
AI産業において「次に詰まる場所はどこか」という問いは、巨額の投資マネーの行き先を決める。Marvell TechnologyのCEOであるMatt Murphy氏が2026年6月のComputex台北で語ったのは、まさにその問いへの答えだった。「コンピュート、次にメモリ、そして今、ボトルネックはコネクティビティへと移行した」その発言に呼応するようにステージに上がったNVIDIAのJensen Huang氏が放った「次の兆ドル企業」という言葉が、市場に衝撃波を送った。
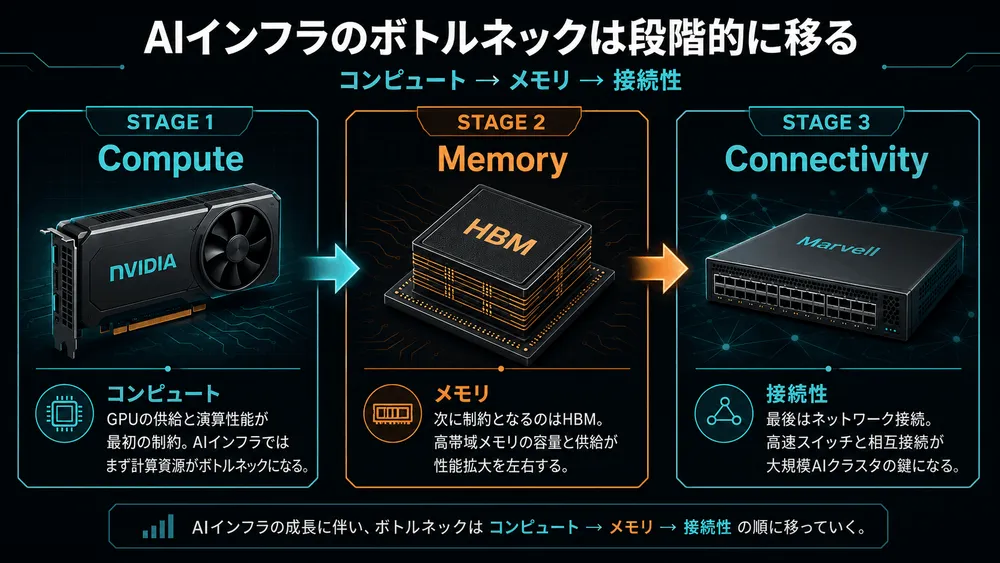
Computex 2026:AIインフラ論の転換点
2026年6月2日、Computexの基調講演でMurphyはAIインフラの進化を三段階の「ボトルネック解消史」として整理した。第一フェーズではコンピューティング能力が律速となり、NVIDIAがGPU供給の爆発的拡大でそれを解消した。第二フェーズでは大規模モデルの学習に必要なメモリ帯域幅が壁となり、HBMメーカーがこれに応えた。そして今、第三フェーズとして「接続性」が産業全体の成長を制約し始めているというのがMurphy氏の主張だ。
この主張は数字に裏付けられている。Marvellのデータセンター収益は直近四半期で18.3億ドルに達し、総収益の76%を占める。わずか数年前、同セグメントは全体の10%未満だった。この急成長は、ハイパースケーラーが汎用ハードウェアからAIワークロード最適化のカスタムシリコンへと投資軸を移した事実と重なる。
Huang氏はこの文脈を踏まえてMarvellを指名した。NVIDIAがMarvellに20億ドルを出資した3月の判断は、GPUとネットワーク機器の相互運用性を戦略的に確保するためだと説明されていた。しかし6月2日の「次の兆ドル企業」という宣言は、それがAI計算インフラにおける恒常的なパートナーシップであることを市場に向けて明示した。
Teralynx T100:「AIのために、AIだけのために」設計されたスイッチシリコン
Computexと同時期に、Marvellは業界初の102.4 Tbpsスイッチシリコン「Teralynx T100」の提供開始を発表した。この製品が既存の競合と一線を画す点は、従来のエンタープライズや汎用クラウド向けスイッチが引きずるレガシーアーキテクチャを設計段階から排除したことにある。
3nmプロセスを採用したモノリシック構造のT100は、競合比最大25%の消費電力削減を実現しつつ、102.4 Tbpsの帯域幅を提供する。AIデータセンターでは、ネットワーク機器がラック全体の消費電力の15〜25%を占めるという試算(SemiAnalysis)が示すように、消費電力の削減はGPUラックが120kWに迫る現在において経済的に直結する問題だ。
電力インフラの増強なしに、既存の電力エンベロープ内で稼働できるアクセラレータの数を増やせることは、データセンター事業者にとって直接的なコスト優位を意味する。
スケールアウト(分散学習クラスター)の観点では、T100は最大512ポートのラジックスをサポートし、数万台規模のアクセラレータを擁するクラスターのネットワーク階層を削減できる。スケールアップ(高帯域幅な密結合演算)の観点では、Ethernet Scale-Up Networking(ESUN)プロトコルや最新のUltra Ethernet Consortium(UEC)要件に対応し、柔軟なファブリック構成を提供する。
さらにBGA、銅コパッケージ(CPC)、光コパッケージ(CPO)の複数の実装形態を選択できる点も、ハイパースケーラーが求める調達柔軟性を満たす。Teralynxファミリーは12.8 Tbpsから102.4 Tbpsまでのレンジをカバーし、Open Compute Project(OCP)のSAI規格やSONiCオペレーティングシステムとのオープンエコシステム対応も維持している。
「銅の終わり」と、シリコンフォトニクスという次の賭け
T100の発表よりも長期的なインパクトを持つのが、Computexでのフォトニクスをめぐる議論だ。Murphy氏は「今後10年で、データセンター内の多くの銅配線は姿を消す」と断言した。物理的な理由は明快だ。高速シリアル通信では、銅ケーブルが信号を伝えられる距離は帯域幅に反比例する。現在の最高速インターコネクトは1レーン200Gbpsだが、その距離限界はわずか2.5メートルだ。NVIDIAが次世代Vera Rubin(NVSwitch)で400Gbpsへの倍増を予定しているが、それはすなわち銅の到達距離がさらに半減することを意味する。
光ファイバーは電気信号の代わりにフォトンを使うことで、このスケーリング上限を原理的に超える。帯域幅と伝送距離の間のトレードオフが消えることで、データセンターの設計思想そのものが変わりうる。今はXPU、メモリ、ストレージ、ネットワークカードを同一筐体に収める必要があるのは「距離の制約」が理由だ。光インターコネクトが普及すれば、これらのリソースを物理的に分離し、ワークロードに応じてオンデマンドで再構成する「完全分解型アーキテクチャ」が現実となる。
Marvellがこの方向にベットしてきた経緯は長い。2020年にOptoelectricalインターコネクトを専門とするInphi(約100億ドル)を買収し、その後Celestial AIのシリコンフォトニクス技術を数十億ドル規模で獲得した。NVIDIAによるMarvellへの20億ドル出資も、そのシリコンフォトニクス開発を加速する意図が含まれていると言及されている。
ただし、この移行は直線的ではない。Huang氏はComputexで「可能な限り銅を使い、やむを得ない場合に光を使う」と述べた。プラガブル光モジュールは障害率が高く電力消費も大きい。実際、NVIDIAがNVL72ラックを設計した際、光を使えばシステム消費電力がさらに20kWほど増加したことがプラグインオプティクス忌避の直接の理由だった。それでも業界が共有するコンセンサスは「フォトニクスへの移行は来る、ただし段階的に」というものだ。
Broadcomという巨人と、兆ドルへの距離
Marvellの台頭に最も敏感に反応するのは、時価総額がすでに2兆ドルを超えるBroadcomだ。GoogleやMetaを主要顧客に持つBroadcomも、コパッケージ光モジュール、高帯域プラガブル向けDSP、カスタムASICという重複する製品ラインナップを抱え、シリコンフォトニクス領域での競争を早期から準備してきた。
BroadcomのCEOであるHock Tan氏は「光学技術がいずれ銅に取って代わる時が来るとは見ているが、まだその時ではない」とアナリストに語り、プラガブルオプティクスが限界に達した時点でシリコンフォトニクスが解となるという段階論を維持している。両社がほぼ同じシナリオを描きながら、異なる時間軸と重心でポジショニングしているのが現状だ。
MarvellがNVIDIAエコシステムとの親和性を強みにするのに対し、BroadcomはGoogle TPUクラウドおよびMeta AI向けカスタムチップのリードサプライヤーとしての地位を保つ。この二極化が「AI半導体の接続性戦争」の実態であり、勝者を決めるのは市場の支持だけでなく、光インターコネクトの量産コスト低下がどの時間軸で実現するかにかかっている。
株価急騰の解剖:ガンマスクイーズと機関投資家の構造
MRVL株の価格動向は技術的議論と並行して語られるべきだ。6月2日の発表後、株価は1セッションで30%超上昇し、一時280ドル台の過去最高値を記録、時価総額は2,340億ドルに達した。6月上旬を通じて上昇が続き、40%超の騰勢で300ドルを突破する場面もあった。
上昇を加速させた要因の一つが、オプション市場での「ガンマスクイーズ」だ。コール買いが急増し、デルタヘッジのためにマーケットメーカーが現物を買い続ける自己強化的なサイクルが発動した。また、122〜200ドルのストライク帯に積み上がっていたプット(ショートポジション)がスクイーズされたことも価格上昇を底上げした。
株式の83.5%を機関投資家が保有するという構造は、急落に対する緩衝材となる一方、流通株式の希薄さがボラティリティを増幅させる。インサイダーの売却(直近3か月で3,200万ドル超)も報告されているが、いずれも10b5-1計画に基づく予約売却であり、裁量的な売り越しとは性格が異なる。
現在のMRVL株は、フォワードP/E比90倍超、PBR13倍という水準で取引されている。Barclays、Roth Capitalなどは目標株価を275〜300ドル帯に引き上げているが、この評価水準は「完璧な成長継続」を前提として織り込んでいる。直近では2028年度の売上高ガイダンスが165億ドルへ引き上げられ(従来比15億ドル増)、2029年度のカスタムチップ事業単独での100億ドル突破も宣言されている。市場がそこに乗るのは、それが達成可能であるとの判断ではなく、達成できなければ株価が調整するという前提での「信任投票」に近い。
AIインフラの主戦場が「接続」に移る意味
コンピューティング、メモリ、そして接続性。Murphy氏自身が提示したこのシーケンスには、普遍的な産業構造論的洞察がある。AIクラスターの性能はGPUの演算速度だけでは決まらない。GPU同士が「いかに速くデータをやりとりできるか」が実効スループットの上限を決める。これはAIトレーニングにおけるテールレイテンシーや収束時間に直接影響し、クラスター全体のGPU稼働率を左右する。
現状では、100ギガビット級Ethernet環境でもスイッチのホップ数が多く、遅延の累積がトレーニングの効率を損なうケースがある。Teralynx T100が狙うのはこのギャップの解消であり、スイッチ自体がAIワークロードのトラフィックパターンを「知っている」前提で設計されたAIネイティブなコンジェスチョン制御やテレメトリ機能が鍵となる。
光インターコネクトが普及した先では、今Googleが一部実現しているようなTPUトポロジーのオンデマンド再構成がより広い規模で可能となる。さらにその先には、CPUと加速器とメモリが物理的に分離された「分解型データセンター」というアーキテクチャが見えてくる。この実現は、Marvellが言うように「距離という制約の消滅」を意味し、クラウドインフラの設計から課金モデルまで影響を与えうる。
Huang氏の「次の兆ドル企業」という言葉は、現在の企業価値に対するコメントではなく、この技術軌道への確信を示したものと解釈するのが妥当だ。Marvellの時価総額が現状の2,340億ドルから1兆ドルに達するには約4倍の成長が必要だが、Micronが達成したHBM需要の波と同様の強度でコネクティビティ需要が爆発するならば、その試算は突飛ではない。ただし、Broadcomの強固な顧客基盤、光インターコネクトの量産コストの不確実性、そしてプレミアム評価への実行リスクが、その道のりを平坦なものにはしない。


