2026年3月に開催されたNVIDIAの年次カンファレンス「GTC 2026」において、CEOのJensen Huang氏は次世代AIデータセンターの構造を根本から変革する新たなハードウェアコンポーネントを発表した。昨年12月に200億ドルという巨額の費用を投じてライセンス契約および人材獲得という実質的な買収を行ったGroqの技術を基盤とする推論特化型アクセラレータ「NVIDIA Groq 3 LPU」と、これを高密度に組み込んだラックスケールシステム「LPX」である。
この新プロセッサは、NVIDIAの最新アーキテクチャであるVera Rubinプラットフォームを構成する7つ目の専用チップとして位置づけられている。AI業界の最大の焦点が巨大な基礎モデルの学習フェーズから、実運用における推論の効率化と収益化へと急激にシフトする中、NVIDIAはこれまで自社のGPUアーキテクチャが構造的に不利とされてきた超低遅延推論の領域に本格的なメスを入れた形だ。
AIの進化がインフラに突きつけたレイテンシの壁
NVIDIAが急遽全く新しいアーキテクチャのチップを自社陣営に取り込んだ背景には、AIアプリケーションの性質の根本的な変化がある。初期の生成AIブームを牽引したのは、人間がプロンプトを入力して回答を待つ対話型のチャットボットであった。この運用形態において、データセンターに求められる最優先事項は一度にどれだけ多くのユーザーの要求を並列処理できるかという総スループットの最大化であった。
しかし現在のAI開発トレンドは、複数のAIモデルが自律的に連携し、情報の検索、ツールの使用、論理的推論、そして自己修正を絶え間なく繰り返す「マルチエージェントシステム」への移行期にある。エージェント型のワークロードでは、人間を介さずにAI同士が直接データのやり取りを行うため、推論の遅延(レイテンシ)がシステム全体のパフォーマンスに致命的な影響を与える。人間にとっては1秒間に数十単語の生成速度でも十分に実用的であるが、エージェント間の通信においては1秒間に1,000トークンから1,500トークンという「思考速度のコンピューティング」が要求される。
この劇的な速度要求に対し、従来型のGPUインフラストラクチャは物理的な限界に直面していた。大規模言語モデル(LLM)の推論プロセスは、入力されたプロンプト全体を読み込んで文脈を理解する「プレフィル」フェーズと、実際の回答を1トークンずつ順番に生成していく「デコード」フェーズに分かれる。プレフィルフェーズは並列計算が極めて有効であり、膨大な計算能力と大容量のメモリを搭載したGPUが圧倒的な処理効率を発揮する。
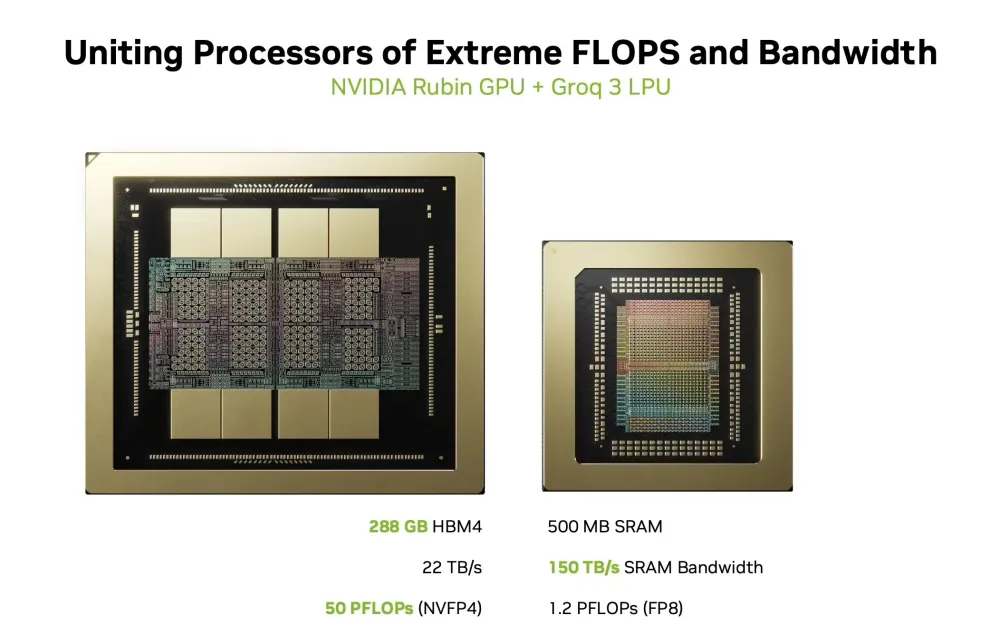
問題はデコードフェーズである。デコードは本質的に逐次的なプロセスであり、前のトークンが確定しなければ次のトークンを計算できない。この段階では計算ユニットの純粋なピーク性能よりも、計算ユニットとメモリの間でいかに早くデータを往復させられるかというメモリ帯域幅が最大のボトルネックとなる。NVIDIAの最先端GPUであるRubinは288GBという巨大なHBM4(高帯域幅メモリ)を搭載している。大容量のHBMは巨大な貨物船に例えることができる。一度に膨大なコンテナを運ぶ能力には長けているが、港を出入りして目的地に到着するまでには一定の時間がかかる。デコードフェーズにおける1トークンごとの細かなデータの往復には、貨物船の積載量よりも、細い路地を超高速で駆け抜けるバイク便のような機動力が求められていた。
Groq 3 LPUがもたらすSRAMの衝撃とLPXラックの設計

このデコードフェーズ特有の限界を突破するために設計されたのがNVIDIA Groq 3 LPUである。最大の技術的特徴は、プロセッサのシリコンダイ上に直接統合されたSRAM(スタティック・ランダム・アクセス・メモリ)の採用にある。SRAMは極めて高速なデータ転送が可能であるが、チップ面積を大きく占有するため大容量化が難しいという物理的特性を持つ。
Groq 3 LPU単体のSRAM容量は500MBであり、Rubin GPUが搭載する288GBのHBM4と比較するとわずか500分の1に過ぎない。しかし、そのオンチップメモリ帯域幅は150TB/sに達し、Rubin GPUの22TB/sの約7倍の速度でデータの読み書きを実行する。FP8精度でのAI推論計算力は1.2 PFLOPSを備えている。アーキテクチャの内部には、テンソル演算用の行列実行モジュール、ポイントワイズ演算用のベクトル実行モジュール、データの並べ替えを担うスイッチ実行モジュールが独立して配置されている。


ハードウェア側でその場その場の計算順序を決める動的スケジューリングに依存するGPUとは異なり、LPUはコンパイラと呼ばれるソフトウェアがデータの移動と計算のタイミングを事前に完全に決定する決定論的な空間実行モデルを採用している。これにより、チップ間通信のわずかなクロックのズレを吸収し、数百個のプロセッサがまるで一つの巨大なシステムであるかのように同調して動く。実行時の予期せぬ遅延(ジッター)が極限まで排除され、最初のトークンが出力されるまでの時間とそれに続くトークンの生成間隔を極めて安定させることができる。
単体でのメモリ容量の少なさを克服し、1兆パラメータを超える巨大なAIモデルを稼働させるため、NVIDIAはLPUを大規模に並列接続するラックスケールシステム「LPX」を開発した。LPXラックは液冷方式を採用した1Uサイズのコンピュートトレイ32台で構成される。1つのトレイ内には8基のLPU、ホストプロセッサ、そしてファブリック拡張ロジックがケーブルレスで高密度に統合されている。ラック全体に拡張すると、システムは256基のLPUで構成され、総SRAM容量は128GB、チップ間を直接結ぶスケールアップ帯域幅は640TB/sという並外れた仕様に到達する。さらに、ファブリックを経由して最大12TBのDDR5メモリにも接続可能であり、ラック全体のAI推論計算力は315 PFLOPSに及ぶ。このシステムはNVIDIA MGXラックアーキテクチャに準拠しており、データセンター事業者は既存のインフラストラクチャと同じ設計基準で導入を進めることができる。

異種混合アーキテクチャによる推論プロセスの完全分業
NVIDIAの戦略の核は、既存のGPUクラスターをLPUで置き換えることではない。巨大なメモリ容量と並列計算力を持つGPUと、極小の遅延で動くLPUをネットワークレベルで直結させ、推論プロセスの中でそれぞれが得意とする処理を分担させる「異種混合(ヘテロジニアス)アーキテクチャ」の構築である。
この分業体制を実現する中核技術が「Attention-FFN Disaggregation (AFD)」という手法である。推論リクエストが発生すると、オーケストレーションソフトウェアであるNVIDIA Dynamoがワークロードを解析し、計算経路を動的に振り分ける。長大なプロンプトの読み込みとKVキャッシュ(過去の会話内容の一時記憶)の構築を行う重いプレフィルフェーズは、大容量メモリを誇るRubin GPUに割り当てられる。

トークンを生成するデコードフェーズに入ると、処理はGPUとLPXの間を循環する超高速のリレーループに移行する。GPUは構築されたKVキャッシュ全体を見渡すアテンション(注意機構)の処理を担当し、その計算途中の中間出力(アクティベーション)をLPXラックへ転送する。LPX側のLPUは、メモリ帯域幅に強く依存し遅延に敏感なフィードフォワードネットワーク(FFN)や、特定のエキスパートネットワークのみを活性化させるスパースMoEの処理を瞬時に実行し、計算結果を再びGPUへ戻す。このデータ交換を1トークン生成するごとに繰り返すことで、データセンター全体の高いスループットを維持したまま、ユーザーやAIエージェントが体感する応答性を劇的に向上させる。
このアーキテクチャは「スペキュレーティブ・デコーディング」と呼ばれる推論高速化手法の実行環境としても理想的な構造を備えている。計算負荷の軽い小型のドラフトモデルを用いて先のトークン候補を複数予測し、大型のターゲットモデルがそれらを一括で検証・確定する手法である。LPXの圧倒的なSRAM帯域幅を活かしてLPUがドラフトトークンを超高速で生成し、並行してRubin GPUが検証作業を行うことで、遅延を最小限に抑えながら大量のトークンを確実に出力する体制が整う。
サプライチェーンの制約回避とインフラ経済の転換
新アーキテクチャの導入は、AIデータセンターの経済性とNVIDIAのサプライチェーンの両方に地殻変動をもたらす。推論需要が爆発的に増加する中、データセンターは深刻な電力不足と運用コストの高騰に直面している。NVIDIAの算定によれば、1兆パラメータ規模の巨大モデルを使用し、1ユーザーあたり毎秒400トークンという極めて高い応答性が要求されるプレミアムAIサービスを運用した場合、Vera RubinとLPXの組み合わせは前世代のGB200 NVL72と比較して、消費電力(メガワット)あたりの推論スループットが最大35倍に跳ね上がる。同じ電力枠でより多くの高価値なトークンを生成・販売できることは事業者の収益に直結しており、AIインフラの投資に対する収益機会を10倍に拡大する可能性を秘めている。
同時に、SRAMを主体とするLPXの導入は、半導体製造のサプライチェーンにおける深刻なボトルネックを迂回する戦略的意味を持つ。現在、最先端のAI向けGPUの製造は、TSMCが提供するCoWoSと呼ばれる高度なパッケージング技術の生産ラインの逼迫と、HBMメモリの慢性的な供給不足に強く依存している。メモリ価格の高騰がインフラ全体のコストを圧迫する中、HBMや複雑な積層パッケージングを必要としないSRAMベースのLPUでGPUクラスターの演算力を補完するアプローチは、限られた高価な部材への依存度を下げながらシステム全体の性能を底上げする極めて強靭な調達戦略である。
CUDAエコシステムによる推論市場の完全包囲
AI推論専用チップの市場では、CerebrasやSambaNovaといった新興企業が巨大なSRAMを搭載した独自アーキテクチャを武器に先行し、シェアの獲得を進めてきた。GTC 2026の直前には、Amazon Web Servicesが自社のTrainium 3プロセッサでのプロンプト処理と、Cerebrasの巨大SRAMチップ(WSE-3)による低遅延トークン生成を組み合わせた推論基盤の開発を発表するなど、クラウド事業者を巻き込んだ競争は激しさを増している。
NVIDIAによるGroq技術の統合とLPXラックの発表は、こうしたSRAM特化型のライバル勢力に対する強烈なカウンターである。NVIDIAのデータセンター事業を統括するIan Buckは、プレフィル処理に特化したGDDR7搭載の推論専用プロセッサ「Rubin CPX」の優先順位を下げ、現在はLPUとLPXの統合に経営資源を集中させている旨を示唆した。これは、マルチエージェントシステムの普及を見据え、遅延に敏感な推論市場の覇権確保がいかに急務であるかを如実に物語っている。
ハードウェアの物理的な統合にとどまらず、既存のCUDAソフトウェアプラットフォーム上でこの異種混合推論をシームレスに展開できる点がNVIDIAの最大の優位性である。開発者は新しいプログラム言語や全く異なるエコシステムに移行する負担を負うことなく、NVIDIA Dynamoを通じて自動的に最適なプロセッサに計算処理を振り分けることができる。かつてMellanoxの技術を買収してデータセンターのネットワークインフラを自社の支配下に置いたように、NVIDIAは推論という新たな計算のフロンティアを自社のエコシステム内に完全に囲い込もうとしている。AI工場の定義は、単なる膨大な計算資源の集合体から、無数のAIモデルがリアルタイムで連携する精密で超低遅延な神経網へと確実にアップデートされたのだ。
Sources