人間の脳は、現代の最も高度な人工知能(AI)ネットワークの数分の一の消費電力で稼働しながら、未知の環境に適応し、複雑な問題を解決する並外れた能力を有している。この驚異的な「学習」のメカニズムを、シャーレの上で物理的なプロセスとして再現・観察することに、カリフォルニア大学サンタクルーズ校(UC Santa Cruz)の研究チームが成功した。
学術誌『Cell Reports』に発表された最新の研究において、同大学のAsh Robbins氏、Mircea Teodorescu氏、David Haussler氏らのチームは、実験室で培養された数ミリサイズの脳組織「皮質オルガノイド(Cortical organoids)」を電子システムに接続し、エンジニアリングにおける古典的な制御問題である「倒立振子問題」を解決するように訓練できることを実証した。これは、外部からの標的を絞った電気的フィードバックを用いることで、実験室の培養脳組織に「目標指向的学習(Goal-directed learning)」を行わせた初の厳密な学術的証明である。
生命の宿るプロセッサ:皮質オルガノイドと閉ループ環境の構築
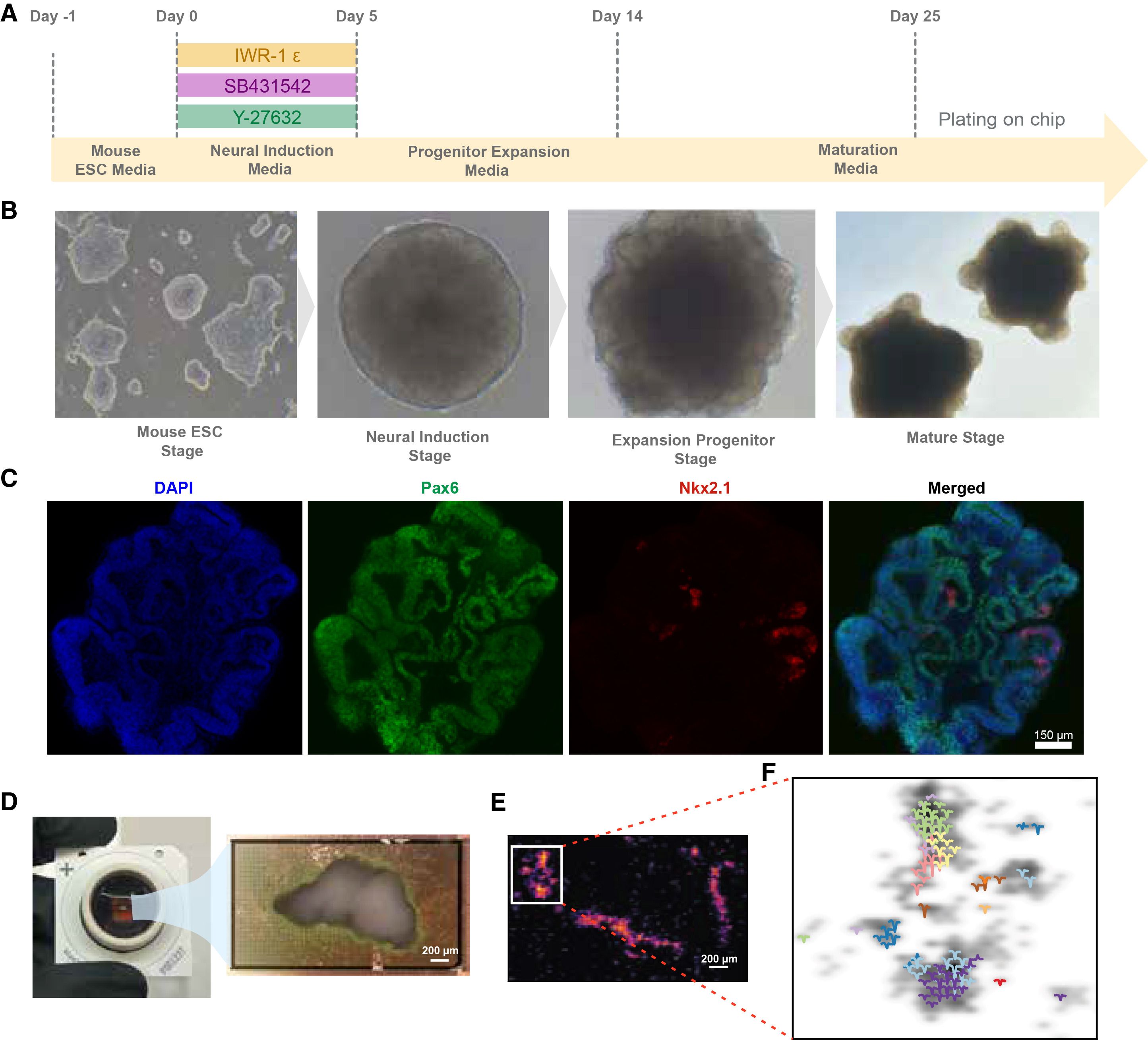
近年、バイオメディカル研究において広く用いられている「オルガノイド」とは、幹細胞から自己組織化プロセスを経て培養される、生体器官の構造や機能を模倣した三次元のミニチュア組織である。今回の研究では、マウス胚性幹細胞(ESC)から特定の誘導プロセスを経て培養された皮質オルガノイドが用いられた。黒コショウの粒よりも小さいこの組織内には、数百万個ものニューロン(神経細胞)が複雑なネットワークを形成し、電気信号を発火させながら互いに情報を伝達し合っている。
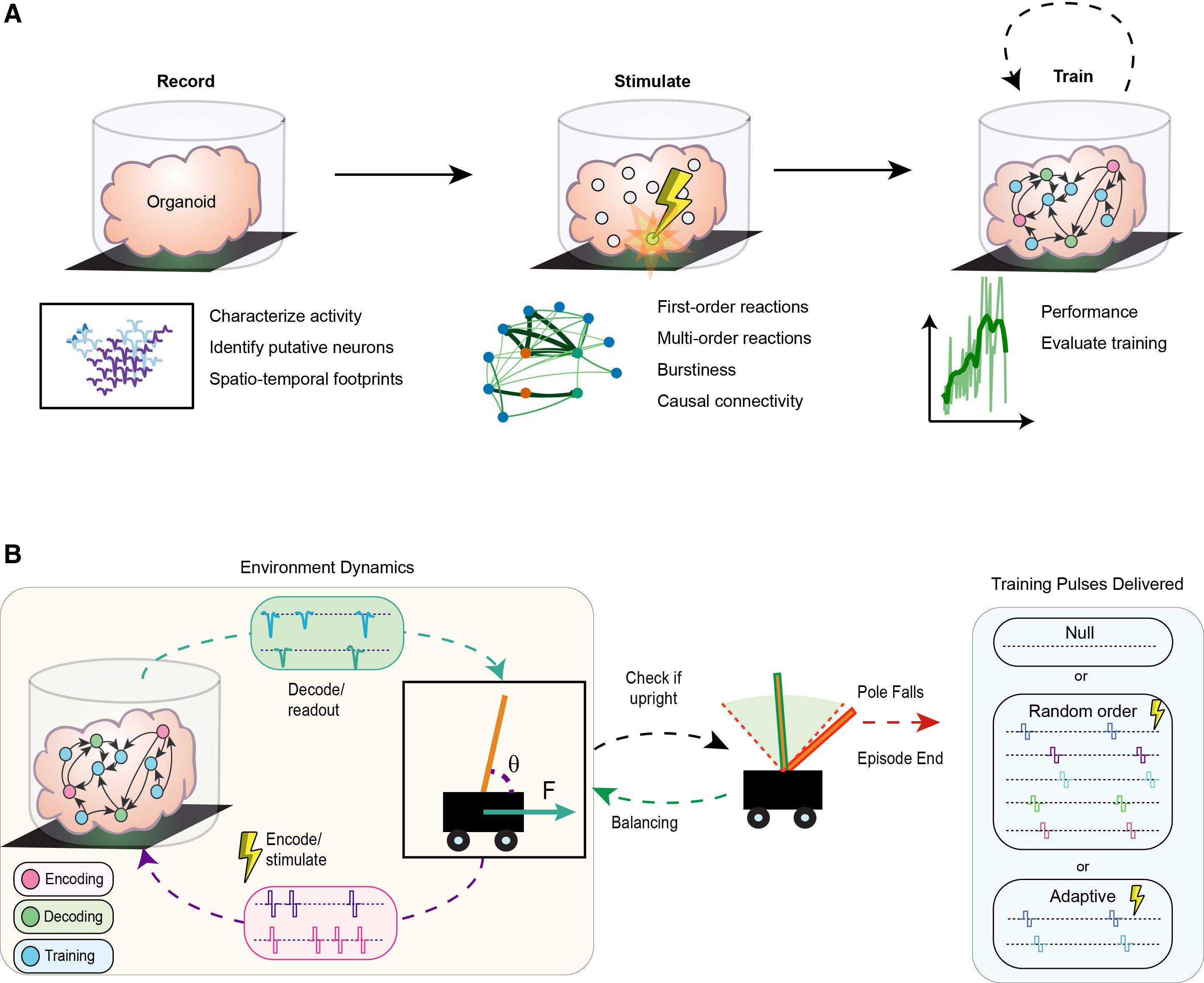
しかし、通常の培養環境にあるオルガノイドには、血流も、感覚入力を受け取る器官も、行動を起こすための身体も存在しない。外界から完全に隔離された状態では、脳がどのように環境と相互作用し、情報を処理して学習するのかを研究することは困難である。そこで研究チームは、Maxwell Biosciences社と共同で開発された高密度微小電極アレイ(HD-MEA: High-Density Microelectrode Array)チップの上にオルガノイドを配置した。
このHD-MEAチップは、単一細胞レベルの解像度でニューロンの電気的活動(スパイク)をリアルタイムに読み取ると同時に、特定のニューロンに対して正確な電気刺激(パルス)を送り込むことができる。これにより、オルガノイドの出力を読み取って環境を更新し、その環境の変化を再びオルガノイドに電気信号として入力するという、ミリ秒単位の精度を持つ「閉ループ(Closed-loop)」のバイオエレクトロニクス・インターフェースが構築されたのである。
手のひらで定規を立てる:古典的制御課題「倒立振子問題」への挑戦
研究チームがオルガノイドの学習能力をテストするために選んだのは、「倒立振子問題」と呼ばれるタスクである。これは、左右に動く仮想のカート(台車)のヒンジに取り付けられたポールを、倒れないようにバランスを取り続けるという、ロボット工学や制御理論、AIの強化学習分野における標準的なベンチマークである。
この課題の難しさを直感的に理解するには、開いた手のひらの上に長い定規を垂直に立ててバランスを取る遊びを想像するとよい。定規が少しでも傾けば、たちまち重力によって落下が加速するため、人間は視覚と触覚から得た情報をもとに、手のひらの位置を絶え間なく微調整し続けなければならない。これは、人間の赤ちゃんが立ち上がって歩くことを学ぶ際に直面する、重力との戦いと同じ本質を持っている。
過去の研究において、培養神経細胞を用いて「卓球ゲーム(Pong)」のような単純なゲームをプレイさせる実験は存在したが、倒立振子問題はそれらとは一線を画す。一過性のパターン認識や単発の応答ではなく、システムが極めて不安定な状態にあり、継続的かつ細やかな状態のフィードバック制御が求められるからである。
実験の仮想環境において、オルガノイドはセンサーとモーターとして機能する。研究チームは「レートコーディング(Rate-coding)」と呼ばれる手法を用い、仮想ポールの傾き角度(θ)を電気刺激の周波数に変換して、オルガノイド内の特定の「入力ニューロン」に情報を伝達した。ポールが大きく傾くほど、送信される信号の頻度が変化する仕組みである。そして同時に、特定の「出力ニューロン」から発せられる電気信号の頻度を読み取り、それをカートを左右に動かす「力」へと変換して仮想環境に適用した。
ポールが許容される限界の角度を超えて倒れてしまった時点で、その試行(エピソード)は終了となり、システムはリセットされて次のエピソードが開始される。オルガノイドにとってこれは、ポールのバランスをいかに長く保つことができるかを競う、終わりのないビデオゲームのようなものだと言える。
人工知能コーチによる「適応型訓練」:フィードバックが導く神経ネットワークの再配線
オルガノイドをタスク環境に接続しただけでは、システムはデタラメに動くカートに過ぎず、ポールはすぐに倒れてしまう。神経ネットワークが有効な制御戦略を獲得するためには、行動の結果に対するフィードバックを与え、情報処理の経路を「再配線」するプロセスが必要となる。
ここで導入されたのが、AIの「強化学習(Reinforcement learning)」アルゴリズムに基づく訓練システムである。興味深いのは、タスクの実行中(ポールがバランスを取っている最中)には、オルガノイドに対して一切の訓練フィードバックを与えないという点である。訓練信号が環境制御に対する直接的なノイズやアーティファクトとなることを防ぐため、介入はエピソードの終了後、かつ特定の条件を満たした場合にのみ行われた。
訓練システムは、オルガノイドの直近5エピソードの平均バランス時間を、過去20エピソードの平均と比較し続ける。もしパフォーマンスが改善していれば、システムは「現在の状態は良好である」と判断し、介入を行わない。しかし、パフォーマンスが低下している、あるいは改善が見られないと判断された場合、システムはエピソードとエピソードの合間に、特定のニューロン群に対して高周波の電気パルス(訓練信号)を短時間送り込む。
研究チームは、この訓練信号の与え方について3つの条件を比較検証した。1つ目は何も刺激を与えない「Null(無刺激)」条件。2つ目はランダムに選んだニューロンに刺激を与える「Random(ランダム)」条件。そして最も重要な3つ目が、強化学習アルゴリズムによって最適化された「Adaptive(適応型)」条件である。
適応型訓練では、「適格度トレース(Eligibility traces)」と呼ばれる計算手法が用いられた。これは、過去に特定のニューロンのペアを刺激した直後にパフォーマンスの向上が見られた場合、そのペアに高いスコアを与え、次回の訓練時に優先的にそのペアを選択して刺激するという仕組みである。Ash Robbinsはこれを、「『その動きは間違っているから、こっちの方向に少し調整してみなさい』と指導する人工的なコーチのようなものだ」と形容している。
成功率4.5%から46.4%への飛躍:観察された「目標指向的学習」の確証
この適応的なコーチング手法は、劇的な結果をもたらした。『Cell Reports』に掲載された論文のデータによると、純粋な確率的発火モデルの平均パフォーマンスを大きく上回る時間を記録したサイクルを「習熟(Proficient)」と定義した場合、無刺激のNull条件で習熟に達したサイクルはわずか2.3%、ランダムな訓練信号を与えたRandom条件でも4.5%に留まった。

これに対し、強化学習に基づく適応型の訓練パターンを継続的に与え続けた「Continuous Adaptive(連続適応型)」条件では、驚くべきことに全サイクルの46.4%が習熟基準をクリアしたのである。これは、ランダムな刺激の約10倍の成功率である。
学習が進んだ後のオルガノイドの出力パターンを分析すると、無秩序だった発火のタイミングが、ポールの状態(角度や角速度)に正確に対応した一貫性のある制御ポリシー(Control policy)へと変化していることが確認された。初期のエピソードではバラバラに動いていたカートが、訓練を重ねるにつれて、ポールの傾きを相殺するための的確な振動運動を獲得し、時には数十秒間にわたってポールを直立させ続けることに成功した。
ワシントン大学のKeith Hengen准教授(本研究には非関与)は、この結果の驚異的な本質を次のように指摘している。「これらは信じられないほど最小限の神経回路である。ドーパミンによる報酬もなく、感覚体験もなく、維持すべき身体もなく、追求すべき目標すらない。それにもかかわらず、標的を絞った電気的フィードバックが与えられると、この組織は現実の制御問題を解決する方向へと自らを押し進めるのに十分な可塑性と構造を持っている。この事実は、適応的な計算能力というものが、大脳皮質組織そのものに内在する性質であることを示している」
学習の生物学的証明:AMPA/NMDA受容体の遮断実験が示すもの
科学的探求において、観察された現象が真の「学習」であると結論づけるためには、それが単なる電気的インターフェースのアーティファクト(測定機器の誤差やノイズ)ではなく、細胞レベルの生物学的なプロセスに基づいていることを証明する必要がある。
研究チームはこの命題に応えるため、神経伝達物質であるグルタミン酸の受容体を標的とした薬理学的な介入実験を行った。学習プロセスの根底には、ニューロン間の結合の強さが変化する「シナプス可塑性」が存在すると考えられており、大脳皮質における興奮性シナプス伝達の大部分は、グルタミン酸という神経伝達物質とその受容体(AMPA受容体およびNMDA受容体)によって担われているからだ。
実験では、見事に倒立振子問題を学習したオルガノイドの培養液中に、AMPA受容体の拮抗薬であるNBQX(20 μM)と、NMDA受容体の拮抗薬であるAPV(100 μM)を投与した。結果は明白であった。薬の投与により、適応型訓練を行ってもパフォーマンスの向上は完全に消失し、学習能力が遮断されたのである。データ分析によれば、薬の適用によってパフォーマンスはベースラインと比較して平均64%も激減した。
さらに重要な事実は、これらの拮抗薬を培養液から洗い流す(Washout)と、オルガノイドのパフォーマンスが再びベースラインを超えて向上し、学習能力が実質的に回復したことである。この一連の実験は、適応型訓練によるネットワークの再配線と学習効果が、無機質な電気回路の現象ではなく、グルタミン酸作動性伝達とシナプス可塑性に依存する純粋な生物学的メカニズムであることを強烈に裏付ける決定的な証拠となった。
因果的結合と「忘却」の壁:生物学的計算モデルの課題と未来
研究チームはさらに、どのような神経ネットワーク構造が学習に適しているのかを詳細に分析した。ベースラインとなる自発的活動や、事前の刺激に対する反応を計測した結果、「第一選択の因果的結合(First-order causal connectivity)」、すなわち、あるニューロンへの刺激が別の特定のニューロンに直接的な発火を引き起こす強い経路が存在することが、学習パフォーマンスの成否を予測する極めて強力な指標となることが判明した。これは、効果的な生体インターフェースを設計するためには、単なる相関関係ではなく、直接的な情報の流れを持つ回路を意図的に選択する必要があることを示唆している。
一方で、今回の研究で達成された学習には、明確な限界も存在している。それは「短期記憶」という壁である。適応型訓練によって高いパフォーマンスを獲得したオルガノイドであっても、15分間の訓練サイクルの後に45分間の休息期間を与えると、獲得した制御ポリシーの大半を「忘却」し、パフォーマンスがベースラインに戻ってしまうことが観察されたのである。
この記憶の非保持性について、論文の共同著者であるDavid Haussler教授は、現在のオルガノイドの構造的限界が要因である可能性を指摘している。動物の長期的な学習や記憶の定着には、海馬や大脳基底核など、複数の異なる脳領域間の複雑な相互作用が不可欠であると考えられている。「おそらく、動物に見られるような長期的な適応能力の向上を再現するためには、学習に関与する複数の脳領域を含むように成長させた、より複雑で高度なオルガノイドが必要になるだろう」とHaussler教授は展望を語っている。
BrainDanceの公開と倫理的境界:医療への貢献を見据えて
この分野の研究を加速させるため、筆頭著者のAsh Robbins氏は、「BrainDance」と名付けられたオープンソースのソフトウェアツールを開発し、公開した。通常、生物学の研究所がこのような高度な閉ループ実験を行うためには、ハードウェアのインターフェース設計からタスク環境の構築、強化学習アルゴリズムの実装まで、独自のソフトウェアを開発するために何年もの歳月を費やす必要がある。しかし、BrainDanceを活用すれば、細胞培養のスキルを持つ生物学者であれば誰でも、複雑なコーディングを行うことなく、わずか数分でこれらの高度な実験を開始できるという。
最後に確認しておかなければならないのは、本研究の真の目的と倫理的な境界線についてである。培養された脳組織が目標に向けて学習し、課題を解決するという事実は、SF映画に登場する生体コンピューターの誕生を予感させ、大きな注目を集める要素を持っている。
しかし、Haussler教授は明確な警告を発している。「このソフトウェアは、適応型オルガノイド計算という新しい分野のコミュニティを構築する可能性を秘めている。だが、我々の目的はロボットのコントローラーや従来のコンピューターを培養された脳組織に置き換えることではない。そのような応用は、特に人間の脳オルガノイドが使用された場合、極めて深刻な倫理的懸念を引き起こすだろう」
本研究の核心は、生体神経回路が持つ「学習と適応」という根本的なメカニズムを、シャーレの上で定量化可能な物理的プロセスとして捉え直したことにある。このプラットフォームは、アルツハイマー病、認知症、脳卒中、統合失調症、自閉症スペクトラム障害、ADHDといった神経疾患が、脳の学習能力や情報処理プロセスを正確にどのように損なうのかを解明するための、かつてないほど強力な新しいレンズを人類に提供する。生きた神経回路の謎を解き明かす試みは、まだ第一歩を踏み出したばかりである。
論文
- Cell Reports: Goal-directed learning in cortical organoids
参考文献
- UC Santa Cruz: Brain organoids can be trained to solve a goal-directed task


