
近年、オープンソースの大規模言語モデル(LLM)の性能向上は著しく、数百億から数千億パラメータクラスのモデルが次々と公開されている。しかし、これらの高度な推論能力をローカル環境で活用しようとする開発者や研究者の前に立ちはだかるのが、物理的なGPUのビデオメモリ(VRAM)容量の壁である。例えば、約31.8GBのメモリ領域を要求する「glm-4.7-flash:q8_0」のようなモデルをコンシューマー向けのハードウェア単体で稼働させることは、これまで極めて困難を極めた。
従来の解決策は主に2つのアプローチに依存していた。1つは、あふれたニューラルネットワークのレイヤーをCPU側のシステムメモリにオフロードする手法である。しかし、CPUのシステムメモリはCUDAコヒーレンスを持たないため、GPUとCPU間で複雑かつ大量のデータやり取りが発生し、深刻なボトルネックとなる。事実、トークン生成速度はVRAM単体で実行する場合と比較して5倍から10倍の速度低下を引き起こし、実用的なインタラクションを損なう。もう1つの手段は、モデルの量子化レベルを極端に下げることであるが、これは推論能力や論理的思考能力の著しい劣化を伴うトレードオフが存在する。もちろん、48GB以上の広大なVRAMを備えたエンタープライズ向けのGPUを導入するという選択肢もあるが、これはワークステーション一式を上回るコストを要求し、個人の開発者や資金力に乏しいスタートアップにとっては現実的とは言い難い。
こうした構造的なジレンマに対し、独立系オープンソース開発者であるFerran Duarri氏が全く未知のアプローチのハードウェアハックを提示した。これが、NVIDIAのディスクリートGPUの専用ビデオメモリを、マザーボード上のシステムメモリ(DDR4やDDR5)および高速なNVMeストレージと統合し、大規模な外部拡張メモリとして扱うLinuxカーネルモジュール「GreenBoost」である。
GreenBoostがもたらすアーキテクチャの転換:3層メモリ階層の実装
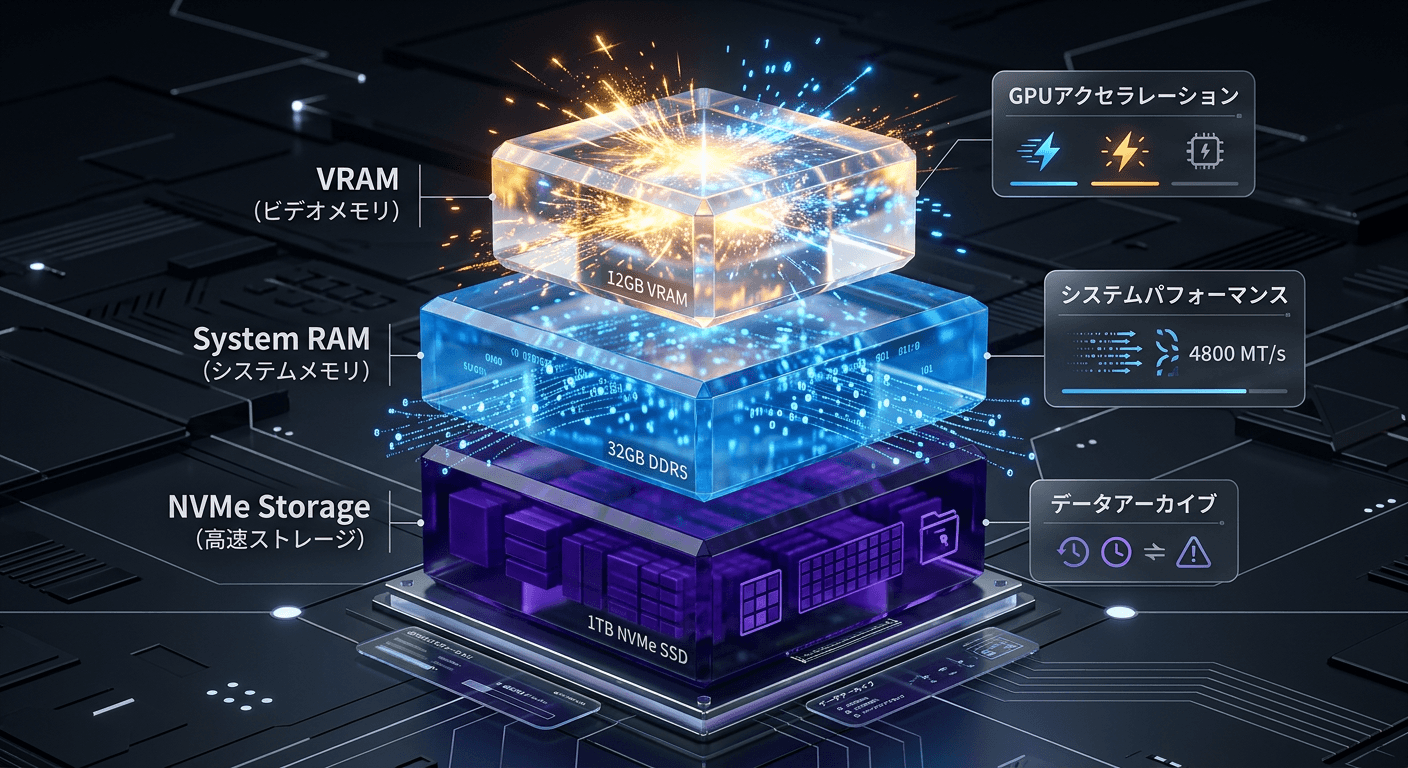
GreenBoostは、単なる仮想GPUソリューションや既存のNVIDIAドライバーをパッチで書き換えるような一時的なハックではない。GPLv2ライセンスの下で公開され、公式のNVIDIAカーネルドライバー(nvidia.ko、nvidia-uvm.ko)と並行して独立して動作するカーネルモジュールとして丁寧に設計されている。その中核的なアイデアは、CUDAのメモリ割り当てレイヤーの根幹に介入し、マザーボード上のシステムRAMを「外部メモリ」としてGPUドライバに直接認識させることにある。これにより、ユーザー空間で稼働するCUDAアプリケーションや推論ソフトウェア(Ollamaなど)のソースコードを一行たりとも変更することなく、シームレスに拡張された広大なメモリ空間を横断的に利用できるアーキテクチャを実現した。
具体的には、GreenBoostはシステム全体の記憶領域を3つのメモリ階層に分割して動的に管理する。第一階層(T1)はGPUに元から実装されている本来のVRAMであり、テスト環境であるGeForce RTX 5070の場合は12GBの容量を持ち、約336GB/sという極めて高いデータ転送帯域幅でのアクセスを提供する。ここは計算のホットパスであり、最もアクセス頻度の高い推論中のアクティブなレイヤーを保持する。
第二階層(T2)はマザーボード上のDDR4あるいはDDR5システムRAMであり、PCIe 4.0 x16リンクを通じて約32GB/sの速度でGPUとデータリンクを確立する。この階層は、モデルの静的な重みデータの一部や、LLMが長大なコンテキストを維持・参照するために必要不可欠なKV(Key-Value)キャッシュの巨大な保存領域として機能する。
最後の安全網となるのが第三階層(T3)のNVMeストレージである。約1.8GB/sの比較的緩慢なスワップ空間として割り当てられており、VRAMとシステムRAMの両方が完全に枯渇した例外的な際のオーバーフローを吸収する役割を果たすようマッピングされている。
この緻密な階層構造プロビジョニングにより、AIモデルの全パラメータ群が物理VRAMに収まりきらない過酷なスケールの要求であっても、重要度の限定されたデータや非同期バッチ処理の待機データのみを下位のコストパフォーマンスに優れたプロセスとメモリ階層に待避させることで、演算全体のスループット低下を最小限に抑え込む設計となっているのである。
バックグラウンドのメカニズム:DMA-BUFとCUDAフックの連携
GreenBoostの技術的な洗練さは、権限の異なるカーネル空間とユーザー空間のコンポーネントがどのように相互干渉を起こすことなく協調動作するかに明確に表れている。基盤となるカーネルモジュール(greenboost.ko)は、ページングのオーバーヘッドとメモリフラグメンテーションなどの影響による効率低下を排除するためにバディアロケータを用いて2MBの巨大な複合ページ空間としてDDR4メモリの領域を確保し、それらを直接メモリアクセスのためのDMA-BUF(Direct Memory Access Buffer)ファイルディスクリプタとしてエクスポートする。
続いて、推論を実行するGPUサイドは「cudaImportExternalMemory」APIを通じてオペレーティングシステムからこれらのページをCUDAの外部メモリとして正式にインポートし自身のメモリ空間へマウントを遂行する。この一連のカーネルプロセスにより、CUDAプラットフォームからは先ほど確保されたDDR4の物理ページ群があたかもグラフィックスカードの基板上に配置されたGPU直結メモリであるかのように錯覚して認識され、途中にシステムのメインボードアーキテクチャが介在している事実は完全に隠蔽される仕組みである。実体としてのデータの移動自体はPCI Express 4.0バスリンク上のDMA転送として独立して処理されるため、ホストプロセッサであるCPUの介在による不要かつ冗長なメモリコピーサイクルは一切発生しない。
一方、アプリケーションが動作するユーザー空間では「libgreenboost_cuda.so」と名付けられた共有フックライブラリがシステムの鍵を握る。Linux OS独自の機能である「LD_PRELOAD」環境変数機構を利用して推論エンジンのバイナリ実行時にメモリアドレス上位へと動的に差し込まれるこのライブラリは、「cudaMalloc」や「cudaFree」をはじめとするメモリ割り当てのトリガーとなる一連のAPI呼び出しを密かにインターセプト(傍受)する。
このインターセプトポイントにおいて、GreenBoostはインテリジェントなルーティングプロトコルを実行する。閾値である256MB未満の比較的小さなメモリアロケーションリクエストは横取りせず正規のCUDAランタイムへと素通りさせ、遅延のない本来のVRAM上で処理させる。しかし、モデルの重みレイヤーデータや生成フェーズで肥大化する大容量のKVキャッシュなど、VRAMの物理的な容量限界を脅かすような大規模なアロケーション要求を検知した瞬間、そのリクエストはGreenBoostのカーネルモジュールへとリダイレクトされ、先ほどエクスポートされたシステムRAMのプールから必要量を確保し、CUDAの正規のデバイスポインタとしてアプリケーションに返却されるのである。
推論エンジンの中には、Ollamaのように内部システムで「dlopen」や「dlsym」を使用し、ランタイム中に動的にCUDA関連の実行可能シンボルを解決して呼び出すアプローチを採用するものも存在する。このケースに置いては、静的に設定された単純なLD_PRELOADフックは迂回されて機能不全に陥ってしまうが、GreenBoost側はここにも対策を施している。POSIX標準の関数であるdlsym自体をインターセプトし、自身の関数のポインタをリダイレクトさせるという極めてハッカー的で大胆なオペレーションによりこのシステム制限を乗り越えているのである。さらには、GPUが実際に搭載している物理VRAM量(例えば検証機の12GB)を問い合わせるシステムコール「cuDeviceTotalMem_v2」などの情報取得関数にもフックを仕掛け、物理容量を意図的にパッチし推論エンジンにより大きな見かけのメモリ容量(たとえば利用可能なDRAMを含めた64GBなど)を報告することで、エンジンが自発的かつ意図せざるCPUオフロードへと移行することを強制的に防ぐ処置も内包されている。
エコシステムへの統合:ExLlamaV3やModelOptとの相乗効果
GreenBoostは単独での利用にとどまらず、最新の推論アプローチとの統合を前提とし、パフォーマンスを最大化するための多角的な最適化ツールチェーンが同時に提供されている。
例えば、ネイティブでGreenBoostの提供するKVキャッシュレイヤーパスに対応した最適化推論エンジン「ExLlamaV3」を利用した場合、モデルのKVテンソルを「/dev/greenboost」からゼロコピーのmmapアクセスを経由してPythonへ直接割り当てることが可能になる。これにより、I/Oオーバーヘッドをほぼ完全に回避しスループットが向上する。さらに、ランタイムKV圧縮ツール「kvpress」と連動させれば、10万トークンを超える長大なコンテキストを維持する際のシステムRAMパス帯域幅への圧迫を大幅に緩和できる。計算資源の制約が厳しいシステムにとって、これは決定的な差をもたらす。
より根本的なブレイクスルーをもたらすのが、NVIDIA公式のモデル最適化ツールである「NVIDIA ModelOpt」との連携だ。Post-Training Quantization(トレーニング後量子化)を用いて、31.8GBのモデルに対して再学習処理を行うことなく高効率なFP8形式へと変換すれば、モデルサイズを約16GB未満へと劇的に圧縮できる。
この圧縮とExLlamaV3を基盤とし、重み本体にはVRAMエリアを、そしてシステムRAMを大規模なKVキャッシュ用に割り当てるというGreenBoostのエッジ手法を組み合わせた場合、GeForce RTX 5070の本来の演算・転送性能をスポイルせず最大限に引き出しながら、1秒間に平均10〜25個のトークン(10-25 tok/s)推論速度を得ることが可能となる。これはDuarri氏自身が行ったテストで実証されており、単純なOllama上でベースライン環境(2〜5 tok/s)に留まっていた速度から数倍のジャンプアップを達成している。
性能と実用性の境界線:PCIe 4.0の帯域幅が意味するもの
GreenBoostの登場はPCでのローカルLLM運用における革新的な手法であるが、ハードウェアの根本的な物理制約を無力化する銀の弾丸ではない。Duarri氏自身も率直にドキュメントに記載している通り、最大かつ不可避のボトルネックはPCIe 4.0 x16バスにおける最大実効約32GB/sの転送帯域幅の制限にこそ存在する。
昨今のディスクリートGPUのVRAMオンボードチップの内部転送帯域幅が最低でも数百GB/s、ハイエンドクラスでは1TB/sを超過してモデルの演算アクセスを支えているのと比較し、システムRAMへのPCIe経由でのアクセス速度は物理的にその10分の1未満に過ぎない事実を忘れてはならない。推論フェーズにおいて、アクセス頻度の高いモデルのコアとなる重みデータが秒間に幾度もVRAMとシステムRAMの間を行き来する状態、オペレーティングシステムで言うところのスラッシング状態に一度陥れば、この限られたPCIeリンク幅自体がパイプラインの決定的な遅延要因となる。
さらに最下総の第三層であるNVMeへのスワップ領域に関しても、SSDドライブは大規模なシーケンシャルアクセスにこそ特化しているものの、推論プロセスでの小さなチャンクの数百万回のランダムアクセス処理においてはSSDコントローラーの性質上、性能の劇的な低下を招くことは避けられない。
真の意味でGreenBoostというシステムのポテンシャルを享受するための「最適解の設計」は、単一のモジュールに依存するアプローチではない。FP8やINT4-AWQといった最新のパラメータ量子化技術などを事前パイプラインとして駆使してモデルの重みデータそのものは極限まで削り落としVRAM内部(第一階層)に全量収納し、一方で随時肥大化してゆくコンテキスト依存のKVキャッシュ領域に関してのみDDR4モジュールのストレージ(第二階層)へと広大に逃がすという、ワークロードの分割にこそある。
次世代AIインフラストラクチャへの示唆
「GreenBoost」のオープンソースコードベースとしての提供は、コンシューマー向けGPUセグメントにおいて演算能力自体は極めて高いが、搭載VRAMの少容量化によって産業利用が意図的に制約されているという市場ヒエラルキーの構造に対する、開発者コミュニティ側からのボトムアップの強いアンチテーゼである。これはある意味、Appleがユニファイドメモリというシステムアーキテクチャの統一によって、高価なHBMモジュールを積まずともMシリーズチップ上で数十GBの広大なメモリ空間を用いた巨大AI推論の実行可能性を実証した体験を、ソフトウェア・アロケーション技術を用いて既存のバラバラなPCプラットフォームのコンポーネント上で擬似的に結合エミュレートする試みである。
この実装手法は、高騰の一途を辿り続けるエンタープライズ向けAIアクセラレータに対する、個人のリサーチャーや中小規模のAI開発エコシステムにおける強力な対抗手段となり得る。現時点においては、NVIDIAのBlackwell世代(Compute Capability 12.0)の中心的存在であるGeForce RTX 5070での動作・テスト結果によって実証されている段階ではあるものの、ソースコードが公開されたことで今後は前世代のAda LovelaceアーキテクチャやAmpere世代のカードを所有する広範なユーザーによるコミュニティベースの検証とフォークが進む。
ハードウェア自体の物理的な増設による強引なスケールアップ・アプローチが一つの壁に到達している現在において、OSのカーネル管理層からPCI-Express周辺インターフェース、そしてCUDAのユーザー空間ランタイムといったブラックボックスとなりがちな階層を巧みに横断、ハックするFerran Duarri氏のアプローチは、今後不可避である分散実行型の新しいAIインフラストラクチャが直面しなければならないメモリマネージメント課題の具体的なヒントを開示している。ローカルPC環境のLLM運用において、絶対的なVRAM容量への依存という課題がすぐに氷解するわけではないが、世界中の開発者たちは着実にその「壁」のバイパスを開拓しつつある。
Sources


