
AIエージェントとやり取りする際、我々が発する些細なフィードバックや、システムが返すエラーメッセージは、次のアクションのためのコンテキストとして消費された直後、文字通り虚空へと消え去っている。「そこは違う」「もっと親しみやすいトーンで書いてほしい」といったユーザーの反応から、ソフトウェアテストの実行結果に至るまで、エージェントを取り巻く環境は常に豊富なシグナルを発し続けている。しかし、既存の強化学習(RL)システムは、莫大な価値を秘めたこの「次状態シグナル(next-state signals)」を、稼働中の環境からリアルタイムの学習データとして回収する術を持たなかった。
プリンストン大学の研究チームが2026年3月に発表した「OpenClaw-RL」は、この非効率な現状を根底から覆すフレームワークだ。本システムは、デプロイ(運用)とトレーニング(学習)の境界を完全に破壊し、パーソナルアシスタントとの日常的なチャットから、複雑なソフトウェア開発タスクに至るまで、あらゆるインタラクションをAIの自己進化の糧へと変換する。
捨てられていた「2つのシグナル」の回収
従来のエージェント向け強化学習システムは、事前に収集・アノテーション(意味付け)された固定データセットを用いたバッチ処理に依存している。そのため、実稼働中の環境から継続的に学習し、即座に自身の振る舞いを修正することは不可能であった。研究チームは、エージェントの行動の直後に発生するあらゆる次状態シグナルには、2つの決定的な情報がエンコードされているにもかかわらず、それが完全に無駄にされていると指摘する。
一つ目は「評価的シグナル(Evaluative signals)」である。ユーザーが同じ質問を繰り返して回答を拒絶すればそれは不満の表れであり、生成したコードのユニットテストが通れば成功を意味する。これらは、外部から正解データを与えられずとも成立する、行動の質に対する暗黙の評価である。
二つ目は、さらに情報量の多い「指令的シグナル(Directive signals)」である。例えば「ファイルを編集する前に中身を確認すべきだった」というユーザーからの直接的な指摘や、詳細なコンパイラのエラーログは、行動が間違っていたという結果を示すにとどまらず、「トークンレベルで具体的にどう変更すべきだったか」という改善の方向性までも明確に含んでいる。標準的な強化学習における報酬システムは、これらの豊富なフィードバックを単一の数値に圧縮してしまうため、コンテンツレベルの具体的な指示内容を学習に活かせなかった。
完全非同期が生み出す「止まらない学習ループ」
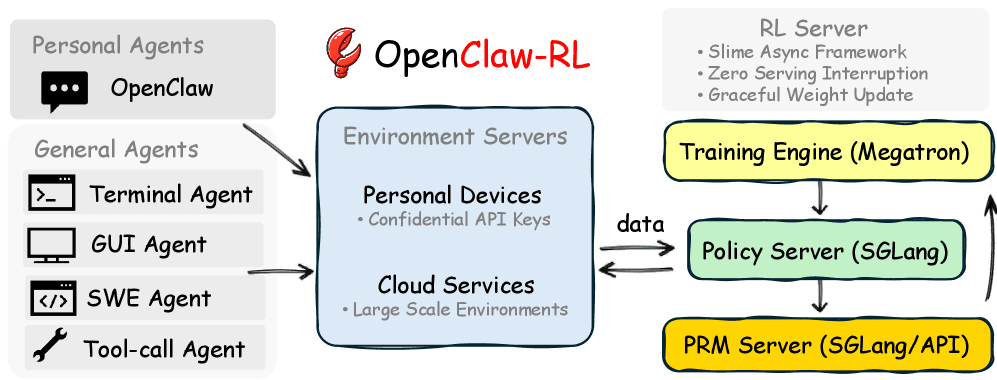
OpenClaw-RLの最大の技術的ブレイクスルーは、システムの推論処理(ユーザーへの応答)を一切妨げることなく、バックグラウンドでポリシー(AIの行動指針)を継続的に更新する「完全非同期アーキテクチャ」の実現にある。
このシステムは、「slime」と呼ばれる大規模言語モデル向けの非同期強化学習インフラストラクチャの上に構築されている。内部では4つのコンポーネントが完全に分離され、それぞれ独立したループとして稼働する。まず、環境サーバーがユーザーのパーソナルデバイスやクラウド上の汎用エージェント実行環境として働き、HTTP経由でセキュアにリクエストを送信する。次に、ポリシー提供モジュールがSGLangを用いてリクエストに対し即座にAIモデルの推論結果を返す。それと並行して、報酬判定モジュールが同じくSGLangおよびAPIを利用し、直前の応答に対する次状態シグナルを基にバックグラウンドでプロセス報酬を計算する。最後に、ポリシー学習モジュールがMegatronエンジンを駆動し、蓄積されたシグナルを基にニューラルネットワークの重みを更新する。
エージェントが次のユーザーリクエストに応答している裏で、評価モデルが直前の応答を採点し、トレーニングエンジンが学習を進める。各モジュールが互いの処理完了を待つ必要がないため、個人のスマートフォン上でのローカル動作から、128の並列環境を同時に回すクラウド上の大規模なターミナルエージェント環境まで、遅延なくシームレスにスケールする。利用を中断してデータをバッチ処理し、再デプロイするといった従来の煩雑な手順は過去のものとなる。
2つの革新的な最適化エンジン:スカラー報酬とトークンレベルの勾配
OpenClaw-RLは、回収した未加工のシグナルをAIの学習方向を定める勾配へと変換するために、2つの相補的な学習手法を採用し、それらを統合している。
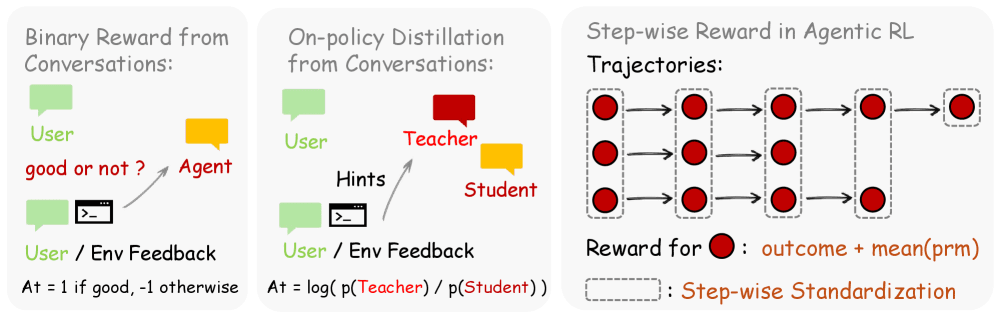
第一の手法が「Binary RL」である。ユーザーの返答やツールの実行結果を受け取ると、プロセス報酬モデル(PRM)が各ターンを「良い(+1)」「悪い(-1)」「中立(0)」のいずれかに分類する。ツールの実行結果は明確な結論を導きやすいが、ユーザーの反応が曖昧な場合でも、文脈から満足度を推定してスコアリングを行う。この分類結果は、GRPO(Group Relative Policy Optimization)に似たPPOスタイルの損失関数においてシーケンスレベル(応答全体)のスカラー報酬となり、ベースラインとなる広範な学習シグナルを提供する。
第二の手法が、OpenClaw-RLの中核をなす「Hindsight-Guided On-Policy Distillation(OPD)」である。前述の指令的シグナルを処理するためのこの手法は、評価モデルを用いてフィードバックから1〜3文程度の具体的な「ヒント(改善指示)」を抽出する。システムはここで厳格な品質フィルターをかけ、10文字以上の情報量の多いヒントのみを学習に採用する。
次に、抽出されたヒントを「あたかもユーザーが最初からプロンプトに含めていたかのように」文脈を拡張し、AIモデル自身に正解を知っていた場合の理想的な回答を生成させる。この「ヒントを与えられた状態の教師の確率分布」と、「実際の生徒(元のAI)の出力」との間の対数確率のギャップを計算し、トークン(単語の断片)ごとの詳細な方向性データを得る。応答全体を一律に評価するのではなく、「この単語は採用すべきだった」「この表現は避けるべきだった」というミクロなレベルでの修正を自己蒸留によって行う構造だ。外部のより強力な教師モデルや、人間が手作業で作成したペアデータセットを一切必要としない。
パーソナルエージェントの超進化:数十回の会話で消える「AI臭」
この2つの手法を組み合わせた「Combined Method」の効果は、個人のユーザーの好みに合わせるパーソナライゼーションの領域において劇的な結果をもたらした。
研究チームは、パラメータ数40億のQwen3-4BモデルをベースにしたオープンソースのAIアシスタント「OpenClaw」を用い、2つのシミュレーションを実施した。一つは、AIを使っていることを隠しながら宿題をこなしたい「学生」の設定。もう一つは、生徒に対して具体的かつ親しみやすいフィードバックを返したい「教師」の設定である。
初期状態のOpenClawは、箇条書きを多用し、特定の単語を過剰に強調するような、典型的な機械生成の不自然な文章を出力していた。しかし最適化を適用した結果、学生の設定ではわずか36回の問題解決のやり取りを経ただけで、明確な変化が現れた。AI特有のステップ・バイ・ステップの堅苦しい構造が崩れ、より自然でカジュアルな文体を獲得したのである。パーソナライゼーションの度合いを示すスコアは、初期の0.17から0.76へと跳ね上がった。
教師の設定においても、24回の採点作業をこなしただけでスコアが0.22から0.90へと急上昇した。定型文のような短いコメントしか出力しなかったモデルが、生徒の計算過程のどの部分が優れていたのかを具体的に指摘し、絵文字を交えた親しみやすいフィードバックを自発的に生成するようになった。
Binary RLのみ、あるいはOPDのみを用いた場合と比較し、両者を重み付けして統合したCombined Methodが最も速く、かつ高い到達点を示した。Binary RLがすべてのターンで粗く広範なフィードバックを捉え、OPDが明確な修正指示を含むターンにおいてトークンレベルの精密な軌道修正を行うことで、エージェントは利用開始からわずか1日の終わりには、ユーザーの個人的な文体や好みを完全に把握した専用のアシスタントへと変貌を遂げる。
汎用エージェントへの拡張:プロセス報酬が支える長期タスクの遂行
OpenClaw-RLの適用範囲は、単一ユーザー向けのチャットアシスタントに限定されない。ターミナル環境でのシェル実行、視覚的な状態変化を伴うGUIの操作、コードリポジトリとテストスイートを行き来するソフトウェアエンジニアリング(SWE)、そして外部APIを呼び出すツールコールといった、実世界の複雑な汎用エージェントに対しても適用できる。
これらの汎用エージェントが直面するのは、数十回のステップを経てようやく目的が達成されるロングホライズン(長期的な視野を要する)タスクである。最終的な結果(成功か失敗か)だけを学習の報酬とする従来の手法では、途中のどの行動が正しく、どの行動が間違っていたのかというクレジットの割り当てが機能せず、大部分の行動が未評価のまま放置されてしまう。
OpenClaw-RLは、各ステップで発生する環境からの出力(標準出力・標準エラー、GUIの視覚的な状態変化、テスト結果、APIの戻り値など)をライブの次状態シグナルとして捉え、ステップごとのプロセス報酬を緻密に付与していく。実験では、Qwen3-8Bモデル等を使用し、大規模なクラウド環境で並列学習を行わせた結果、ターミナルエージェントのタスク達成精度は100ステップの学習で約0.17から0.50弱へと劇的に向上した。また、SWE環境では初期の低下を経て35ステップで0.05から0.18へ、ツールコール環境においては250ステップで0.08から0.17へと倍増以上の成果を示している。
特にツールコール(250ステップ)およびGUI(120ステップ)の環境において、最終的な結果報酬のみを用いた場合と、プロセス報酬を統合した場合を比較する実験も行われた。結果報酬のみのGUIエージェントのスコアが0.31であったのに対し、統合型は0.33を記録し、ツールコール環境では0.17に対して0.30と圧倒的な差をつけた。環境のホスティングとPRMの実行に追加の計算資源を要求するものの、プロセス報酬と結果報酬を統合するアプローチが複雑な実環境下でのエージェントの学習に不可欠であることを証明している。
継続的進化がもたらすパラダイムシフトと今後の展望
AI業界の関心の中心は現在、大規模言語モデルの推論能力の向上から、エージェントが自律的に学習ループを回し続けるアーキテクチャの構築へと完全に移行している。テクノロジーアナリストのAnthony Alcarazは、エージェントが再帰的にコードを生成し、インフラを自ら評価しながら性能を向上させていく「Compounding intelligence stack(複利的に進化する知能スタック)」という概念を提唱している。OpenClaw-RLは、このスタックにおいて最も欠けていた「評価と学習のシームレスな統合」を具現化するピースである。
これまで、自己改善型のエージェントを実稼働させる上での最大の障壁は、学習のための良質な評価データをいかに低コストで継続的に収集するかという点にあった。しかしOpenClaw-RLは、特別な評価システムや人間のアノテーターを用意せずとも、ライブ環境でのインタラクションそのものの中に、AIを向上させるためのシグナルがすでに豊富に埋め込まれている事実を証明した。データ回収のインフラストラクチャを整備し、適切なアルゴリズムを通すだけで、エージェントは自らの失敗やユーザーとの摩擦をエネルギーに変換して進化し始める。
残された技術的課題は、継続的な学習によってモデルが極端に偏った最適化を引き起こしたり、過去に獲得した有用な能力が上書きされてしまう「破局的忘却」や「退行」の防止である。しかし、リアルタイムのオンライン強化学習は、ベースとなるポリシーから極端に逸脱しない特性を設計上備えている。さらに、特定の検証済み知識を上書きから保護するニューロシンボリックなフリーズレイヤー技術などとの組み合わせがすでに議論され始めており、継続的学習を真の意味での「複利的な進化」へと昇華させる道筋は見えつつある。
「デプロイ」という言葉が、完成された固定のソフトウェアを世に送り出すことを意味した時代は終わりを告げようとしている。ユーザーとの対話や未知の環境での失敗から息を吸うように学習し、翌日には全く異なる適応力を見せるエージェントの誕生は、AIと人間のインターフェースのあり方を根本から再定義する。
論文
参考文献
- GitHub: Gen-Verse / OpenClaw-RL
- via The Decoder: OpenClaw-RL trains AI agents “simply by talking,” converting every reply into a training signal