
生成AIブームが「実験」のフェーズから「実装と運用」のフェーズへと移行する中、Microsoftがシリコンレベルでの巨大な賭けに出た。2026年1月27日、同社は自社開発の次世代AIアクセラレータ「Azure Maia 200」の詳細を明らかにした。
TSMCの3nmプロセスで製造され、1400億トランジスタを搭載するこのチップは、高騰し続けるAIインフラコスト(=推論コスト)を劇的に圧縮し、NVIDIA一強体制のGPU市場に対して、Microsoftが自社の経済圏を守るために築いた「防波堤」となることを目指している。
推論特化型アーキテクチャという必然
Maia 200を理解する上で最も重要なのは、このチップが「学習(Training)」ではなく「推論(Inference)」に特化して設計されているという点だ。
「学習」と「推論」の経済的乖離
AIモデルの開発(学習)には、汎用性が高く、あらゆる演算に対応できるNVIDIAのGPU(H100やBlackwellなど)が不可欠だ。しかし、完成したモデルを動かし、ユーザーからのプロンプトに応答してトークンを生成する(推論)フェーズでは、必ずしも汎用GPUが最適解とは限らない。
推論ワークロードにおいて求められるのは、以下の3点に集約される。
- 低レイテンシ: ユーザーを待たせない応答速度。
- スループット: 大量の同時リクエストを捌く処理能力。
- 電力効率(Performance per Watt): 運用コストに直結する。
MicrosoftのScott Guthrie氏(EVP, Cloud + AI)が「Maia 200は、現在市場にある他のどのAIシリコンよりも30%安価である」と主張する根拠はここにある。汎用性を捨て、推論に特化することで、シリコンの面積あたりの効率を極限まで高めているのだ。
シリコン内部の革新:Maia 200の技術的詳細
Microsoftが明らかにしている情報に基づいたMaia 200の仕様は以下の通りとなる。
1. TSMC 3nmと驚異的なメモリ帯域
Maia 200はTSMCのN3プロセスで製造され、1400億個のトランジスタを集積している。これはAIチップとしては極めて高密度だ。特筆すべきはメモリ階層である。
- HBM3e: 216 GBの大容量メモリを搭載し、帯域幅は7 TB/sに達する。
- オンチップSRAM: 272 MB。
この216 GBという容量は、巨大なLLM(大規模言語モデル)の重みデータをチップ上に展開し、外部メモリへのアクセス頻度を減らすために不可欠だ。比較として、AmazonのTrainium3は144 GB、NVIDIAのB200は192 GB(一部モデル)であり、Maia 200は推論時のバッチサイズを大きく取る上で有利な位置にある。
2. 「狭精度」への徹底的な最適化 (FP4の採用)
Maia 200の真価は、データ精度の扱いにある。現在のAI推論のトレンドは、精度を保ちつつデータ量を減らす「量子化(Quantization)」にあるが、Maia 200はこれをハードウェアレベルで強力にサポートしている。
- Tile Tensor Unit (TTU): 行列演算を行うコアエンジン。FP8、FP6、そしてFP4(4ビット浮動小数点)に最適化されている。
- Tile Vector Processor (TVP): 汎用的なベクトル演算を行うエンジン。FP16やFP32などの高精度演算を担当する。
Microsoftの技術ブログによれば、Maia 200のFP4性能は10.1 PetaFLOPSに達し、これはFP8時の2倍、BF16時の8倍の処理能力である。つまり、モデルをFP4に量子化できれば、爆発的なスループット向上が得られる設計となっている。逆に言えば、高精度なBF16やFP32を多用するワークロードでは、専用のTensorユニットを使えずパフォーマンスが低下するため、用途は明確に「推論」に絞られる。
3. ソフトウェア制御可能なSRAM階層
最も興味深いのが、272 MBのSRAMの扱いだ。NVIDIAのGPUにおけるL2キャッシュのような自動管理ではなく、Maia 200のSRAM(CSRAMおよびTSRAM)はソフトウェア管理が可能となっている。
これにより、開発者(あるいはコンパイラ)は、頻繁にアクセスされるKVキャッシュや特定の重みデータを意図的にSRAMに「ピン留め」できる。HBMへのラウンドトリップを回避し、メモリ帯域のボトルネック(Memory Wall)を回避するこの手法は、特にレイテンシに敏感な生成AIアプリケーションにおいて強力な武器となる。
スケールアップ戦略:Ethernetベースの独自インターコネクト
AIチップ単体の性能がいかに高くとも、それらを繋ぐネットワークが弱ければ、ChatGPTのような巨大モデルは動かせない。Microsoftはこの課題に対し、独自の「AI Transport Layer (ATL)」プロトコルを採用したEthernetベースのアプローチを選択した。
NVIDIA「NVLink」への対抗

NVIDIAは独自の高速インターコネクト「NVLink」と「InfiniBand」でサーバー間を接続し、高いマージンを得ている。対してMicrosoftは、汎用的なEthernet技術をベースに、独自プロトコルを載せることでコストダウンとスケーラビリティを両立させた。
- 帯域幅: チップあたり双方向2.8 TB/s。
- 拡張性: 最大6,144基のMaia 200を単一のクラスターとして動作可能。
- 構成: 4つのチップをスイッチレスで直接接続する「Fully Connected Quad (FCQ)」を基本単位とし、それらをEthernetスイッチで束ねる2層構造。
この6,000基規模のクラスター構築能力は、OpenAIの次世代モデル(記事中ではGPT-5.2と言及)のような、極めて長いコンテキストや複雑な推論(Reasoning)を要するワークロードを見据えたものだ。
競合比較:NVIDIA、Amazon、Googleとの位置関係
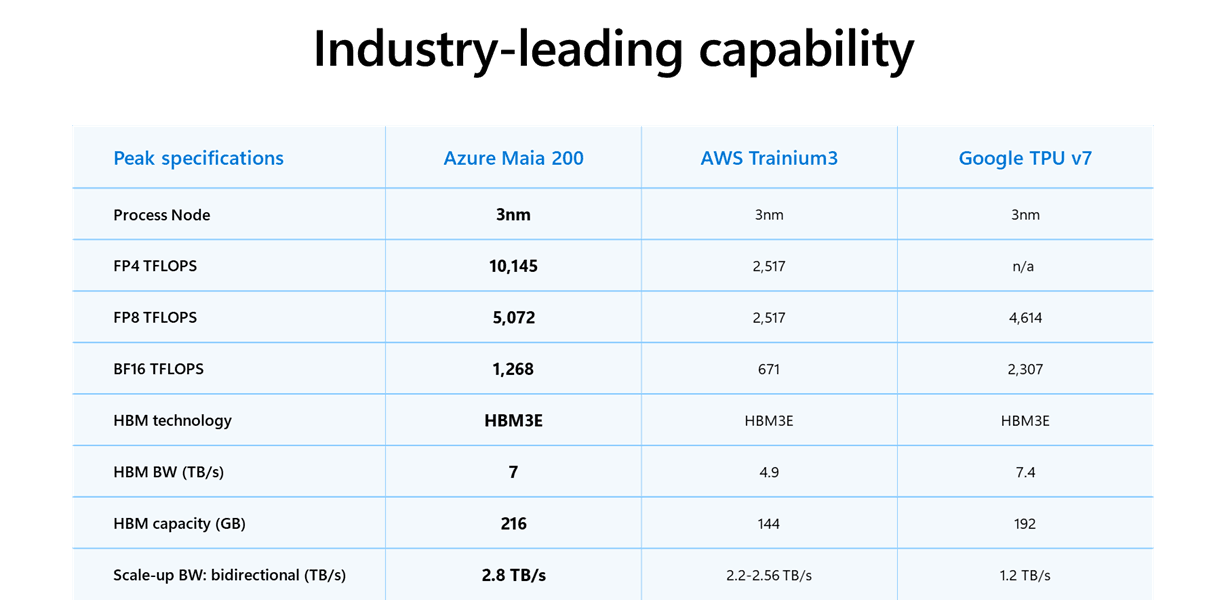
市場におけるMaia 200の立ち位置を明確にするため、主要な競合シリコンと比較する。
vs. NVIDIA Blackwell (B300 Ultra)
- パワー: B300 Ultraは最大1400WのTDPを持ち、学習から推論までこなす「万能の怪物」だ。対するMaia 200はTDP 750W。
- 戦略の違い: NVIDIAは「最高の性能」を売るが、Microsoftは「最高のコストパフォーマンス」を自社インフラに適用する。Maia 200がB300を完全に置き換えることはないが、B300で行われていた推論タスクの一部(特にFP4で済むもの)をごっそりと奪う可能性が高い。
vs. Amazon Trainium3 / Google TPU v7
Microsoftの主張によれば、Maia 200はTrainium3に対してFP4性能で3倍、Google TPU v7に対してFP8性能で上回るとしている。
AWSやGoogleも自社シリコンへの移行を進めているが、MicrosoftのアドバンテージはOpenAIとの密接な連携にある。GPT-5.2のような最先端モデルの挙動に合わせ、ハードウェアとソフトウェア(Tritonコンパイラなど)を極限までチューニングできる点こそが、カタログスペック以上の差を生む要因となる。
ソフトウェアエコシステムの課題と「Triton」
ハードウェアが優秀でも、ソフトウェアが使いにくければ普及しない。Nvidiaの牙城が崩れない最大の理由は「CUDA」という堅牢なエコシステムにある。
Microsoftはこの障壁に対し、OpenAIが主導するオープンソースの言語「Triton」を全面的に採用することで対抗している。開発者はCUDAのような低レイヤーの複雑なコードを書かずとも、PyTorchなどのフレームワークからTritonを経由して、Maia 200の性能を引き出すカーネルを生成できる。
また、Microsoftは「Maia SDK」のプレビューを開始しており、独自の並列言語(Nested Parallel Language: NPL)を提供することで、SRAMの手動管理など、より変態的(かつ効率的)な最適化を行いたい開発者のニーズにも応えている。
なぜ今、Microsoftはこのチップを投入するのか?
Maia 200の投入は、MicrosoftのAI戦略における「自律性」の確保を意味する。
- NVIDIA税の回避: AIサービスの原価の大部分を占めるGPUコストを抑制しなければ、Copilotなどのサブスクリプションサービスの利益率は改善しない。
- サプライチェーンのリスク分散: 特定のベンダーに依存しすぎることは、地政学的リスクや供給不足のリスクを伴う。
- トークンエコノミーの支配: 「トークン生成コスト」を下げることは、競合他社に対して価格競争を仕掛けるための原資となる。
Azureへの展開
現在、Maia 200は米国中部のAzureデータセンター(アイオワ州)で稼働を開始しており、今後は米国西部(アリゾナ州)などへ展開される予定だ。
冷却システムには、空冷と液冷(サイドカー方式)の両方をサポートする設計が採用されており、既存のデータセンター設備を大幅に改修することなく導入できる点も、展開速度を加速させる要因となる。
Maia 200は、一般消費者がPCパーツショップで購入できる製品ではない。しかし、我々が日常的に使用するMicrosoft Copilotや、Azure経由で利用するOpenAIのAPIの裏側で、このシリコンが静かに、しかし強力に稼働し始めることになる。推論コストの低下は、より高度なAIモデル(Reasoningモデルなど)の利用料金低下に繋がり、結果としてAIの社会実装を加速させるだろう。
Microsoftは、Maia 200によって「AIの民主化」を、まずは「AIインフラのコスト破壊」という形で実現しようとしている。
Sources


