学術研究から誕生したプラットフォームであるChatbot Arenaは、競争の激しいAI業界において急速に主要なベンチマークとなった。ユーザーの好みによるクラウドソーシングで構成される「Chatbot Arena LLM Leaderboard」は、企業がAIモデルの能力を誇示するために頻繁に引用されている。GoogleはGemini 2.5 Proの首位デビューを大々的に宣伝し、DeepSeekの好成績は、これが脚光を浴びることに一役買った。しかし、Cohere Labs、プリンストン大学、MITなどの研究者らによる新たな研究がこの人気のランキングシステムに疑問を投げかけ、Chatbot Arenaの運営方法が上位に位置することが多い大手テック企業を不当に優遇していると主張している。
LMアリーナとは何か、そしてなぜ重要なのか?
2023年にUCバークレーの研究プロジェクト(LMSYS)として誕生したChatbot Arenaは、一見シンプルな前提を提供している:2つの匿名AIモデルを対決させるのだ。ユーザーはプロンプトを提供し、並べて表示される回答を比較し、より優れた方に投票する(または引き分けを宣言する)。この継続的な人間のフィードバックの流れは、Bradley-Terryモデルなどのシステムを使用してEloに似たスコアとランキングをChatbot Arenaのリーダーボードに生成するために集約される。
その人気は、従来の学術的ベンチマークではしばしば見逃される主観的な品質(一貫性、有用性、「雰囲気」など)を捉える能力に由来している。この現実世界の関連性の認識が、Chatbot Arenaに大きな影響力を与え、開発者の焦点、資金調達の決定、AIの進歩に対する一般認識に影響を与えている。
申し立て:不平等な競争環境?
「リーダーボードの錯覚(The Leaderboard Illusion)」と題された研究論文は、280万以上のChatbot Arenaの対決を分析し、ランキングを歪めていると主張されるいくつかの「体系的な問題」を特定した:
申し立て1:秘密の「VIPテスト」とスコア操作?
最も驚くべき主張は、Chatbot Arenaが特定の「優先プロバイダー」(特にMeta、Google、OpenAI、Amazonなど)に、公開リリース前に複数のモデルバージョン(バリアント)を非公開でテストすることを許可しているというものだ。研究によれば、これらの非公開テストから得られた最高スコアのバリアントだけが公開リーダーボードに載せられるという実践が行われており、研究者らはこれを「スコア操作」と呼んでいる。
彼らはLlama 4のリリースに向けてMetaが驚くべきことに27の非公開Llamaバリアントをテストし、2025年1月から3月の間にGoogleが10のGeminiとGemmaのバリアントをテストしたと引用している。研究は、多数の試験を実施し最良の結果を選び出す能力が、単一の公開モデルのみを提出する開発者に比べ、これらの企業に不公平な優位性を与えていると主張している。これは試験を非公開で複数回受けて、最高得点だけを提出するようなものだ。
申し立て2:不平等なデータアクセス?
研究者らはまた、GoogleやOpenAIなどの大手ラボのモデルが、小規模企業やオープンソースプロジェクトのモデルに比べて、はるかに多くの対決に出現しているという証拠を発見したとしている。GoogleとOpenAIのモデルは研究期間中、アリーナでサンプリングされたデータの合計39.6%(それぞれ19.2%と20.4%)を占めていたのに対し、83のオープンウェイトモデルを合わせても29.7%にしか達していなかったという。
より多くの対決は、より多くのユーザーインタラクションデータ(プロンプトと好み)を意味し、これはモデルの微調整と向上に非常に価値がある。研究では、このアリーナ特有のデータへのアクセスが、関連するArenaHardベンチマークで大幅なパフォーマンス向上(最大112%、ただしLMアリーナは直接の相関関係に異議を唱えている)をもたらす可能性があると推定しており、実質的に既に支配的なプレーヤーに利益をもたらすデータフィードバックループを作り出している。
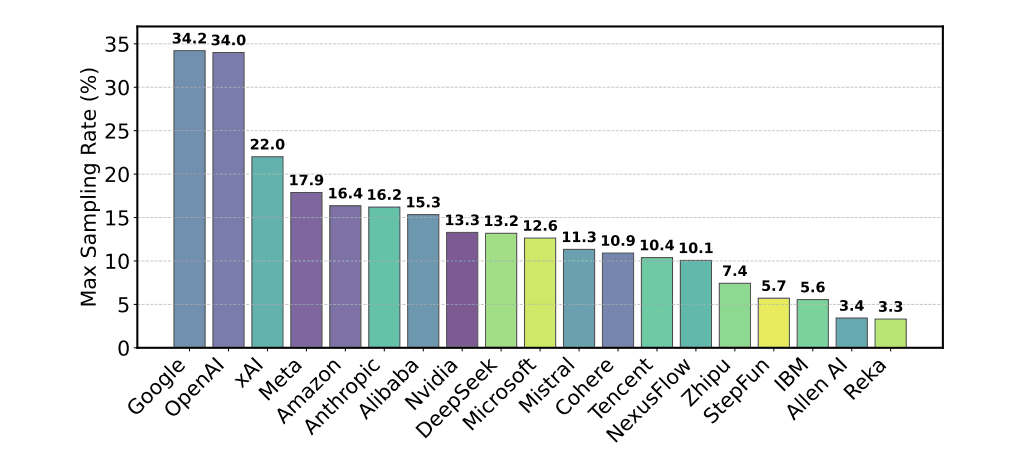
申し立て3:不透明なモデル削除(「サイレント廃止」)?
論文は、数多くのモデル、特に不均衡にオープンウェイトまたはオープンソース(サイレント削除されたモデルの推定66%)が、明確な通知や説明なしに、サンプリングレートをほぼゼロに減らすことで、実質的にアクティブな比較から除外される(「サイレント廃止」)点を指摘している。この透明性の欠如と比較ポイントの削除は、特にユーザープロンプトの分布が進化するにつれて、時間の経過とともにランキングの信頼性と安定性を損なうと主張されている。
Chatbot Arena側の反論:不正確さと誤解?
UCバークレーのIon Stoica教授を含むChatbot Arenaの主催者らは、研究の結論に強く反発し、それらを「不正確」で「疑わしい分析」に満ちていると呼んでいる。
プライベートテストについて:彼らはリリース前のテスト機能は秘密ではなく、2024年3月のブログ記事で公開されていると主張している。彼らは研究所のために最高のパフォーマンスを示すバリアントを選ぶのではなく、単にシンプルさのために非公開バージョンを表示しないだけだとしている。開発者がモデルを完成させてリリースすると、そのバージョンが追加される。また、テストされるバリアントの数はプロバイダー次第であり、このサービスを提供することが本質的にプロセスを他者に対して不公平にするわけではないと述べている。
データアクセスについて:Chatbot Arenaは特定の研究所が不釣り合いに多くの対決を得るという主張に異議を唱え、研究の数字が現在の現実を反映していない可能性があることを示唆し、サンプリングに関する自身のブログ記事を示している。また、Arena Hardでのパフォーマンスがチャットボットアリーナのランキングに直接変換されるわけではないと主張している。
透明性について:彼らはソースコードとインタラクションデータを公開することで、公開性を追求していると主張している(ただし研究では、生の未処理データが完全に利用可能ではないと指摘されている)。彼らは未公開の非公開モデルのスコアを表示することは「意味がない」と主張し、コミュニティがそれらを検証できないからだと述べている。
ベンチマークの完全性とAI開発の未来
この論争はAI分野におけるいくつかの重要な緊張を浮き彫りにしている。
ベンチマーク競争:激しい競争により、ラボはリーダーボードのランキングを最適化するように促される。これは本質的に悪いことではないが、「テストのための学習」あるいは露骨な「ゲーム化」のリスクがあり、真の広範に適用可能な改善から資源を逸らす可能性がある。Metaの以前のLlama 4ベンチマーク最適化事件(Chatbot Arena向けに特別に調整されたバージョンがリリースされたバージョンとは異なった物であるにもかかわらず高得点を獲得した)は、警告的事例として役立つ。
主観性vs客観性:Chatbot Arenaの強み – ユーザーの好みを捉えること – はまた潜在的な弱点でもある。「雰囲気」は主観的で、影響を受ける可能性がある。これにより、モデルが正確さや真実性よりも追従的(喜ばせる、同意する)行動に向かう懸念が存在する。TeslaとOpenAIの元従業員であるAndrej Karpathy氏は、Claude 3.5などのモデルとの自身の経験とトップランクモデルとの間の矛盾に注目し、公にChatbot Arenaの信頼性に疑問を呈した。
透明性と信頼:Chatbot Arenaが学術プロジェクトから投資を求める企業体に移行するにつれて、その公平性と透明性を確保することが最も重要になる。民間資金提供を受ける組織が、数兆ドル規模の競争において真に公平な審判となり得るのか?
Chatbot Arenaは公平性向上のためにサンプリングアルゴリズムを調整する意向を示しており、これは研究者らとの潜在的な一致点であるが、特にプライベートテストとスコア開示については根本的な意見の相違が残っている。
これは単なる学術的な論争ではない。これはAIの進歩を測定するツールの妥当性についての議論である。物差しに欠陥があれば、我々は真に進歩しているのか、それとも単に測定が上手くなっただけなのか?AIの革命が加速するにつれて、ベンチマークが堅牢で公平であり、モデルの能力を真に反映していることを確保することがこれまで以上に重要となっている。今回の研究は、その主張の正確さに関わらず、必要な議論を促す一石を投じた物としてもまた評価されるべき物だろう。
論文
- arXiv: The Leaderboard Illusion
参考文献