
18%以上の電力削減と9%以上の性能向上という数字が、Intel Foundryを再び先端プロセス競争の中心へ押し戻している。VLSI 2026で示されたIntel 18A-Pは、RibbonFETとPowerViaを土台にした18Aの改良版だ。一方で、TSMC N2はトランジスタ密度でIntel 18Aを上回り、先端製造の主導権を握る。そこへAppleのM系入門版評価、Googleの先端パッケージング検討という報道が重なり、勝負の軸は「最も細かいプロセス」から「十分な効率と供給分散」へ広がり始めた。
18A-Pは電力、性能、設計ライブラリを同時に伸ばす
VLSI 2026で示されたIntel 18A-Pは、同じ性能なら18%以上低い電力で動き、同じ電力なら9%以上高い性能を出す。Intelの説明では、この改善はトランジスタ性能、配線、設計技術の共同最適化によるものだ。18A-Pは18Aの改良版であり、RibbonFETとPowerViaという2つの中核技術を引き継ぐ。Intel Foundryにとって、この数字は外部顧客へ提示できる最初の強い材料だ。
高密度ライブラリと高性能ライブラリの両対応は、チップ設計者に面積と速度の選択肢を与える。高密度ライブラリは同じ面積へより多い回路を詰め込み、高性能ライブラリは周波数や応答速度を優先する設計に向く。
追加のしきい値電圧(VT)ペアは、リーク電流を抑えるセルと高速動作を狙うセルの使い分けを細かくする仕組みだ。18Aからスキューコーナーが30%改善した点も、製造ばらつきに対する設計マージンを広げる要素になる。
RibbonFETとPowerViaが電流と信号の渋滞を分ける
RibbonFETはGate-All-Around(GAA)型トランジスタで、ゲートがチャネルを四方から囲む構造を取る。従来のFin Field-Effect Transistor(FinFET)は、立体的なフィンの複数面をゲートで制御していた。GAAでは電流が流れる薄いリボンをゲートが包み込むため、オンとオフの切り替えをより厳密に制御しやすい。微細化でリーク電流が増えやすい世代ほど、この制御性が電力効率に効いてくる。
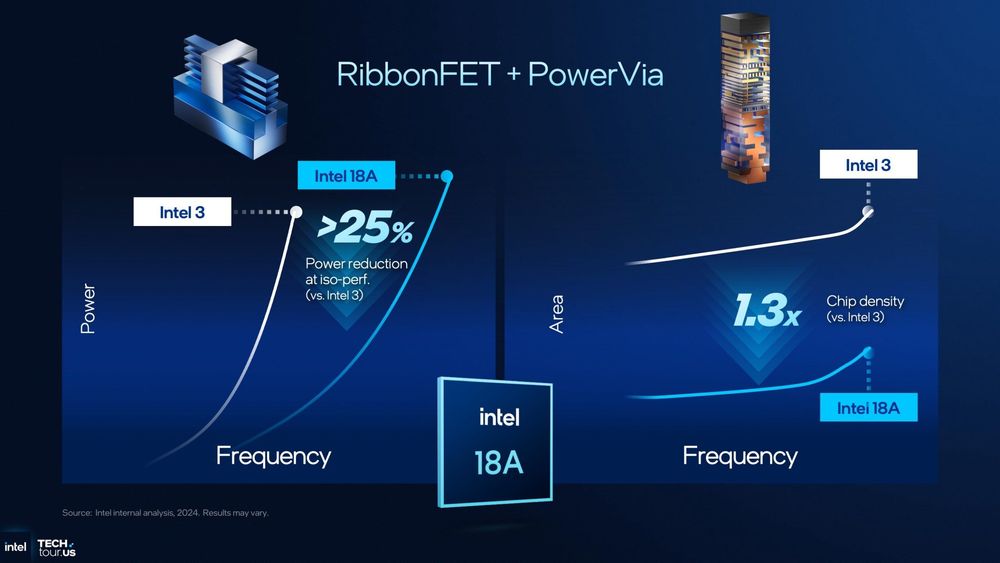
PowerViaは、電力を供給する配線をウェハーの裏面へ移す裏面電力供給技術だ。従来のチップでは、信号配線と電力配線が同じ表面側の層を取り合い、配線抵抗や混雑が性能を制限していた。電力配線を裏面へ逃がすと、表面側は信号配線に使いやすくなり、電圧降下も抑えやすい。この2つの技術が積み重なることで、18A-Pが示す「18%以上低電力・9%以上高性能」という数字の土台が生まれる。
密度のTSMC N2、効率のIntel 18A-Pという分岐
明らかにされている情報によると、TSMC N2のトランジスタ密度は313MTr/mm²、Intel 18Aは238MTr/mm²とされる。密度だけを見れば、TSMC N2がIntel 18Aを上回る。一方で、Intel 18A系はIntel 3比で30%以上の密度改善を示し、18A-Pでは電力と性能の上積みを訴求する。先端ノードの競争は、面積、電力、速度、供給能力を分けて見る必要がある。主要指標を比較すると次のようになる。
| 項目 | Intel 18A / 18A-P | TSMC N2 |
|---|---|---|
| トランジスタ密度 | 238MTr/mm²(18A) | 313MTr/mm² |
| 電力効率 | 18A-Pで同性能時18%以上低電力 | N3E比で24〜35%低電力 |
| 性能 | 18A-Pで同電力時9%以上向上 | N3E比で14〜15%向上 |
| 構造 | RibbonFET、PowerVia | GAA世代 |
| 位置づけ | 効率と裏面電力供給を訴求 | 密度と量産実績を訴求 |
TSMC N2はN3E比で24〜35%の消費電力削減、14〜15%の性能向上、1.15倍の密度向上を掲げる。Intel 18A-Pの18%以上低電力という数字は、TSMC N2との直接比較ではなく、Intel側の18A系改良として読むべきだ。密度で差がある以上、Intelは面積あたりのトランジスタ数で真正面から勝つ構図ではない。18A-Pの意味は、密度差を効率、設計自由度、先端パッケージングとの組み合わせで補えるかにある。
AppleとGoogleの検討報道は供給分散のシグナルだ
以前、AppleがIntel 18A-PをM系チップの入門レベル版向けに評価していると報じられていた。対象として挙げられているのは、MacBook AirやiPad Pro向けのM系チップだ。生産時期は2027年第2四半期から第3四半期ごろとの見方がある。だがこれに関してはAppleから公式声明は出ておらず、現時点では採用決定ではなく評価段階の報道として扱う必要がある。
加えて、Googleが次世代Tensor Processing Unit(TPU)向けにIntelのEmbedded Multi-die Interconnect Bridge(EMIB)を検討しているとも報じられている。EMIBは、複数の半導体ダイを基板上で高密度に接続するIntelの先端パッケージング技術だ。報道ではTPUv8eとTPUv9の表記が混在しており、世代名は確定情報として扱えない。重要なのは、Googleの関心が製造プロセス単体ではなく、AIアクセラレータを組み上げるパッケージング技術にも向いている点だ。
赤字のIntel Foundryが越える量産証明の壁
Intel Foundryの2026年第1四半期営業損失は24億ドルで、前四半期から7200万ドル改善した。損失規模は依然として大きく、外部顧客の量産案件を積み上げなければ事業の見え方は変わらない。Intelは2026年時点で複数顧客と協議中であり、18A-Pの早期ウェハーはすでにファブ内にあると説明している。技術発表から量産実績へ移る段階で、歩留まり、納期、設計支援の完成度が問われる。
Lip-Bu Tan CEOは、推論向け人工知能(AI)とエージェントAIの拡大で、中央処理装置(CPU)と画像処理装置(GPU)の比率が従来の1対8から1対1へ向かっていると述べた。この見立てが正しければ、サーバーCPU需要は再び強まり、Intelの設計資産と製造資産が結びつく余地が広がる。AI時代の半導体需要はGPU中心に見られがちだが、推論処理、データ準備、制御処理にはCPUの能力も必要になる。Intel Foundryにとって、18A-PはAIインフラの周辺需要を取り込む入口にもなる。
18A-Pの成否は、TSMC N2を密度で上回るかでは決まらない。AppleやGoogleの検討報道が示すのは、大手テック企業が先端ノードの調達先とパッケージング選択肢を分散させようとしている動きだ。Intel Foundryがこの機会を量産実績へ変えられれば、先端半導体市場はTSMC一強から、用途別に最適な製造・実装先を選ぶ競争へ進む。