大規模言語モデル(LLM)が、SFの世界を現実のものにしようとしている。最新の研究で、ChatGPTのようなAIが宇宙船を驚くほど巧みに操縦できる可能性が示されたのだ。これは、通信の遅延が大きな壁となる深宇宙探探査のあり方を根本から覆す、まさにゲームチェンジャーとなりうる技術かもしれない。しかし、その輝かしい未来像の裏には、乗り越えるべき課題も存在する。言語を操るAIは、物理世界をも支配できるのだろうか?
宇宙開発の「古くて新しい」壁:自律化への渇望
人類の活動領域が宇宙へと広がるにつれ、我々は二つの大きな課題に直面している。一つは、地球低軌道にひしめく人工衛星の数だ。その数はもはや人間が手動で全てを管理できる限界をとうに超えている。そしてもう一つが、火星やさらにその先を目指す深宇宙探査における、光速の壁だ。
地球と火星の通信には、片道で数分から20分以上かかる。これは、探査機にトラブルが発生しても、地球からリアルタイムで指示を送って対処することが不可能であることを意味する。もし本当に人類が宇宙へ進出していくのであれば、ロボット、すなわち宇宙船自身が状況を判断し、自ら意思決定を行う「自律性」を獲得することが不可欠となる。
これまで、宇宙船の自律制御は、物理法則に基づく厳密な数式を用いるPID制御やモデル予測制御といった「古典的制御理論」や、膨大なシミュレーションを通じて最適な行動を学習する「強化学習(RL)」が主流だった。しかし、これらのアプローチには限界もあった。古典制御は想定内の状況には強いが、未知の事態への柔軟な対応が難しい。一方の強化学習は、学習に膨大な量のデータと計算リソースを必要とし、特に宇宙分野ではリアルなシミュレーション環境を準備すること自体が大きなハードルとなっていた。
ゲームが拓いたAI研究の新たな地平:Kerbal Space Program
この膠着状態を打破する鍵は、意外なところにあった。メキシコのスタジオSquadが開発した宇宙開発シミュレーションゲーム「Kerbal Space Program(KSP)」だ。
KSPは、プレイヤーが自らの手でロケットや宇宙船を設計・組み立て、カーバルという可愛らしい宇宙飛行士たちを宇宙の様々なミッションへと送り出すゲームだ。大気圏からの脱出、別の惑星への到達、宇宙物体の迎撃といった多様なミッションを体験できる。特にその軌道力学の正確性は目を見張るものがあり、NASAがKSPと提携し、小惑星リダイレクトミッション(Asteroid Redirect Mission)のシミュレーションに利用したという実績は、その科学的信頼性の高さを裏付けている。単なるゲームの域を超え、航空宇宙工学の教育や研究のツールとしても活用されてきた。
今回、マサチューセッツ工科大学(MIT)とマドリード工科大学の研究者チームが舞台に選んだのは、このKSPをベースにした公開ソフトウェア競技会「Kerbal Space Program Differential Game Challenge(KSPDG)」だった。このチャレンジは、衛星の追跡・迎撃や、探知からの回避といった、協力関係にない宇宙機同士の駆け引きをシミュレートするもので、AIエージェントの「真の実力」を試すための、いわば究極の遊び場だ。
研究チームは、強化学習の限界を認識した上で、全く新しいアプローチを試みた。それが、ChatGPTやLlamaに代表される大規模言語モデル(LLM)の活用である。彼らの仮説はこうだ。「LLMは、インターネット上の膨大なテキストデータから人間の言語、論理、そしてある種の常識まで学習している。この事前知識を活かせば、強化学習のようにゼロから膨大な試行錯誤を繰り返すことなく、少ない学習で複雑なタスクをこなせるのではないか?」
「言葉」で宇宙船を動かす、その驚くべき仕組み
一見すると、言語を扱うモデルが、精密な物理計算を要する宇宙船の操縦を行うというのは、魔法のように聞こえるかもしれない。しかし、研究論文「Large Language Models as Autonomous Spacecraft Operators in Kerbal Space Program」を紐解くと、その裏には極めて巧妙な技術的アプローチが存在することがわかる。
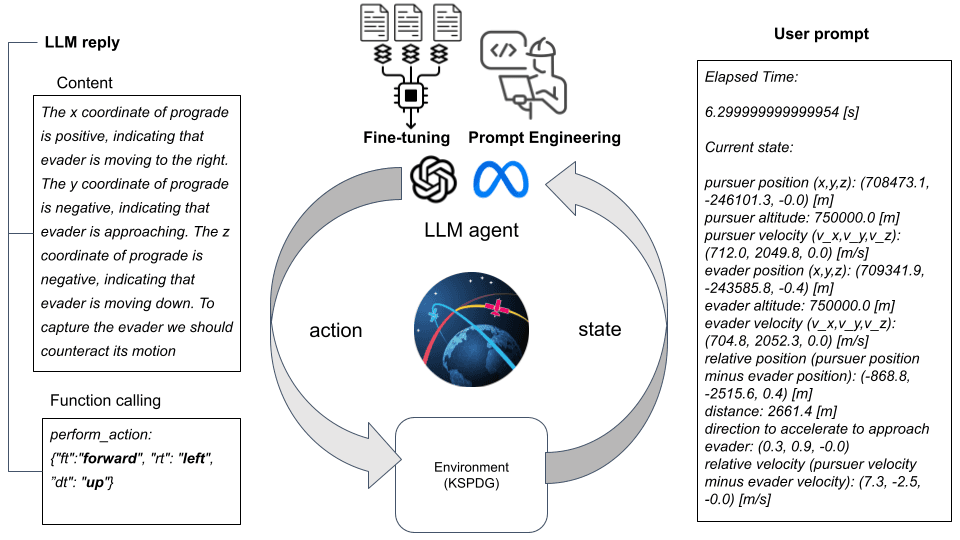
宇宙船の「状態」を言葉に変換する
この技術の核心は、宇宙船が置かれている物理的な状況(位置、速度、姿勢など)を、LLMが理解できる自然言語のテキストに変換するというアイデアにある。
例えば、「追跡対象との相対位置はX方向に-868.8m、Y方向に-2515.6m…」といった生の数値データを、LLMに対して「あなたは追跡宇宙船を制御する自律エージェントです。目標は敵機を捕獲すること。現在の状況は以下の通りです…」という形式のプロンプト(指示文)に変換して入力する。これにより、LLMはまるで人間のオペレーターのように、ミッションの文脈を理解することができるのだ。
AIに「考えさせる」技術:Chain of Thought(思考の連鎖)
さらに研究チームは、「Chain of Thought(CoT)」という手法を用いることで、LLMの推論能力を最大限に引き出した。これは、単に最終的な答えを出させるのではなく、「なぜその結論に至ったのか」という思考のプロセスを段階的に記述させるテクニックだ。
論文に示された例では、LLMはまず以下のように推論する。
「プログレード(進行方向)ベクトルのx座標は正であり、敵機は右に移動している。y座標は負であり、敵機は接近している…。敵機を捕獲するためには、この動きを打ち消す必要がある。つまり、左へ、前へ、そして上へ移動すべきだ」
このようなステップ・バイ・ステップの推論を経ることで、LLMはより正確で論理的な判断を下すことができる。この「一呼吸置かせる」指示だけで、AIの推論能力は劇的に向上する。論文によれば、CoTを導入したGPTモデルは、ミッションの失敗率が37.5%から0.00%へと劇的に改善した。AIが自身の思考プロセスを言語化することで、より複雑で論理的な判断が可能になることを示唆する、驚くべき結果だ。
AIの「思考」を「行動」に変える
そして最後に、LLMが導き出した「左へ、前へ、上へ」というテキストベースの結論を、宇宙船のスラスターを実際に噴射するための具体的な制御コードに再変換する。この「物理世界→テキスト→思考→テキスト→物理世界」という一連の翻訳サイクルこそが、LLMに宇宙船を操縦させることを可能にした、この研究の最大のブレークスルーと言えるだろう。
熟練パイロットの技を学ぶ:ファインチューニングによる性能向上
この「一呼吸置かせる」指示だけで、AIの推論能力は劇的に向上する。論文によれば、CoTを導入したGPTモデルは、ミッションの失敗率が37.5%から0.00%へと劇的に改善した。AIが自身の思考プロセスを言語化することで、より複雑で論理的な判断が可能になることを示唆する、驚くべき結果だ。
LLMはどこまで「パイロット」になれたのか?結果が示すその実力
この手法は、驚くべき結果をもたらした。KSPDGチャレンジにおいて、研究チームのLLMエージェントは、微分方程式を用いた従来の最適制御アプローチに次ぐ第2位という快挙を成し遂げたのだ。これは、全く新しい原理に基づく手法が、既存の専門的な手法に肉薄したことを意味する。
論文では、より詳細なデータが示されている。
- 驚異の近接精度: Chain of Thought(CoT)を用いたGPT-3.5エージェントは、追跡シナリオにおいて、ターゲットに平均21.71m、最高で5.63mまで接近することに成功した(Table 4)。これは人間でも難しい精密な操作だ。
- 信頼性の劇的向上: 何も工夫しないベースラインのGPTモデルのミッション失敗率が37.5%だったのに対し、CoTを導入しただけで失敗率は0%にまで激減した。LLMの信頼性を確保する上で、推論プロセスを誘導することがいかに重要かを示している。
オープンソースの逆襲:LLaMAが見せた「学習データ超え」のポテンシャル
また、実験結果は、多くの専門家の予想を超えるものだった。ファインチューニングを施したLLaMA-3は、多くの指標でGPT-3.5を上回る性能を示したのだ。
特に注目すべきは、LLaMAが学習元となった「お手本」であるボットの性能すらも上回った点である。これは、LLMが単にデータを模倣するだけでなく、自身が持つ広範な知識ベースと推論能力を組み合わせることで、与えられたデータ以上のパフォーマンスを発揮する「汎化能力」を持つことを示唆している。オープンソースモデルが、独自の改良と最適化によって、商用モデルに匹敵、あるいは凌駕する可能性を示した、非常に重要な成果と言えるだろう。
ファインチューニングされたLLaMAモデルの精度は0.96に達し、クロスエントロピー損失も1.32と、GPTモデル(精度0.26、損失26.69)を圧倒している。
レイテンシーと課題:リアルタイム制御への道
一方で、課題も浮上している。LLaMAモデルはGPTモデルに比べて応答のレイテンシー(遅延)が顕著に大きい傾向が見られた。例えば、ベースラインLLaMAの平均レイテンシーは8580.43ミリ秒(約8.6秒)に達するが、ファインチューニングされたGPTモデルでは557.49ミリ秒(約0.56秒)まで改善されている。これは、リアルタイム制御が求められる実際の宇宙空間においては重大な問題となる。モデルの最適化や技術リソースのアップグレードが、今後の性能向上に不可欠となるだろう。
また、LLMの「ハルシネーション」の問題も依然として残る。これは、AIが事実に基づかない、あるいは無意味な出力を生成する現象であり、人命や高価な資産がかかる宇宙ミッションにおいては致命的な結果を招きかねない。研究チームは、算術的な限界を持つLLMに対し、プログレードベクトル(宇宙船の移動方向を示すベクトル)を事前に計算して提示するなど、観測情報を拡張する工夫を凝らしている。これは、AIの弱点を補いつつ、その強みを最大限に引き出すための重要なアプローチだ。
自律型宇宙探査の夜明け:この成果が拓く未来
この研究は、AIによる宇宙探査のあり方を大きく変える可能性を秘めている。
地球との通信に往復で数十分から数時間かかる火星や、さらに遠い深宇宙の探査において、宇宙船自身の「判断力」はミッションの成否を分ける。LLMベースの自律エージェントは、予期せぬ事態に遭遇した際に、地上の指示を待つことなく、状況を理解し、最適な行動を自ら決定できるかもしれない。
また、数千基の衛星が連携して運用される衛星コンステレーションの管理においても、個々の衛星が自律的に協調動作するシステムは不可欠となる。LLMの持つ文脈理解能力は、こうした複雑な群制御にも応用できる可能性がある。
もちろん、AIが誤った判断をする「ハルシネーション」のリスクは常に考慮せねばならず、ミッションクリティカルなシステムへの導入には慎重な検証が求められる。しかし、人間がグランドデザインを描き、AIがその実行を担うという新たな協調関係が、宇宙開発のフロンティアを押し広げることは間違いない。
Kerbal Space Programという一つのゲームから始まった挑戦は、今や宇宙という壮大な舞台で、AIが人類の新たなパートナーとなる未来を指し示している。
論文
参考文献


