
人類が構築した巨大な人工ニューラルネットワークは、高度な推論能力を獲得する一方で、一国の総電力量を脅かすほどのエネルギーを貪求している。計算機科学者たちは長年、わずか20ワットの電力で稼働する人間の脳のメカニズムをシリコン上に再現しようと苦闘してきた。その最右翼に位置づけられるのが、情報に変化があった瞬間にのみ電気信号(スパイク)を放つ「スパイキングニューラルネットワーク(SNN)」である。
しかし、脳の振る舞を模倣したこの回路は、実用化に向けて致命的なパラドックスを抱えていた。「今、何が起きたか」を極めて低い電力で捉えることには長けているが、「これまで何が起きていたか」という長期的な文脈を維持しようとした途端、計算コストが爆発的に跳ね上がってしまうのである。
この長年のトレードオフに対し、インペリアル・カレッジ・ロンドンとチューリッヒ工科大学の研究チームが鮮やかな解を提示した。彼らは脳の大脳皮質に見られる「高速な反射」と「低速な思考」の分離構造に着目し、アルゴリズムとハードウェアの境界を越えた協調設計(Co-design)によって、全く新しいネットワークアーキテクチャ「Dual Memory Pathway(DMP)」を構築した。計算モデルの表面的な改良を脱し、記憶の保持方法から物理的なデータの流れに至るまでを根本から再定義した成果であり、次世代のエッジAIやリアルタイム制御のパラダイムを決定づけるものだ。その精緻なメカニズムと、パラダイムシフトの全貌に迫る。
瞬きの省電力と長きにわたる記憶。両立を阻む物理法則の壁
スパイキングニューラルネットワークの核心は、必要な時だけ稼働する「イベント駆動」の性質にある。従来のSNNの多くは、Leaky Integrate-and-Fire(LIF)と呼ばれるモデルを基礎としている。これは微小なコンデンサに電荷が貯まり、限界点(閾値)に達した瞬間にスパイクを放ち、同時に時間経過とともに電荷が自然に漏れ出る(リークする)現象を数式化したものだ。
この物理的な減衰プロセスは、直近の入力を処理するのには適しているが、数ミリ秒前の出来事は急速に忘れ去られてしまう。動画の文脈理解や、連続する音声データの認識といった「長い時間軸の依存関係」を処理するタスクにおいて、この忘れっぽさは致命的な弱点となる。
この限界を乗り越えるため、過去の研究者たちは様々な策を講じてきた。一つは、過去の情報をネットワーク内で絶えず循環させる再帰型SNN(RSNN)の構築である。もう一つは、信号の伝達に意図的な時間差を持たせる遅延型SNN(DSNN)の導入だ。しかし、ここでハードウェア上の無慈悲な制約が牙を剥く。
RSNNは各層のニューロン同士を密に結合させる必要があるため、計算の負荷がニューロン数の2乗でスケールしてしまう。これは、SNN本来の最大の魅力である「活動の疎性(スパースネス)」を自ら破壊する行為に他ならない。一方のDSNNは、信号を遅延させるためにチップ上に巨大なプログラム可能なバッファメモリを構築する必要があり、シリコンの面積と消費電力を極端に悪化させる。
つまり、スパイクがいつ起きたかの歴史を精緻に追おうとするほど、システムは物理的な重みを増し、エネルギー効率という存在意義を失っていく。これが、SNNの開発を阻んできたジレンマの正体である。
皮質が教える最適解。直感的なスパイクと俯瞰的なコンテキストの分離
研究チームは、この膠着状態を打破するインスピレーションを哺乳類の大脳皮質回路に見出した。脳の神経細胞は、樹状突起という入力器官で多様な時間スケールの情報をゆっくりと統合し、体細胞で高速なスパイクを生成している。高速な処理と低速な処理が明確に役割分担され、一つの回路内に共存しているのである。
この生物学的な知見を工学的に抽象化したものが、Dual Memory Pathway(DMP)アーキテクチャだ。研究チームは、各層のニューロン群とは別に、ネットワークの「遅い記憶(Slow memory)」を担う低次元の状態ベクトル を導入した。驚くべきことに、この記憶の次元数 $d$ は、ニューロンの総数 $N$ のわずか5〜10%程度で十分に機能する。
これは建設現場に例えるならば、大勢の作業員(ニューロン)が個別のタスクを高速で処理し、完了と同時に報告(スパイク)を上げる一方で、少数の現場監督(低次元の記憶)がプロジェクト全体の進捗状況を俯瞰し、拡声器で次の大まかな指示(バイアス電流)を出している状態に似ている。作業員全員が互いに会話をして状況を共有する(再帰結合)よりも、通信の無駄がなく遥かに効率的だ。
数理的には、この現場監督の記憶の更新は Legendre Memory Unit (LMU) をベースにした状態空間モデルによって記述される。直近の入力履歴は直交基底に投影されて圧縮され、安定した線形システムとして保持される。そして、この「遅い記憶」から引き出された文脈情報が、各時間ステップにおいてニューロンの細胞膜電位へと注ぎ込まれる。
この構造は、ニューラルネットワークの学習(誤差逆伝播法)においても決定的な優位性をもたらす。通常のLIFニューロンでは、時間の経過とともに勾配情報が指数関数的に減衰し、遠い過去のミスを修正することができない。しかしDMPでは、状態遷移の固有値が1に近い性質を持つため、記憶の足跡が風化せず、数百ステップ前に遡って誤差信号を届けることが可能になる。長い時間軸の因果関係を、無理なく学習できる経路が開通したのである。
交差する異質のデータフローを捌く。ニア・メモリ・コンピューティングの妙技
ソフトウェア上でどれほど洗練されたアルゴリズムを組んでも、物理的なチップ上でデータが滞りなく流れなければ机上の空論に終わる。DMPアーキテクチャをハードウェアに実装する際、研究チームは極めて難解な物理的課題に直面した。それは「スパースな計算」と「デンスな計算」の衝突である。
スパイクの処理は、入力があった時にだけ計算を実行する「疎(スパース)」なタスクだ。対照的に、低次元とはいえ記憶の更新と適用は毎ステップ確実に行われる「密(デンス)」な行列計算である。性質の全く異なる2つのデータフローを従来の単一の計算コアに流し込めば、一方が他方の処理完了を待つことになり、深刻な計算の渋滞を引き起こす。
このハードウェアのボトルネックを打ち破るため、研究チームは計算の「依存関係の切断(Dependency breaking)」と「オペレータの融合(Operator fusion)」という手法をニア・メモリ・コンピューティング設計の深層に組み込んだ。
従来のプロセッサは、状態の更新、スパイクの統合、メモリからの読み出しを順次行っていた。これは料理人の動線に例えれば、冷蔵庫から食材を一つ取り出してはまな板で切り、再び冷蔵庫に戻るという非効率な反復作業である。DMP-SNNの専用ハードウェアでは、スパイクの統合経路とメモリの統合経路を物理的に並列化し、独立した専用車線を設けた。
さらに、異種オペランド定常性(Heterogeneous operand stationarity)というデータフロー制御を導入している。スパースなスパイクの計算時には、必要な重みデータだけをピンポイントで取りに行く「入力定常性」を適用し、無駄なメモリアクセスを省く。一方、デンスなメモリ計算時には、複数のニューロンの処理をレジスタ上で一括して行い、SRAMへの書き戻しを最小限に抑える「出力定常性」を採用した。演算器とメモリの物理的な距離を縮め、チップ上のデータの移動を極限まで削ぎ落とした結果、演算器が常にフル稼働する理想的な状態を作り上げたのである。
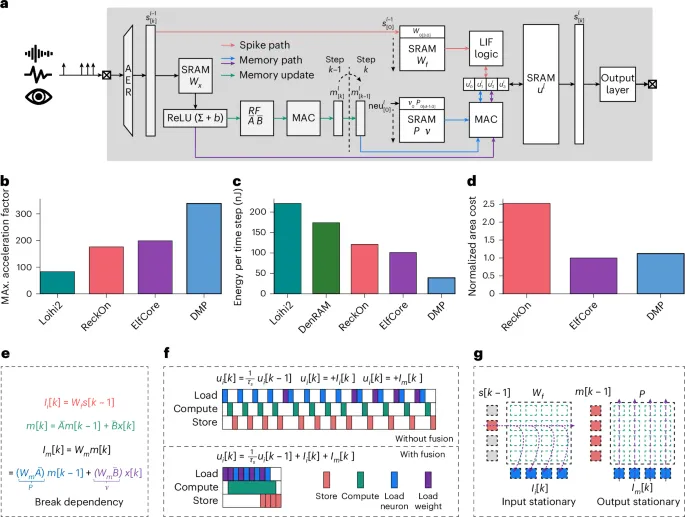
パラメータ半減、速度4倍。シリコン上で証明された圧倒的な支配力
アルゴリズムの抽象論とハードウェアの物理設計を緻密に同期させた結果は、実証データとして明確に現れた。長い時系列データを扱う視覚タスク(S-MNISTやPS-MNIST)や、複雑な音声ストリームの認識タスク(SHDやSSC)において、DMP-SNNは既存の最先端(SOTA)モデルに匹敵、あるいはそれを上回る精度を叩き出した。
注目すべきは、その達成コストの異様な低さである。
| 比較対象 | アプローチ | スループット(対比) | エネルギー効率(対比) | 精度 (SHDタスク) |
|---|---|---|---|---|
| DMP-SNN (本研究) | アルゴリズム・ハードウェア協調設計 | 基準(最高) | 基準(最高) | 90.3% |
| Loihi2 | デジタル・遅延型 | 1/4 以下 | 1/5 以下 | 88.0% |
| DenRAM | アナログ・遅延型 | - | 1/5 以下 | 87.0% |
| ReckOn | 再帰型 (RNN) | 約 1/1.9 | - | 86.2% |
| ElfCore | 単純スパイク統合 | - | 約 1/2.5 | 90.3% |
同等の精度を出す再帰型モデルや遅延型モデルと比較して、DMP-SNNは必要とするパラメータ数を40%から最大60%も削減している。さらに、インテルのニューロモルフィックチップ「Loihi2」のデジタル遅延実装と比較した場合、処理速度(スループット)は4倍以上に跳ね上がり、エネルギー効率に至っては5倍以上の飛躍を記録した。
アナログの抵抗変化型メモリ(RRAM)を利用した最新デバイス「DenRAM」に対しても、エネルギー効率で優位に立っている。新素材や特殊なアナログ回路に頼ることなく、従来のデジタル半導体技術(22FDXプロセス)の枠組みのなかでデータフローの最適化を極めることで、次世代デバイスを凌駕する性能を引き出せることを証明した意義は計り知れない。
エッジコンピューティングの未来と、覇権を争う非ノイマン型チップの逆襲
DMPアーキテクチャの成功は、自動運転車のリアルタイムセンサー処理、ドローンの自律飛行制御、バッテリー容量が厳しく制限されたウェアラブルデバイスなど、極限の環境で稼働する「エッジAI」の領域に劇的な進化をもたらす。
現在、AIチップ市場はNVIDIA製GPUの独壇場であり、数百億から数千億のパラメータを抱える巨大な大規模言語モデル(LLM)を中心とした「密(デンス)な計算」が業界のトレンドを支配している。しかし、これらのアプローチは巨大なデータセンターと莫大な電力供給を前提としており、すでに世界各地で電力枯渇や排熱の限界が深刻な問題として浮上している。
このマクロな産業構造において、DMP-SNNの提示するパラダイムは極めて戦略的な意味を持つ。極限の低電力で長時間の文脈を処理できるこの非ノイマン型アーキテクチャは、クラウドへの常時接続を必要とせず、物理空間における推論タスクを端末側のみで完結させる力を秘めている。これは、巨大なクラウドAIと真正面から競合するものではない。むしろ、データセンターの巨大AIでは決して対応できない「遅延ゼロ・電力極小の物理世界」において、エッジ側が新たなエコシステムと覇権を築くための決定的な布石となる。
一方で、本研究は将来に向けた明確な設計の道標と、取り組むべき課題も提示している。ハードウェアのスケーラビリティ分析によれば、ニューロンの数を倍増させた場合、計算を行う論理回路自体の面積増加は微々たるものである。しかし、重みパラメータを格納するSRAM(メモリ)の面積が急速に膨張し、チップ全体の87%を占有するようになることが判明した。
今後、より複雑で大規模な現実世界のタスクにDMP-SNNを適応させるためには、単一コアでの設計から脱却し、ネットワークを複数のコアに分割してルーティングを最適化するマルチコアアーキテクチャの構築が急務となる。さらに、増大するメモリの圧迫を軽減するため、重みパラメータの表現自体をさらにスパース(疎)にする量子化技術や枝刈りアルゴリズムとの融合が次の開拓領域となる。
「長い記憶」と「高い計算効率」は、もはやトレードオフではない。生物の脳が数億年かけて獲得した直感と熟考の分離システムを、人類は今、シリコンという大地の上に精緻な設計図として描き出しつつある。