベット語族、アフロ・アジア語族、オーストロネシア語族、ドラヴィダ語族、チュルク語族、タイ・カダイ語族、ウラル語族、オーストロアジア語族など、世界の主要な言語ファミリーに属する119の言語と方言をサポートする。 これにより、国際的なアプリケーション開発の可能性が大きく広がり、世界中のユーザーがQwen3の恩恵を受けられるようになる。
さらに、Qwen3はコーディング能力とエージェント機能も最適化されている。 特にMCP(Multi-agent Collaboration Platform)のサポートが強化され、ツール呼び出し能力が向上した。 Alibabaは、Qwen3のエージェント能力を最大限に活用するために、「Qwen-Agent」ツールキットの使用を推奨している。 Qwen-Agentは、ツール呼び出しのテンプレートやパーサーを内部でカプセル化しており、複雑なコーディング作業を大幅に削減できる。
36兆トークン:大規模トレーニングの舞台裏
Qwen3の高性能を支えているのは、その大規模なトレーニングプロセスである。
- データ量: 前世代のQwen2.5が18兆トークンで事前学習されたのに対し、Qwen3は約2倍となる約36兆トークンものデータを使用している。 このデータは、前述の119言語・方言をカバーしている。
- データソース: Webからのクロールデータに加え、PDFのような文書からもデータを収集。文書からのテキスト抽出には「Qwen2.5-VL」が、抽出されたコンテンツの品質向上には「Qwen2.5」が活用された。 さらに、数学やコードデータの量を増やすため、「Qwen2.5-Math」と「Qwen2.5-Coder」を用いて、教科書、質疑応答ペア、コードスニペットなどの合成データも生成された。
- 事前学習プロセス(3段階):
- S1: 30兆トークン以上、コンテキスト長4Kで事前学習。基本的な言語スキルと一般知識を獲得。
- S2: STEM、コーディング、推論タスクなど、知識集約型データの比率を高めたデータセットで、さらに5兆トークンを追加学習。
- S3: 高品質な長文コンテキストデータを用いて、コンテキスト長を32Kトークンに拡張。
- ポストトレーニングプロセス(4段階): ハイブリッド思考モデルを開発するために、以下の4段階のトレーニングパイプラインが実装された。
- Long CoT Cold Start: 多様なタスク(数学、コーディング、論理推論、STEMなど)を含む長文の思考連鎖(Chain-of-Thought: CoT)データでファインチューニングし、基本的な推論能力を付与。
- Reasoning-based RL: 強化学習(RL)のための計算リソースをスケールアップし、ルールベースの報酬を用いてモデルの探索・活用能力を強化。
- Thinking Mode Fusion: ステージ2で強化された思考モデルが生成した長文CoTデータと、一般的な指示チューニングデータを組み合わせてファインチューニングし、思考能力と迅速な応答能力を融合。
- General RL: 20以上の汎用ドメインタスク(指示追従、フォーマット追従、エージェント能力など)で強化学習を適用し、モデルの汎用能力をさらに強化し、望ましくない挙動を修正。
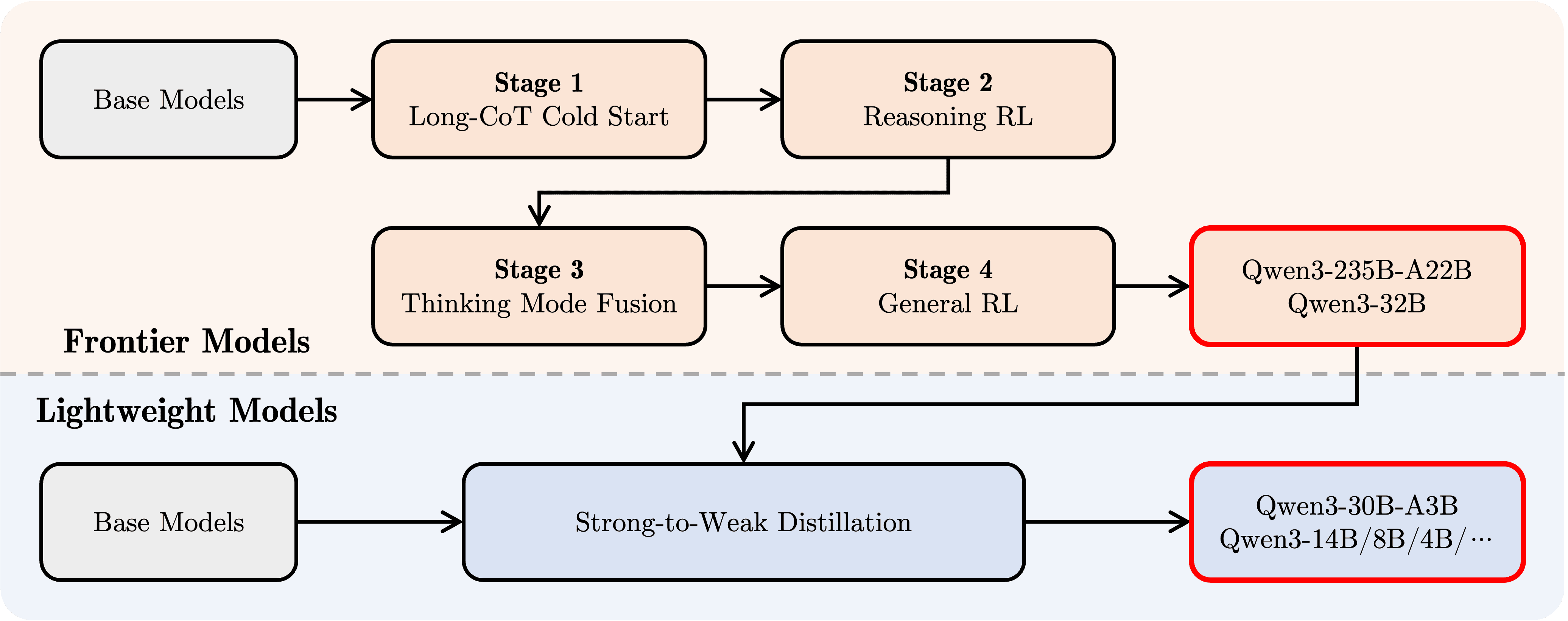
これらの綿密なトレーニングプロセスが、Qwen3の優れた性能と多様な能力の基盤となっている。
開発者向け:Qwen3の導入と活用
Qwen3は、様々なフレームワークやツールを通じて利用可能であり、開発者が容易に導入・活用できるよう配慮されている。
- 主要プラットフォーム: Hugging Face、ModelScope、Kaggle
- デプロイメント:
- SGLang (>=0.4.6.post1): OpenAI互換APIエンドポイントを作成可能。
- vLLM (>=0.8.4): 同様にOpenAI互換APIエンドポイントを作成可能。
- ローカル利用:
- Ollama: ollama run qwen3:30b-a3bのような簡単なコマンドで実行可能。
- LMStudio, MLX, llama.cpp, KTransformers: ローカル環境でのビルド・利用に対応。
- クラウドプロバイダー: Fireworks AI, Hyperbolicなどでも利用可能。
- コード例(Hugging Face Transformers): Alibabaは、Qwen3-30B-A3BモデルをHugging Face Transformersで利用するための基本的なPythonコード例を提供している。このコードでは、思考モード(enable_thinking=True/False)の切り替えや、出力から思考内容と最終回答を分離する方法が示されている。
- エージェント利用: 前述の通り、「Qwen-Agent」ツールキットが推奨されている。
これらの多様な選択肢により、研究、開発、本番環境など、様々なユースケースでQwen3を柔軟に組み込むことができる。
オープンソースAI競争の新局面と企業戦略への示唆
AlibabaによるQwen3の発表は、すでに熱を帯びているAI開発競争、特にオープンソース分野に新たな火種を投じたと言えるだろう。 この動きは、AI技術の進化の速さを示すと同時に、企業がAIを導入・活用する上で考慮すべき点を浮き彫りにしている。
加速する技術覇権争い:オープンソース vs. クローズド、米 vs. 中
Qwen3が示した高い性能は、OpenAI、Google、Meta、Anthropicといったプロプライエタリ(非公開)モデルを提供する欧米の巨人たちにとって、無視できない挑戦状だ。 同時に、DeepSeek、Tencent、ByteDanceなど、同じく高性能モデル開発にしのぎを削る中国企業との競争も一層激しさを増している。 この状況は、単なる企業間の競争を超え、オープンソース陣営とクローズド陣営、さらには米中間の技術覇権争いという、より複雑で多層的な競争構造が形成されつつあることを示している。
オープンソースの価値再認識:選択肢としてのリアリティ
高性能なオープンソースモデルの登場は、企業にとってAI戦略の選択肢を広げる大きなメリットとなるだろう。AIクラウドホストBasetenのCEO、Tuhin Srivastava氏が指摘するように、「Qwen3のような最先端のオープンモデルは、企業が自社のニーズに合わせてAIツールを内製する動きと、AnthropicやOpenAIのようなクローズドモデル企業から既製のソリューションを購入する動き、その両方が現実のものであることを反映している」。 つまり、企業はもはや単一のベンダーやアプローチに依存するのではなく、コスト、性能、カスタマイズ性、データ管理といった多角的な視点から、オープンソースとクローズドソースを戦略的に使い分ける、より洗練された段階へと移行しているのだ。
企業にもたらされる恩恵:コスト、スピード、そしてコントロール
Qwen3のような高性能オープンソースモデルは、企業に具体的なメリットをもたらす。
- コスト効率と性能の両立: プロプライエタリモデルに匹敵する性能を、潜在的により低いコストで利用できる可能性がある。特にMoEモデルは、少ない計算リソース(GPUメモリ)で高い推論能力を発揮するため、運用コストの削減に貢献しうる。
- 導入の迅速化: 既存のOpenAI互換APIインフラを活用できる場合が多く、モデルの切り替えや検証を比較的短期間で行える可能性がある。これは、変化の速い市場に対応するためのビジネスアジリティ向上に繋がる。
- カスタマイズと自律性の確保: Apache 2.0のような寛容なライセンスの下では、モデルを自社の特定ニーズに合わせて自由にファインチューニングできる。LoRAやQLoRAといった技術を使えば、機密データを外部に送信することなく、これを実現可能だ。オンプレミスでの運用を選択すれば、データの流れを完全に把握し、プロンプトや生成結果を管理・監査できるため、ガバナンス強化にも繋がる。
見過ごせないリスク:地政学、ガバナンス、そして倫理
一方で、特に中国製モデルの利用には慎重な検討が必要となる。
- 地政学的リスクとガバナンス: 米中間の技術摩擦が高まる中、中国ベンダー製のモデルを利用することには、輸出管理規制やデータプライバシーに関する潜在的なリスクが伴う。企業は、自社の事業展開地域や法的要件に照らし合わせ、これらのリスクを十分に評価する必要がある。
- コンテンツ制限と検閲: Qwen Chat Webサイトでは天安門事件に関する話題が制限されるなど、中国特有のコンテンツフィルターが存在する可能性がある。これは、自由な情報アクセスや表現の自由を重視する企業文化とは相容れない場合があり、利用目的に応じて注意が必要だ。
- セキュリティ: MoEアーキテクチャは攻撃対象領域を減らす可能性があるとはいえ、あらゆるAIモデルと同様に、セキュリティ脆弱性のリスクは常に存在する。適切なセキュリティ対策と継続的な監視が不可欠である。
未来へのシフト:モデルからエージェントへ
Qwenチームのメンバーが語るように、開発の焦点は、単に言語モデルの性能を高めることから、より複雑なタスクを自律的にこなせる「エージェント」の開発へと移りつつある。 強化学習のスケーリングや長期的な推論能力の向上といった課題への取り組みは、AIがより実世界の課題解決に貢献するための次なるステップを示唆している。
Qwen3の登場は、オープンソースAIがプロプライエタリモデルと互角以上に渡り合えるレベルに達したことを示す象徴的な出来事だ。 企業は、この技術的潮流を注意深く見極め、その恩恵を最大限に引き出しつつ、潜在的なリスクを管理する、賢明なAI戦略を策定していく必要があるだろう。
Sources
- Qwen: Qwen3: Think Deeper, Act Faster
- Hugging Face: Qwen/Qwen3-235B-A22B