
人工知能の発展は、モデルの規模拡大とコンテキストウィンドウの長大化という果てしない拡張の道を歩んでいる。数百万トークンもの情報を一度に処理する能力は、複雑な文書解析や高度な文脈理解を可能にする一方で、ハードウェアの物理的なメモリ容量という強固な壁に衝突している。この根源的な制約に対し、Google Researchは「TurboQuant」と呼ばれる画期的なベクトル量子化アルゴリズムを発表した。これは、既存のデータ圧縮手法が抱えていた理論的・構造的な限界を突破し、AIモデルのメモリ消費量を劇的に削減しながら精度の低下を一切防ぐという、次世代の推論インフラストラクチャを形作る技術である。
大規模言語モデルの「記憶領域」を圧迫するKVキャッシュの物理的制約
Transformerアーキテクチャを採用する最新の大規模言語モデルにおいて、計算効率を維持するための生命線となるのがKVキャッシュ(Key-Value Cache)だ。モデルが文章を生成する過程において、過去に処理したトークンの情報を毎回最初から計算し直すのは非効率極まりない。そこで、計算済みの情報を高次元ベクトルとして一時的に保持し、必要な時に即座に参照する仕組みが採用されている。これは、巨大な作業机の上に過去の記憶を記した無数の付箋を貼り付け、すぐに読み取れる状態にしておくことに似ている。
しかし、この仕組みは入力される文脈が長くなるにつれて深刻な問題を引き起こす。書籍一冊分や長時間の会議録といった膨大なデータを入力すると、KVキャッシュのデータ量は線形に爆発し、GPUの限られたVRAM(ビデオメモリ)を即座に埋め尽くしてしまうのだ。メモリが枯渇すれば、演算ユニットがどれほど高速であってもデータの読み書き待ちが発生し、全体の推論速度は急激に落ち込む。ハードウェアの増設には莫大なコストがかかるため、ソフトウェア層での抜本的なデータ圧縮が急務となっていた。
既存のベクトル量子化が直面していた「メモリオーバーヘッド」のジレンマ
高次元ベクトルを圧縮する手法として、連続的で精緻な数値を限られた離散的な値(例えば整数)のセットにマッピングするベクトル量子化が広く用いられてきた。無限に存在するグラデーションの色合いを、少数の基本色のパレットに近似して記録するような手法である。これによりメモリ使用量は大幅に減るが、元の情報を可能な限り正確に復元するためには、細かいデータブロックごとに「量子化定数」と呼ばれる補正用のパラメータを高精度な浮動小数点数で保存しておかなければならない。
この量子化定数の保存こそが、極限の圧縮を目指す上での最大の障壁であった。システム全体で見ると、この付加データは1つの数値あたり1から2ビットのメモリオーバーヘッドを生み出す。32ビットのデータを16ビットにする程度であれば目立たないが、メモリ効率を極大化するために2ビットや3ビットへの圧縮を試みる場合、このオーバーヘッドは圧縮の恩恵を大きく食いつぶしてしまう。さらに、入力データの分布を事前に分析して量子化の境界を最適化するデータ依存型のアプローチは、リアルタイムで生成されるKVキャッシュの動的な処理には計算負荷が高すぎた。
TurboQuantの第一の柱「PolarQuant」による空間の変容と最適化
この膠着状態を打破するために、Google Researchの開発チームは「PolarQuant」と呼ばれる革新的な概念をTurboQuantに組み込んだ。従来の量子化器がデカルト座標系(X軸、Y軸、Z軸といった直線的な軸)でデータを独立して処理していたのに対し、PolarQuantはデータの捉え方を根本から変え、極座標系へと変換する。X軸やY軸といった直線的な位置情報で示される直交する座標のペアを、中心からの距離(半径)と向いている方向(角度)という情報の組み合わせへとマッピングし直すのである。
さらに重要なのが、この変換に先立って行われるランダムな回転行列の適用である。複雑に偏った高次元の入力ベクトルに対して無作為な回転を加えると、データ空間全体が一様に混ざり合い、中心極限定理や測度の集中といった数学的性質によって、各座標のデータの散らばり具合が完全に予測可能なベータ分布や正規分布へと収束していく。これは、歪な形をした粘土を回転させながら完全な球体へと成形していくプロセスに例えられる。データの分布が事前に予測可能になることで、システムはデータを読み込むたびに動的な正規化を行う必要がなくなり、固定された量子化境界をそのまま適用できるようになる。結果として、ブロックごとの量子化定数を保存するオーバーヘッドは完全に消滅する。
QJL変換がもたらす「1ビットの魔法」とバイアスの完全な排除
PolarQuantのアプローチにより、平均二乗誤差(MSE)を最小化する極めて効率的な圧縮が達成される。しかし、大規模言語モデルの推論における文脈理解の中核を担うアテンション・メカニズムは、ベクトル同士の類似度を測る「内積」の計算によって成立している。単にMSEを最適化するだけの量子化では、低ビットレート環境下において内積の推定値に偏り(バイアス)が生じ、アテンションの精度を狂わせてしまうという物理的性質がある。
この緻密な計算の狂いを修正するため、TurboQuantは二段階目の処理としてQJL(Quantized Johnson-Lindenstrauss)変換を導入した。第一段階の圧縮で生じた元のベクトルと再構築されたベクトルのわずかな差分(残差)に対し、次元削減に関する強固な数学の定理であるJohnson-Lindenstraussの補題に基づく乱択化アルゴリズムを適用する。これにより、複雑な残差情報を「+1」または「-1」というわずか1つのサインビットに極限まで凝縮するのだ。計算の実行時には、高精度なクエリベクトルとこの1ビットの残差情報を掛け合わせることで、驚くべきことに内積計算のバイアスが数学的に完全に相殺される。メモリを事実上全く消費しないこの1ビットの魔法が、量子化による情報の欠落を補い、非圧縮時と変わらない精緻なアテンションスコアを導き出す。
Claude Shannonの情報理論に裏打ちされた数学的証明
現代のAI研究においては、試行錯誤に基づく経験則によって設計されたアルゴリズムが主流となることも多い。しかし、TurboQuantの真の価値は、その性能が揺るぎない情報理論の基礎の上に構築されている点にある。情報の圧縮において、一定のデータ量で表現できる正確さには、Claude Shannonによって確立された「Shannonの歪みレート関数」と呼ばれる数学的な絶対下限が存在する。
研究チームは論文内において、TurboQuantの生み出す歪みがこの理論的下限に対し、あらゆるビット幅において約2.7倍という極めて小さな定数係数の範囲内に収まることを厳格に証明している。これは、アルゴリズムが物理的・数学的な限界点に肉薄していることを示している。特定のデータセットに合わせてパラメータを調整するデータキャリブレーションを一切必要とせず、あらゆる未知のデータに対して即座に最適に機能するデータ非依存(Data-oblivious)の特性を持ちながら、この理論的最適性を実現したことは、計算機科学における一つの到達点である。
過酷なベンチマークが証明する「精度損失ゼロ」と驚異的な高速化
理論上の洗練度は、実際の稼働環境を模した過酷なベンチマークテストにおいても実証されている。Google Researchは、GemmaやMistral、Llama-3.1-8B-Instructといった最先端のオープンソースモデルを使用し、LongBenchやZeroSCROLLS、RULERなどの長文脈評価タスクでTurboQuantの性能を計測した。
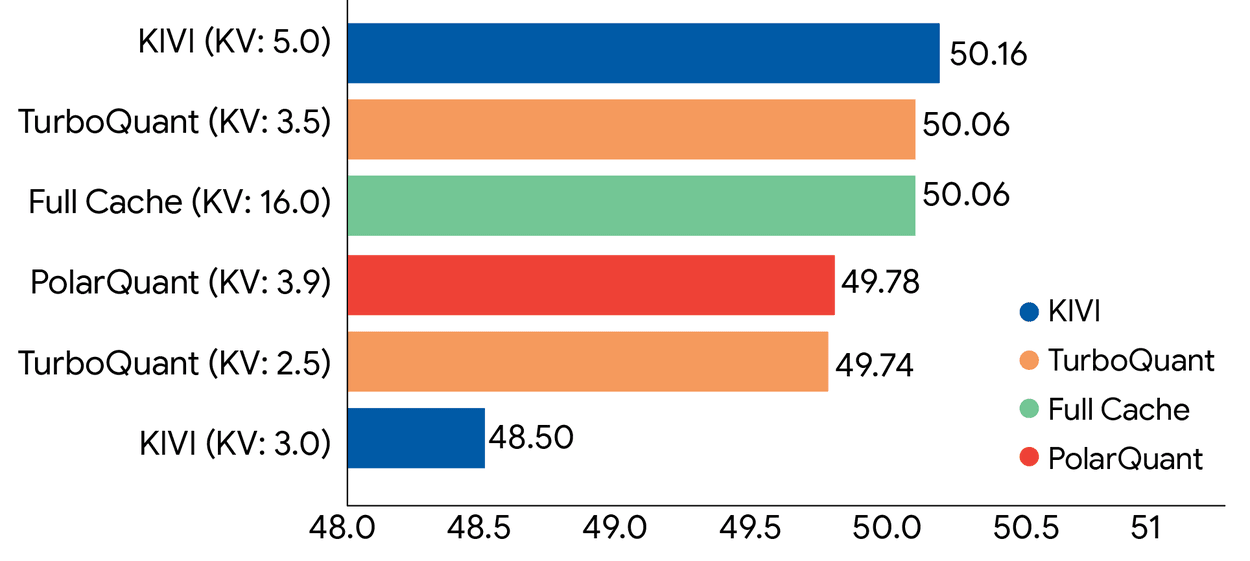
その結果、KVキャッシュをチャネルあたり実質2.5から3.5ビットにまで圧縮し、メモリ使用量を未圧縮時の6分の1以下に削減した状態であっても、複雑な質疑応答やコード生成において精度低下は一切観測されなかった。数万トークンの文章群に隠された特定の短い一文を抽出する「Needle-In-A-Haystack」テストにおいても、情報の取りこぼしは生じていない。さらに、NVIDIA H100 GPUを用いた検証では、4ビット圧縮されたTurboQuantは、32ビットの非量子化キーと比較してアテンションロジットの計算を最大8倍まで高速化することに成功した。メモリ転送のボトルネックが解消されたことで、計算ユニットの真のポテンシャルが解放されたのである。
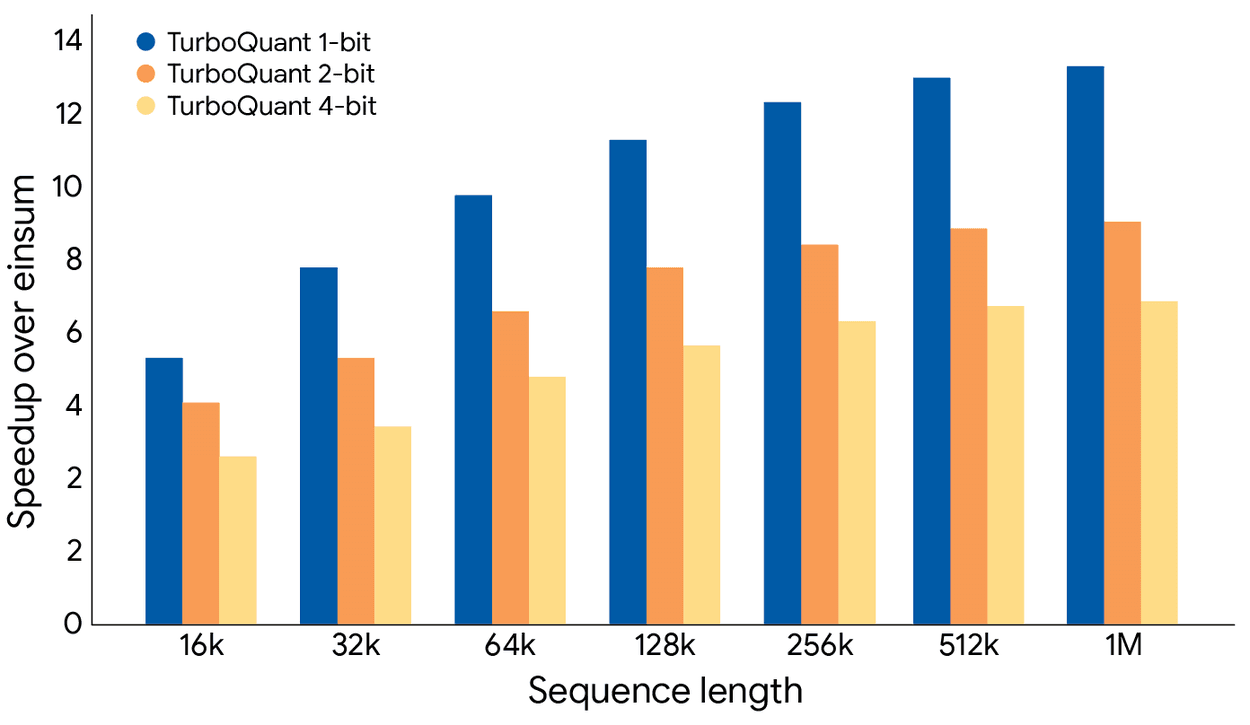
巨大なベクトル検索エンジンのインデックス構築を再定義する
この技術の恩恵は、LLMの生成プロセスに留まらず、RAG(検索拡張生成)や意味検索の基盤となる高次元ベクトル検索データベースにも及ぶ。数十億件のデータを瞬時に検索する最新のシステムでは、Product Quantization(PQ)などの手法が標準的に利用されてきた。しかし、PQはデータを分割して各クラスタの代表点をまとめた巨大なコードブックをメモリ内に保持する必要があり、データの読み込み時に多大な時間をかけてインデックスを構築しなければならない。
TurboQuantは、このインデックス構築の概念自体を陳腐化させる。データ非依存で即座に圧縮を実行できるため、事前のクラスタリング計算やコードブックの生成といった前処理にかかる時間が実質ゼロになるのだ。1536次元や3072次元といった巨大なベクトルを扱うDBpediaのエントリを利用した比較検証においても、TurboQuantは既存のPQや最新の手法であるRabitQを、検索精度の指標である「1@kリコール率」において一貫して凌駕した。
計算資源の制約から解き放たれる次世代AIインフラストラクチャ
AIのモデル規模が指数関数的に増大していく中で、計算資源とメモリの効率的な運用は、企業や研究機関にとって技術進化を継続するための生命線となっている。TurboQuantは、ランダム回転による空間の均一化と、1ビットの残差補正によるバイアスの排除という2つのアプローチを融合させ、ベクトル量子化の限界を再定義した。
モデルの再学習を一切伴わずに稼働中のシステムへ即座に統合できるこのアルゴリズムは、クラウド環境に構築された巨大な推論クラスタや、端末側で処理を行うエッジデバイスも含め、あらゆるAI実行環境の標準を塗り替える可能性を秘めている。ハードウェア投資の限界を超えて、より高度で大規模な文脈推論を民主化するこの数学的ブレイクスルーは、知能システムの発展において確かな足跡を残すに違いない。
論文
参考文献
- Google Research: TurboQuant: Redefining AI efficiency with extreme compression