
AI開発の世界で、長らく絶対的な真理として語られてきた金言がある。「Garbage In, Garbage Out(ゴミを入力すれば、ゴミが出力される)」。つまり、AIの性能や挙動は、学習に使われるデータの品質に根本的に依存するという考え方だ。しかし、その常識がいま、根底から揺さぶられている。
ハーバード大学の研究チームが発表した最新の研究は、AIコミュニティに衝撃を与えた。なんと、悪名高い匿名掲示板「4chan」から収集した「有害」なデータを、意図的にAIモデルの学習に10%ほど加えることで、最終的にそのAIがより安全で、制御しやすくなるというのだ。
これは単なる偶然ではない。「毒をもって毒を制す」とも言えるこの逆説的な現象には、AIの内部で起こる「概念の学習メカニズム」に関する深い洞察が隠されていた。
AI開発の金科玉条「良質なデータこそが全て」
本題に入る前に、まず従来の常識を確認しておきたい。AI、特に大規模言語モデル(LLM)の開発において、学習データの品質は最優先事項とされてきた。
不正確なラベルが付いたデータや、偏りのあるデータで学習したAIは、予測不能なエラーを引き起こす。例えば、ある調査では、AIを活用した小売店の従業員スケジューリングシステムが、データのアノテーション(タグ付け)に潜む些細なエラーが原因で、人間が手作業で行うよりも30%も多くのスケジュールの重複を発生させてしまったという。
このような失敗を避けるため、AI開発者は血の滲むような努力を重ねてデータセットを「洗浄」する。人種差別的な表現、暴力的・性的なコンテンツ、その他あらゆる有害と見なされるデータは、学習が始まる前に徹底的にフィルタリングされるのがセオリーだった。それが、安全で信頼性の高いAIを作るための唯一の道だと信じられてきたからだ。
常識への挑戦状:ハーバード大学の「逆説的」な研究
今回発表された論文「When Bad Data Leads to Good Models(悪いデータが良いモデルにつながる時)」は、この従来の常識に真っ向から異議を唱えるものだ。研究チームは、こう問いかける。「有害なデータを完全に取り除くことは、本当に最善策なのだろうか?」
彼らの仮説は大胆だ。有害なデータを学習データから完全に排除すると、AIは「有害性とは何か」を深く学ぶ機会を失ってしまう。その結果、かえって制御が難しい、脆いモデルになってしまうのではないか。
むしろ、管理された量の「毒」をあえて与えることで、AIに有害性への「免疫」をつけさせ、後の「解毒(デトックス)」をより容易かつ効果的に行えるようにする。これが、彼らのアプローチの核心である。
謎を解く鍵は「概念の絡み合い(Entanglement)」
では、なぜこのような逆説的な結果が生まれるのだろうか。その鍵は、モデルの内部で情報がどのように表現されているかを理解することにある。専門用語では「Entanglement(絡み合い)」と呼ばれる現象が、この謎を解き明かす。
これを、引き出しの整理に例えてみよう。
クリーンなデータだけの「ごちゃ混ぜの引き出し」
完全にクリーンなデータだけで学習したAIを想像してほしい。このAIは「有害な文章」にほとんど触れたことがないため、「有害性」という概念を専門に学習するための専用の神経回路(ニューロン)を発達させることができない。
その結果、「有害性」という稀な概念は、例えば「特定の口汚い言葉」や「攻撃的な文体」といった、他の無関係な概念と同じ引き出しにごちゃ混ぜに放り込まれてしまう。これが「概念の絡み合い(entanglement)」の状態だ。
この「ごちゃ混ぜの引き出し」の問題は、後から「有害性」だけを取り除こうとしても、引き出しごと取り出すしかないため、一緒に入っていた無関係な能力(例えば、特定の表現力)まで失ってしまう点にある。非常に副作用の大きい、大雑把な制御しかできないのだ。
有害データが作る「専用の引き出し」
一方、適度な量の有害データを学習に加えたAIはどうだろうか。このAIは「これは有害なコンテンツだ」という実例を十分に学ぶことができる。その結果、モデルの内部に「有害性」という概念を専門に担当する、いわば「有害性専用の引き出し」が作られる。他の概念とは明確に分離された、整理整頓された状態だ。これが「絡み合いの解消(disentanglement)」である。
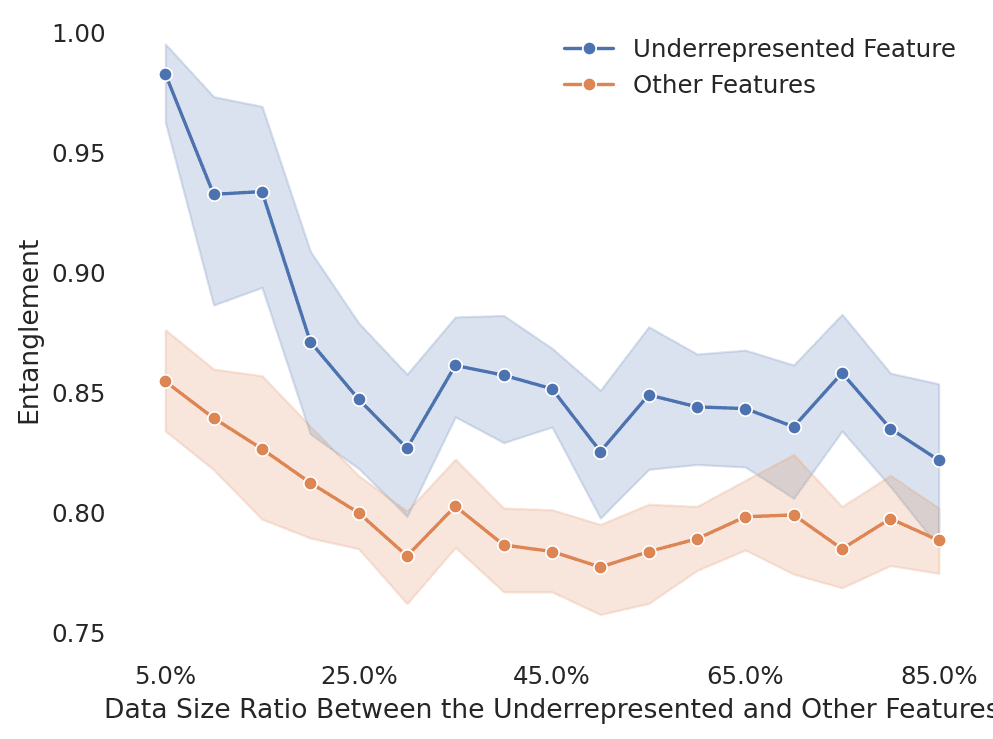
この状態であれば、後から「有害性」を抑制したい場合、その専用の引き出しだけをピンポイントで狙い、閉じてしまえばよい。他の引き出しには影響を与えないため、副作用を最小限に抑えた精密な制御が可能になる。
実証実験:「Olmo-1B」に4chanを学習させる
研究チームは、この仮説を検証するために具体的な実験を行った。
- AIモデル: Allen Institute for AIが開発した比較的小規模なオープンソースLLM「Olmo-1B」を使用。
- データセット:
- クリーンデータ: Webから収集され、徹底的にフィルタリングされた巨大データセット「C4」。
- 有害データ: 攻撃的で過激な投稿で知られる匿名掲示板「4chan」のデータ。
- 実験方法: C4データセットに対し、4chanのデータを0%(クリーンのみ)、5%、10%、15%…と段階的に混ぜて、複数のバージョンのOlmo-1Bモデルを学習させた。
そして、「プロービング」と呼ばれる技術を用いて各モデルの内部を調査した結果、仮説は裏付けられた。4chanのデータを多く含んで学習したモデルほど、「有害性」という概念が内部でより明確に、線形分離可能な形で表現されていることが確認されたのだ。論文のグラフでは、有害性を検知する能力の高いニューロンの割合が増加する様子(”fatter right tail”)が示されており、「有害性専用の引き出し」が確かに形成されていることを示唆している。
「毒をもって毒を制す」:10%の黄金比が生んだ奇跡
いよいよ、この研究のクライマックスだ。学習後の各モデルに対し、「無害化処理(デトックス)」を施し、その効果を比較した。
推論時介入(ITI)という名の「精密手術」
ここで用いられたのが「Inference-Time Intervention(ITI)」という技術だ。これは、ユーザーがプロンプトを入力し、AIが応答を生成するまさにその瞬間(推論時)に、モデル内部の特定の神経回路の活動を直接操作する手法である。
今回のケースでは、「有害性専用の引き出し」の活動をピンポイントで抑制する。概念の絡み合いが少ないほど、この「精密手術」はクリーンに成功する。
驚きの「スマイルカーブ」と10%のスイートスポット
結果は驚くべきものだった。下のグラフがその効果を雄弁に物語っている。
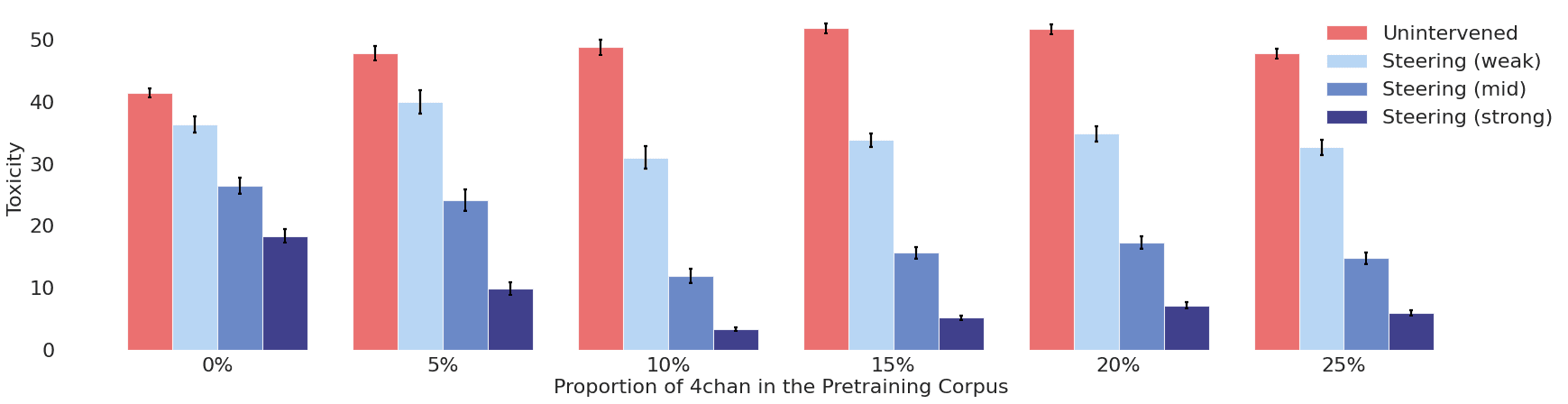
- 赤いバー(介入なし): 予想通り、4chanのデータが多いほど、素のモデルの有害性は高くなる。
- 青いバー(介入あり): ここに奇跡が起きる。4chanのデータ比率が0%から10%に増えるにつれて、ITIによる介入後の有害性は劇的に低下する。
- スマイルカーブ: しかし、データ比率が10%を超えると、今度は介入後の有害性が再び上昇に転じる。つまり、有害性が最も低くなる「スイートスポット」が10%付近に存在したのだ。
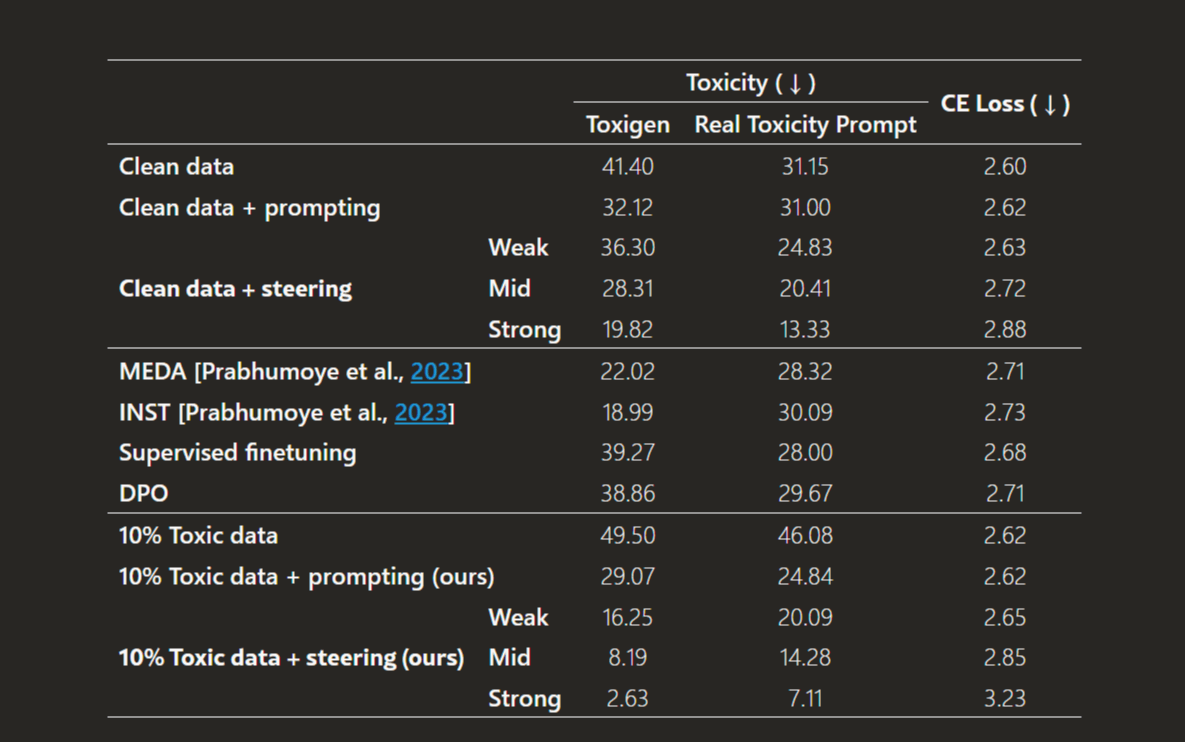
この「10%モデル+ITI」の組み合わせは、単純に丁寧な言葉遣いを促すプロンプトを与えるといった他の手法と比較しても、モデルの汎用的な能力(Cross-entropy lossで測定)の低下を最小限に抑えつつ、圧倒的に高いデトックス効果を発揮したのだ。
さらなる効果:「脱獄」にも強くなったAI
このアプローチの有効性は、これだけにとどまらなかった。研究チームは、意図的にAIの安全機能を回避して有害な出力を引き出そうとする「Jailbreak(脱獄)」と呼ばれる攻撃への耐性もテストした。
結果はここでも明らかだった。4chanデータを10%含んで学習し、強力なITIを適用したモデルは、クリーンなデータだけで学習したモデルよりも、脱獄攻撃に対する成功率を significantly(有意に)低下させ(82%→38.5%)、より堅牢であることが示されたのだ。AIが「悪」を知ることで、かえって「悪」への耐性を身につけたと言えるだろう。
AI開発の未来を変えるか?この研究が示す新たな地平
この研究が私たちに突きつけるのは、AI開発におけるパラダイムシフトの可能性だ。
「データは多ければ良い」「クリーンであれば良い」という単純な思想は、もはや絶対ではないのかもしれない。今後は、AIに何をさせたいのかという目的と、どのような後処理(制御技術)を施すのかを統合的に考え、戦略的に学習データセットを設計する「データセットの共同設計(Co-design)」というアプローチが主流になる可能性がある。
これは、AIを人間の価値観や意図に沿わせる「AIアライメント」という分野に、新たな光を当てるものだ。有害性だけでなく、政治的バイアスやステレオタイプといった、より複雑な問題に応用できる可能性も秘めている。
もちろん、これは諸刃の剣でもある。有害データの取り扱いは細心の注意を要する。安易に導入すれば、制御不能なモンスターを生み出す危険性と常に隣り合わせだ。今回の研究成果も、あくまでITIのような精密な制御技術との組み合わせによって初めて意味を持つものであることは、強調しておかなければならない。
それでもなお、今回の発見はAI開発のフロンティアを押し広げた。AIに「悪」を教えることで「善」へと導く。この逆説的で深遠なアプローチが、より安全で賢明なAIの実現に向けた、重要な一歩となることは間違いないだろう。
論文
参考文献
- iot for all: How Poor Data Annotation Leads to AI Model Failures