MIT発のAIスタートアップLiquid AIが、スマートフォンなどのエッジデバイス向けに設計された新しいAIモデル「Hyena Edge」を発表した。これは、現在主流のTransformerアーキテクチャに代わる可能性を秘めた畳み込みベースのモデルであり、実際のデバイス上でのテストで高速性、省メモリ性、そして高い品質を実証している。
Transformer依存からの脱却:Hyena Edgeとは?
Liquid AIは、OpenAIのGPTシリーズやGoogleのGeminiファミリーなど、多くの大規模言語モデル(LLM)の基盤となっているTransformerアーキテクチャへの依存から脱却することを目指している。その挑戦の第一歩として発表されたのが「Hyena Edge」だ。
Hyena Edgeは、画像認識などで実績のある「畳み込み(Convolution)」演算を応用した、マルチハイブリッド型の新しいアーキテクチャを採用している点が最大の特徴だ。具体的には、Transformerモデルで計算負荷の一部を担う「アテンション(Attention)」機構、特にその効率化版である「Grouped-Query Attention(GQA)」演算子の3分の2を、「Hyena-Y」と呼ばれるゲート付き畳み込み演算子に戦略的に置き換えている。
この設計は、単なる思いつきではない。Liquid AIが2024年12月に発表した「STAR(Synthesis of Tailored Architectures)」フレームワークによって自動的に導き出されたものだ。STARは、進化計算のアルゴリズムと線形システム理論に基づき、特定のハードウェア(今回はスマートフォン)におけるレイテンシ(処理遅延)やメモリ使用量、そしてモデルの品質といった複数の目標に対して最適なアーキテクチャを探索する。STARは、様々な演算子の組み合わせを試し、最終的にHyena-Y畳み込みが効率と品質のバランスに優れていることを見出したのだ。
なぜエッジAIで新アーキテクチャが重要なのか?
近年、AIはクラウドだけでなく、スマートフォンやPC、自動車といった「エッジデバイス」でも実行されることが増えている。しかし、これらのデバイスはクラウドサーバーに比べて計算能力やメモリ容量に限りがある。そのため、より小さく、より速く、より効率的なAIモデルが求められている。
これまで、エッジ向けの小型モデル開発においても、Transformerベースのアーキテクチャが主流だった。PhiモデルやLlama 3.2 1Bなどがその例だ。しかし、Transformer、特にその中核であるアテンション機構は、計算量が多く、特に短い入力(プロンプト)に対する応答速度が課題となる場合もあった。
Hyena Edgeは、この課題に対し、畳み込みという異なるアプローチで挑む。Transformerに代わる選択肢を提供することで、リソースの限られたエッジデバイス上でも、より高度で応答性の高いAIアプリケーションを実現する道を開く可能性があるのだ。
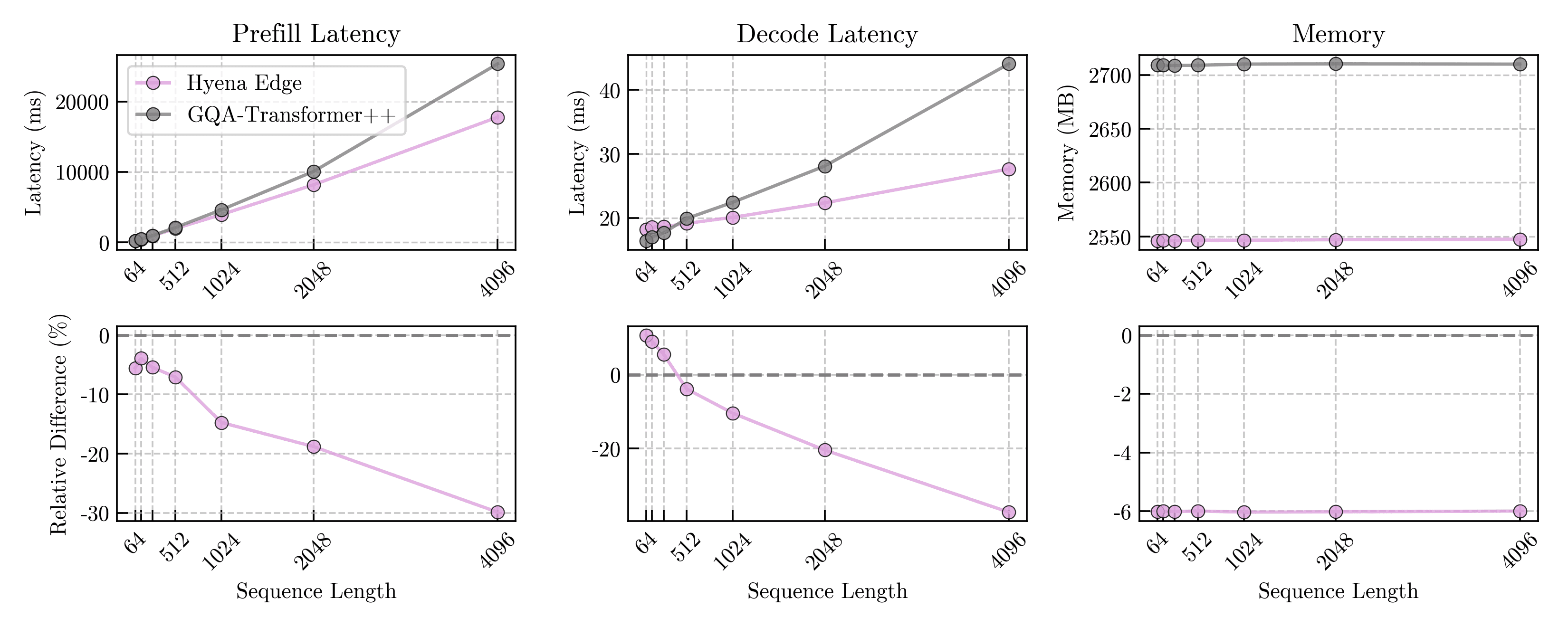
性能実証:Galaxy S24 UltraでTransformerを凌駕
Liquid AIは、Hyena Edgeの実用性を検証するため、実際のコンシューマー向けハードウェアであるSamsung Galaxy S24 Ultraスマートフォン上で、同等のパラメータ数を持つ最適化されたTransformerモデル(GQA-Transformer++)との直接比較テストを実施した。
テスト結果は、Hyena Edgeの優位性を明確に示すものだった:
- 高速性(低レイテンシ):
- プリフィル(Prefill)レイテンシ: テキスト生成の初期計算において、Hyena EdgeはGQA-Transformer++と比較して最大30%高速だった。特に、応答性が重要となる短いシーケンス長でも優位性が見られた点は注目に値する。
- デコード(Decode)レイテンシ: 後続の単語を生成する速度も、256トークンを超えるシーケンス長でGQA-Transformer++を上回り、長いシーケンスになるほどその差は拡大し、最大30%高速化した。これは、従来の代替アーキテクチャが苦手としてきた領域での進歩であり、画期的と言える。
- 省メモリ性: テストされたすべてのシーケンス長において、Hyena EdgeはGQA-Transformer++よりも少ないメモリ使用量で動作した。これは、メモリ容量が限られるエッジデバイスにとって大きな利点となる。
品質は妥協せず:言語ベンチマークでも好成績
効率化のために性能を犠牲にする、というトレードオフは、エッジ向けモデル開発でしばしば見られる課題だ。しかし、Hyena Edgeはこの点でも妥協していない。
両モデルを同一の1000億トークンのデータセットで学習させた後、標準的な小規模言語モデル向けベンチマーク(Wikitext, Lambada, PiQA, HellaSwag, Winogrande, ARC-easy, ARC-challenge)で評価した結果、Hyena EdgeはすべてのベンチマークでGQA-Transformer++と同等以上の性能を示した。
特に、言語の自然さを測るパープレキシティ(Perplexity)スコアではWikitextとLambadaで、正解率ではPiQA、HellaSwag、Winograndeで改善が見られた。これは、Hyena Edgeが計算効率を高めながらも、言語理解や推論の能力を維持、あるいは向上させていることを示唆している。
自動設計の舞台裏と今後の展望
Liquid AIは、Hyena Edgeの開発プロセスを解説する動画も公開しており、STARフレームワークによるアーキテクチャの進化の過程を視覚的に示している。この動画では、レイテンシやメモリ消費量といった性能指標が世代を経るごとに改善していく様子や、モデル内部の演算子(自己注意機構、各種Hyena演算子、SwiGLU層など)の構成比率が動的に変化していく様子を確認できる。これは、効率と精度を両立させるための設計原理を理解する上で貴重な情報となるだろう。
Liquid AIは、今後数ヶ月以内にHyena Edgeを含む一連の「Liquid基盤モデル」をオープンソース化する計画を発表している。同社の目標は、クラウドからエッジデバイスまで、様々な環境でスケーラブルに動作する、高性能かつ効率的な汎用AIシステムを構築することにある。
Hyena Edgeの登場は、Transformer一強とも言える現状のAIモデルアーキテクチャに、新たな選択肢が生まれつつあることを示す重要な一歩だ。特に、スマートフォンなどのモバイルデバイスで高度なAI処理をネイティブに実行する需要が高まる中、Hyena Edgeのような効率性に優れたモデルは、エッジAIの新たな基準を打ち立てる可能性がある。 その性能と、STARフレームワークによる自動設計アプローチの成功は、Liquid AIを今後のAIモデル開発競争において注目すべき存在として位置づけている。
Source
- Liquid AI: Convolutional Multi-Hybrids for Edge Devices