過去数年間、人工知能の進化を牽引してきたのは、圧倒的な計算資源とデータ量による腕力勝負の歴史である。数百、数千億というパラメータを持つ巨大な一枚岩のモデルを構築しさえすれば、世界中のあらゆる複雑な問題が解決できるという無邪気な信仰が業界を支配してきた。しかし、現実世界の泥臭い現場は、万能を謳う単一のアルゴリズムには到底収まりきらない。未知のバグが潜む数万行のコードベースの修正、前例のない新素材の分子設計、あるいは複雑に絡み合う特許文献の網羅的な読み解き。これら多段階にわたる厄介な課題は、プロンプトを一度投げるだけで完璧な解答が返ってくるような性質のものではない。
事態をさらに複雑にしているのが、一部の巨大テック企業による技術の寡占と、それに伴う地政学的な断絶である。2026年に入り、Anthropicの最先端モデル「Fable 5」および「Mythos Preview」に対して輸出規制が発動された。この出来事は、国家や企業が重要インフラの知能を単一ベンダーのAPIに依存することの致命的な脆弱性を露呈させた。規制の枠組みが変われば、昨日まで使えていた最高峰の計算能力が、一夜にして引き剥がされる。スケーリング則の物理的限界が見え隠れし、技術覇権をめぐる分断が深まる現在、私たちはどのようにして最先端の知能を維持し、実用的なワークフローに統合していくべきか。
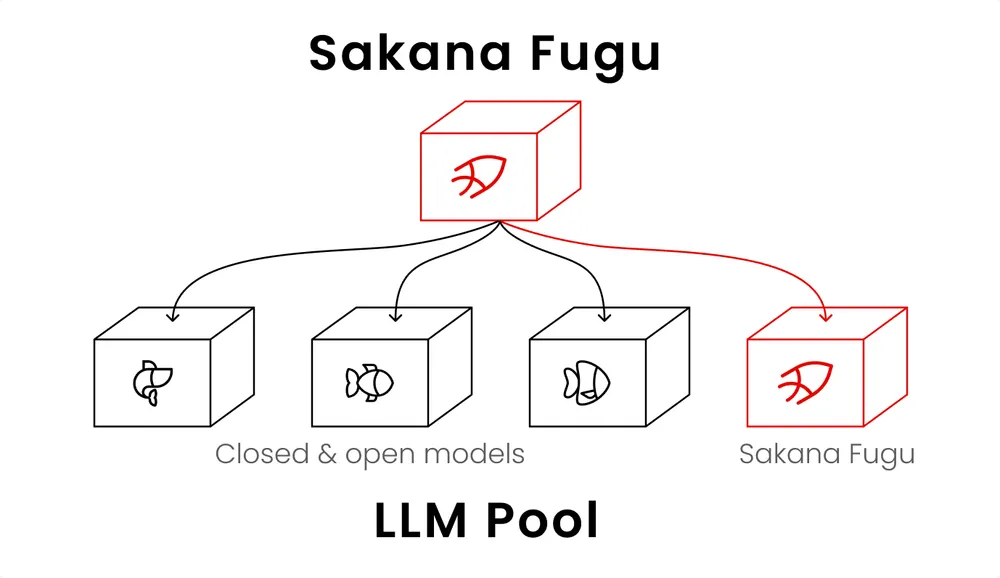
この重厚な問いに対し、東京に拠点を置く気鋭のAI企業Sakana AIが、極めて洗練された解答を突きつけた。2026年6月22日、同社が正式リリースした新製品「Sakana Fugu(以下、Fugu)」である。これは単一の巨大モデルではない。複数の専門的なAIを背後で自在に操る「指揮者」を、たった一つのOpenAI互換APIに凝縮した、まったく新しい概念の知能エコシステムだ。
力技の時代の終焉と、地政学リスクが突きつける「AI主権」の危機
これまでのAI産業は、より大きな脳を作ることに血道を上げてきた。しかし、進化の歴史を振り返れば、最強の生物は必ずしも最大の体躯を持っていたわけではない。過酷な環境を生き延びたのは、限られた資源の中で群れを作り、高度なコミュニケーションによって外敵を退けた種族である。Fuguの設計思想の根底には、この「集合知の協調」という概念が流れている。
Anthropicのモデルに対する輸出規制が示したのは、単一の高性能プロバイダーへの盲信が事業の根幹を揺るがすという厳しい現実である。特定の企業のサーバーに自社の命運を預ける構造は、サプライチェーンにおける単一障害点(SPOF)に他ならない。Fuguは、この地政学的なリスクに対する堅牢な防波堤となる。システムは、背後に控える無数の専門モデル(エージェントプール)の中から、タスクに応じて最適なものを動的に選択する。仮にある日突然、主力として頼っていた海外プロバイダーのアクセスが遮断されたとしても、Fuguは即座に別のモデル群へと経路を切り替え、作業を継続する。ユーザー側でコードを書き直す手間は一切発生しない。世界中のモデルを柔軟に入れ替えながら最良の結果を引き出すこのアプローチは、国家や企業が自らのコントロール下に知能を置く「AI主権(AI Sovereignty)」を確立するための現実的な青写真である。
専門家集団を束ねる天才指揮者。学習済みオーケストレーションの衝撃
Fuguが提供するユーザー体験は驚くほどシンプルだ。開発者はこれまで通り、一つのAPIエンドポイントに向かってプロンプトを投げるだけでよい。複雑なルーティングの仕組みや、モデル間の対話プロトコルをコードに書き込む必要はない。
しかし、APIという「受付」の奥では、極めて高度なカンファレンスが繰り広げられている。Fugu自身が、いつ処理を委譲すべきか、どのエージェント同士を対話させるべきか、そして最終的な成果をどうやって一つの信頼できる答えにまとめ上げるかを自律的に判断する。人間が事前に「このタスクはモデルAに任せ、結果をモデルBにチェックさせる」といった静的なルール(ワークフロー)を記述するのではない。
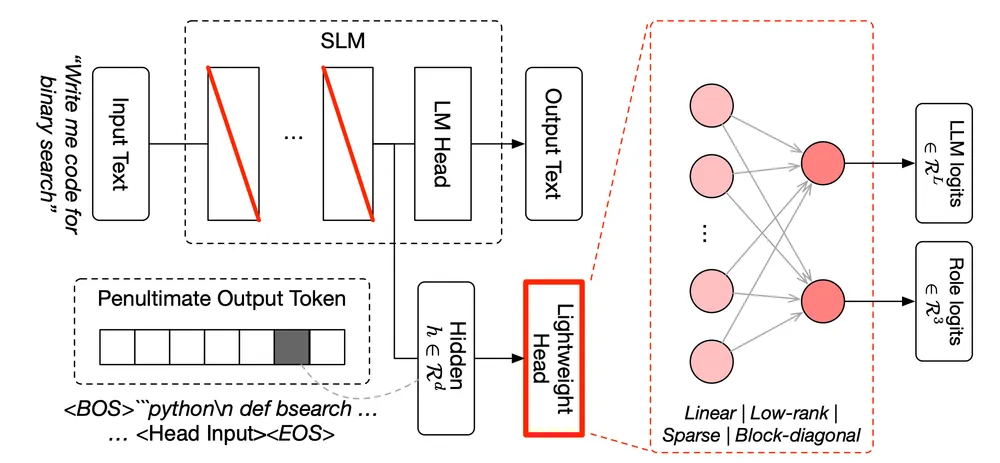
この動的な連携を可能にしているのが、Sakana AIがICLR 2026で発表した2つの重要な研究論文、「TRINITY」と「Conductor」である。TRINITYは、複数のLLMに対して「Thinker(思考役)」「Worker(実行役)」「Verifier(検証役)」といった役割を適応的に割り振る軽量な進化型コーディネーターだ。一方のConductorは、強化学習を用いて自然言語ベースの協調戦略を自ら発見するシステムである。総合病院の受付で症状を伝えると、院内のシステムが瞬時に内科医、外科医、放射線技師を招集し、カンファレンスを開いて確定診断を下すような流麗な連携が、ミリ秒単位の計算空間で完結する。
ベンチマークを粉砕する「集合知」。フロンティアモデルとの真剣勝負
Fuguのラインナップは、ワークロードの性質に合わせて2つのモデルが用意されている。日常的なコーディングや応答速度が求められるチャットボット向けに性能とレイテンシのバランスを取った「Fugu」と、難解で多段階の推論において回答の深さと正確性を極限まで追求する「Fugu Ultra」である。
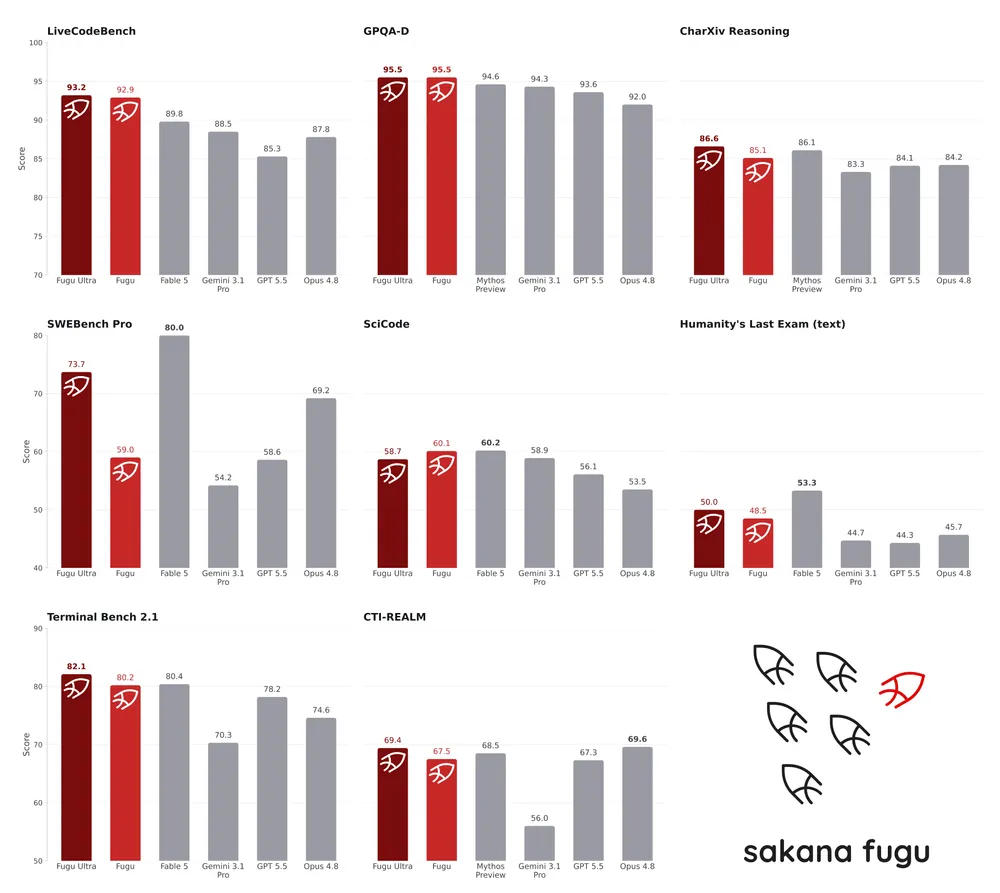
とりわけFugu Ultraのベンチマークスコアは、既存のフロンティアモデルの到達点をあっさりと塗り替えている。実際のソフトウェア開発のイシューを解決する能力を測り、AIの真の実力が如実に表れる「SWE Bench Pro」において、Fugu Ultraは驚異の73.7を叩き出した。業界を牽引してきたAnthropicの「Opus 4.8」が69.2にとどまる中、70の壁を軽々と突破した意味は重い。さらに、プログラミング能力を厳密に評価する「LiveCodeBench」では93.2、長期的な推論力が問われる「CharXiv Reasoning」でも86.6を記録し、並み居る競合を軒並み沈黙させている。
実世界の泥臭いワークフローで真価を問う
無味乾燥な数字の羅列以上に、Fuguの真価は実世界の長く入り組んだタスクで発揮される。単一のプロンプトに対する一問一答の枠を超え、自律的なエージェントとしての振る舞いにおいて競合との差は決定的となる。
たとえば、自動化されたAI研究フレームワーク「AutoResearch」を用いた実験では、Fugu Ultraを与えられたエージェントが、小規模なGPTモデルの学習レシピを自律的に改善し続けた。H100 GPUを1基使用し、およそ14時間にわたって123回もの実験コードの書き換え、実行、検証を繰り返した結果、バッチサイズや学習率、オプティマイザの設定を自ら最適化し、検証用bits-per-byte(BPB)で0.9774という極めて優れた平均値を達成した。これは、競合の最新モデル群が到達できなかった領域を、人間の介入なしに切り拓いた証拠だ。
また、1610年に芳春院が記した「仮名消息(かな書状)」の読み順推定という特異なタスクでも、Fugu Ultraは特筆すべき知性を発揮した。専門家でさえ解読が困難な「散らし書き」のレイアウトに対し、他のフロンティアモデルが専門家の正解順序(NEDスコア1.0)に対して0.24という低い一致率で紙面上を迷走したのに対し、Fugu Ultraは0.80という高い精度で正しい読み順の経路をなぞり切った。
純粋なPythonのみでルービックキューブの解法コードを生成させるタスクでは、他モデルが実行時にクラッシュするコードを吐き出す中、Fugu Ultraは300個のテストケース全てをバグなしで走らせ、平均19.72手という最適解の水準で解き切るソルバーを完成させている。
限界なき自律実行。先行ユーザーが目撃した実務への破壊的インパクト
実験室のテストケースを離れ、実際にFuguを日常業務に組み込んだ500名近いベータテスターの報告は、さらに生々しい衝撃を与えてくれる。ゴールだけを与えられたエージェントが、数時間から数日にわたって自律的に作業を継続する能力は、これまでのAIツールとは一線を画している。
特筆すべきは、サイバーセキュリティ分野での実証結果だ。あるセキュリティエンジニアがFugu Ultraに対して「特定のスコープ内での脆弱性評価」を指示したところ、システムは事前の情報収集(Recon)から始まり、クロスサイトスクリプティング(XSS)やSQLインジェクションの網羅的な検査、認証メカニズムのレビューを自律的に遂行した。さらに重要なのは、システムを破壊するような危険な操作を自ら回避し、最終的にはエビデンスと再テスト手順を完備した完璧な監査レポートを提出したことだ。
また、アカデミアや研究開発の最前線においても、既存のワークフローを根底から覆している。ある研究者は、AI論文の再現タスクにおいて、Fuguが約4時間にわたって完全に自律稼働したことを報告している。論文の読解からコードの実装、モデルの学習、評価、そして失敗要因の分析に至るまでを単独でこなし、CUDA関連の最適化タスクでは1回のセッションで100倍以上の実行速度向上を達成したという。特許調査においては、通常であれば人間のリサーチャーが3〜4日を要する約20本の論文と関連特許のパテントランドスケープ作成をわずか数時間で完了させ、人間では到底気づけないような技術間の隠れた文脈の繋がりまで提示してのけた。
エンタープライズのプラットフォーム開発を担う経営層は、Fuguの「ペルソナの安定性」を高く評価している。他の最先端モデルでは、長時間のセッションや複雑な指示の往復が続くと、次第にロールプレイの指示を忘れ、出力のトーンや振る舞いが崩壊していく「ドリフト現象」が避けられなかった。しかしFuguは、裏側で複数のモデルが動的に切り替わっているにもかかわらず、ユーザーからは一貫した高度な専門家としての振る舞いを崩さなかった。これは、製品としてエージェントを組み込む企業にとって、ベンチマークのわずかなスコア差を遥かに凌駕する極めて重大な付加価値となる。
ベンダーロックインを破壊する料金体系とエコシステム
どれほど優れた知能であっても、導入コストが非現実的であれば市場には浸透しない。Sakana AIは、APIの裏側で複数のモデルを稼働させるという特性上、利用料金が際限なく膨れ上がるのではないかというユーザーの懸念に対し、極めてフェアな回答を用意している。
Fuguの従量課金プランでは、複数のエージェントがカンファレンスを行ってタスクを解決した場合でも、各モデルの料金が合算(スタック)されることはない。関与したモデルの中で「最も上位の層に位置するモデル」の単一レートのみが適用される。これは、一流の総合病院で複数の専門医の診察を受けても、最終的な請求は主治医一人の診察料しか発生しないような画期的なシステムだ。
| モデル・プラン | 対象ユーザー / ワークロード | 料金・スペック詳細 |
|---|---|---|
| Fugu (従量課金) | 高負荷・本番環境向け(カスタムエージェント構成) | 背後で稼働した最上位モデルの標準レートのみ課金(スタックなし) |
| Fugu Ultra (従量課金) | 究極の回答品質を求めるエンタープライズ | 1Mトークンあたり:入力 $5 / 出力 $30 / キャッシュ入力 $0.50 |
| (※272Kコンテキスト超は 入力 $10 / 出力 $45 / キャッシュ $1.00) | ||
| Standard (サブスク) | 個人の日常的なコーディング、小規模な実験 | $20 / 月 |
| Pro (サブスク) | 定期的な研究、長文のコードレビュー | $100 / 月 (Standardの10倍の利用枠) |
| Max (サブスク) | 長時間の高負荷タスクを回すパワーユーザー | $200 / 月 (Standardの20倍の利用枠) |
なお、すべてのサブスクリプションプランでFuguとFugu Ultraの両方にアクセスでき、2026年7月末までに登録すれば、初回のサブスクリプション階層において2ヶ月目が無料となるキャンペーンも展開されている。また、データやプライバシーの要件が厳しい組織向けに、Fuguモデルでは特定のエージェントを稼働プールから除外(オプトアウト)する機能も備わっている。
誰もが最先端の知能を「手放さない」未来へ
Sakana Fuguの登場は、ただの「新しいAIモデルの発表」という文脈には収まらない。それは、単一の企業が提供する巨大な脳髄に世界中が依存する歪な構造への、鮮やかなカウンターパンチである。
今後、新しいオープンモデルやさらに強力な基盤モデルが登場すれば、それらはシームレスにFuguのエージェントプールへと組み込まれていく。ユーザー側はコードを一行も書き換えることなく、その恩恵を即座に享受できる。自律的に群れを成し、互いの弱点を補いながら進化し続けるオーケストレーションの生態系。AI主権を取り戻すためのこの構造的なパラダイムシフトは、いま、たった一つのAPIを通じて世界中の開発者の手に委ねられた。