AI開発の最前線を走るAnthropic社が、自社のAI「Claude」に搭載した革新的な研究システム「マルチエージェントリサーチシステム」の詳細を公開した。
このシステムは、一人のAIが単独で頑張るのではなく、複数のAIが「チーム」を組み、それぞれが役割を分担して複雑なタスクを解決するというものだ。それはまるで、優秀なプロジェクトリーダーが専門家チームを率いて、一つの大きな目標に挑む姿そのものと言える。
この記事では、Anthropicが明かした「チームで働くAI」の仕組みを解説する。なぜこのシステムは従来の手法より90%以上も高性能なのか?その驚異的な性能の裏側にある「AIの働き方改革」の一端を覗いてみよう。
AIの働き方改革:指揮官と専門家チームによる「分業」
このシステムの核心を理解する鍵は、人間社会における最も効率的なプロジェクトチームの姿を思い浮かべることにある。それは「戦略的な分業」だ。
想像してみてほしい。あるコンサルティング会社が、クライアントから「世界の半導体市場の今後5年間の動向を、競合他社の戦略も含めて詳細にレポートせよ」という極めて複雑な依頼を受けたとしよう。この難題に、一人のコンサルタントだけで立ち向かうのは無謀だ。通常は、経験豊富なプロジェクトリーダーが任命され、まず依頼内容を分析し、調査すべき項目を「技術動向」「主要企業の財務分析」「地政学的リスク」「サプライチェーン」といった具体的なタスクに分解する。そして、それぞれの分野の専門家を集め、「君は技術特許の分析を」「君はA社の財務諸表を」「君は台湾情勢のレポートを」と的確に作業を割り振る。専門家たちは、それぞれの持ち場で同時に調査を進め、その知見をリーダーに報告する。最終的に、リーダーがそれらの断片的な情報を統合し、多角的な視点から一貫性のある洞察に満ちた最終レポートを編み上げるのだ。
Anthropicのマルチエージェントシステムは、この知的生産のプロセスを、驚くほど忠実にAIで再現している。
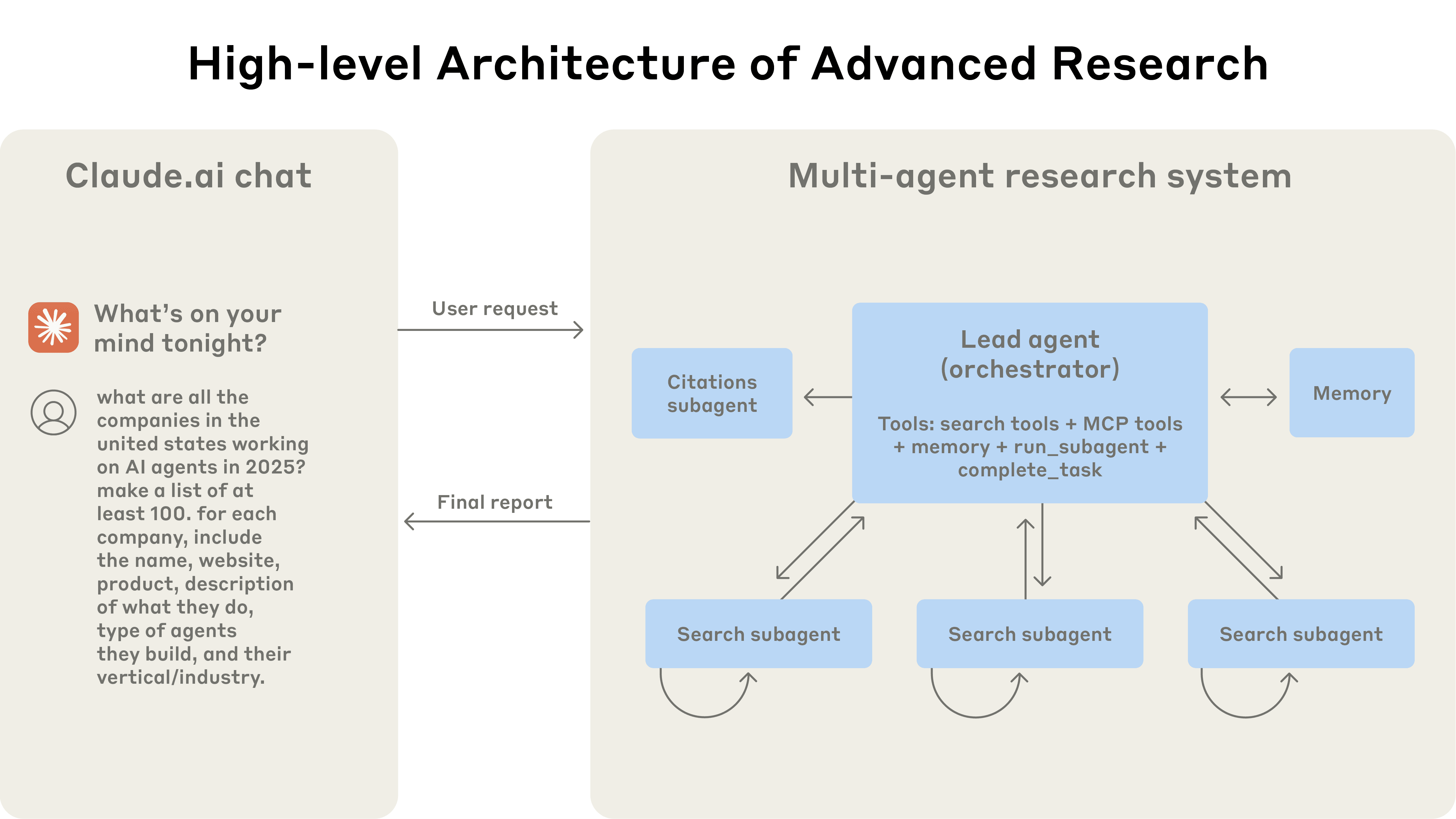
- リードエージェント(指揮官): システムの中核を担うのは、Anthropicの最も高性能なモデル「Claude 4 Opus」だ。このAIは、ユーザーからの広範で複雑な質問を受け取ると、まずそれを達成するための全体戦略を思考する。そして、その戦略に基づいて複数の具体的なサブタスクへと分解し、それぞれのタスクに最適な「サブエージェント」を生成して、明確な指示を与える。
- サブエージェント(専門家): リードエージェントの指示を受け、実働部隊として動くのが、より軽量で効率的なモデル「Claude 4 Sonnet」だ。彼らはそれぞれが独立した調査担当者のように振る舞う。例えば、「IT業界のS&P500構成企業の役員を全員リストアップして」という巨大なタスクなら、「A社の役員を調査」「B社の役員を調査」といった形で、複数のサブエージェントが並行してウェブ検索などのツールを駆使し、作業を分担する。これにより、一人が順次行うよりも圧倒的に早く、かつ網羅的に情報を収集できる。
- 情報の統合: 各サブエージェントからの調査報告が揃うと、再びリードエージェントの出番となる。彼は集まってきた情報を吟味し、重複を排除し、矛盾点を確認しながら、一つの論理的で完成された回答へと統合していく。まさに、プロジェクトリーダーがチームの成果を最終報告書にまとめる作業そのものである。
この「指揮官と専門家」という階層的なチーム体制こそが、AIが一人の天才プレイヤーから、組織的な課題解決能力を持つチームへと進化したことを示す、何よりの証拠なのである。
驚異の性能の裏側:なぜ90%も賢くなったのか?
Anthropicの内部評価によると、このマルチエージェントシステムは、単独のAI(Claude 4 Opus)に比べて実に90.2%も性能が向上したという。この飛躍的な進歩は、いくつかの要因によってもたらされている。
1. 「思考量」への大胆な投資
最も大きな理由は、AIが情報を処理するために使うエネルギー、すなわち「トークン消費量」にある。このシステムは、通常のチャット対話に比べて約15倍ものトークンを消費する。
これは、一見すると非効率に思えるかもしれない。しかし、「質の高い成果のためには、相応のコストをかける」という、ある意味で人間社会と同じ原則に基づいている。チームで仕事をする際、メンバー間のコミュニケーションや資料の共有でコストが増えるのと同じだ。このシステムは、膨大なトークンを「思考力」として投資することで、一人では不可能なレベルの深い分析と広範な情報収集を可能にしているのだ。
2. 「並列処理」による圧倒的なスピード
このシステムの真価は、そのスピードにある。
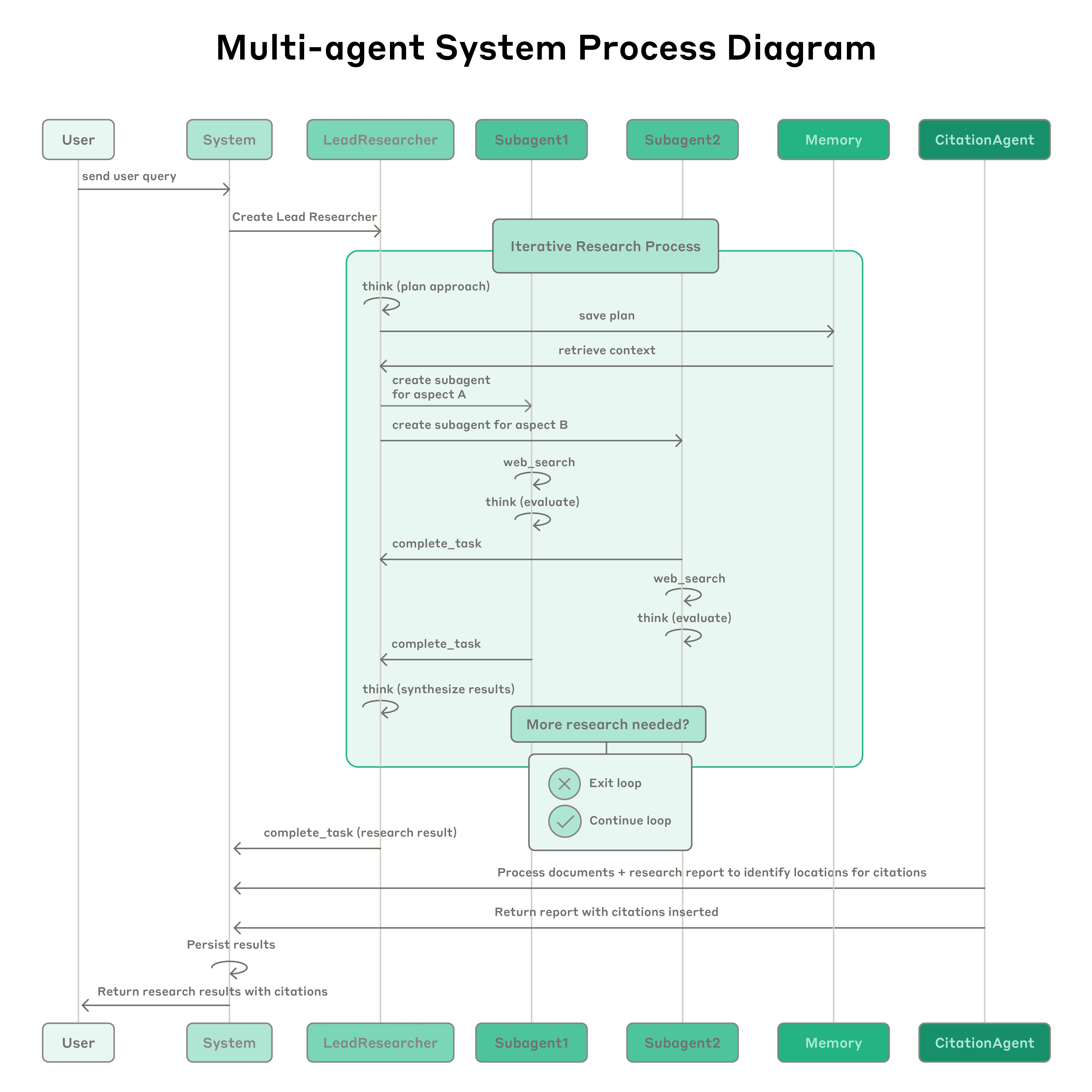
リードエージェントは3〜5体のサブエージェントを同時に稼働させ、さらに各サブエージェントも3つ以上の検索ツールを並行して使用する。これにより、従来は数時間かかっていた複雑な調査が、わずか数分で完了するケースもあったという。調査時間を最大90%も削減できたのは、この徹底した並列処理のおかげだ。
3. 「作業スペースの壁」を超える賢い仕組み
人間には「短期記憶」の限界があるように、AIにも「コンテキストウィンドウ」と呼ばれる、一度に記憶・処理できる情報量の上限が存在する。一人のAIが長大な調査を行うと、この上限にすぐに達してしまい、調査の初期段階で得た重要な情報を忘れてしまうという根源的な課題があった。
しかし、マルチエージェントシステムでは、各サブエージェントがそれぞれ独立した「作業スペース(コンテキストウィンドウ)」を持つ。これにより、システム全体としては、一人のAIの限界をはるかに超える膨大な情報を同時に扱うことができる。重要な計画などは、忘れないように専用の「メモリー」領域に保存する工夫もされている。
精度と効率を高める「プロンプトエンジニアリング」の妙技
ただ複数のAIを集めただけでは、烏合の衆になってしまう。マルチエージェントシステムの複雑さは、エージェント間の協調が難しくなることにも表れる。初期のシステムでは、簡単な質問に対して50ものサブエージェントを起動したり、存在しない情報源を延々と探したり、互いに過剰な更新で邪魔し合ったりといったエラーが頻発したという。これらの問題に対処するため、Anthropicは「プロンプトエンジニアリング」を主要な改善レバーとして活用した。
彼らが学んだ「エージェントにプロンプトを与えるための原則」は以下の通りだ。
- エージェントの視点に立つ: エージェントがどのように考え、行動するかを理解するために、実際のプロンプトとツールを使ったシミュレーションを行い、失敗パターンを早期に発見する。
- オーケストレーターに委任方法を教える: リードエージェントがサブエージェントにタスクを分解し、明確な目的、出力形式、使用すべきツールや情報源、タスクの境界を具体的に指示する。曖昧な指示は重複作業や情報漏れにつながる。
- クエリの複雑さに応じて労力を調整する: エージェントはタスクの適切な労力を判断するのが苦手なため、プロンプトに「簡単な事実確認には1エージェント、複雑な研究には10以上のサブエージェント」といったスケーリングルールを埋め込む。
- ツール設計と選択の重要性: エージェントとツールのインターフェースは、人間とコンピューターのインターフェースと同じくらい重要である。すべての利用可能なツールを最初に検討し、ユーザーの意図に合ったツールを選び、汎用ツールよりも専門ツールを優先するようなヒューリスティクスを明示的に与える。
- エージェント自身に改善させる: Claude 4モデルは優れたプロンプトエンジニアにもなれる。失敗モードを与えると、その原因を診断し、プロンプトの改善を提案できる。Anthropicは、欠陥のあるツールを与え、それをテストし、ツールの説明を書き換えて失敗を避ける「ツールテストエージェント」まで作成した。これにより、将来のエージェントのタスク完了時間が40%も短縮されたという。
- 広く始めてから絞り込む: 人間の熟練した研究者と同じように、エージェントも最初は広く探索し、利用可能なものを評価してから、徐々に焦点を絞っていくように促す。
- 思考プロセスをガイドする: Claudeの「拡張思考モード」や「インターリーブ思考」を活用し、エージェントが思考過程を明確に出力させることで、計画、ツール選択、クエリ精査、ギャップ特定などの意思決定の質と効率を向上させる。
- 並列ツール呼び出しが速度と性能を変革する: 複雑な研究タスクでは多くの情報源を探索するため、初期のシステムでは検索が遅かった。Anthropicは、(1)リードエージェントが3〜5個のサブエージェントを並行して起動する、(2)サブエージェントが3つ以上のツールを並行して使用する、という2種類の並列化を導入。これにより、複雑なクエリの調査時間が最大90%も短縮された。
これらのプロンプトエンジニアリングの戦略は、厳格なルールではなく、熟練した人間の研究者の思考プロセスやヒューリスティクス(発見的手法)をエージェントに落とし込むことに焦点を当てている。
信頼性を築く「エージェント評価」の最前線
マルチエージェントシステムの評価は、単一エージェントよりも格段に難しい。なぜなら、マルチエージェントシステムは、同じ入力でも異なる経路をたどって同じ結果に到達する「非決定性」を持つからだ。Anthropicは、この課題に対し、以下の原則で対処している。
- 小規模サンプルから直ちに評価を開始する: 開発初期段階では、プロンプトのわずかな変更が性能に劇的な影響を与えるため、少数のテストケースでも変化を明確に確認できる。完璧な評価システムを待つのではなく、すぐに始めることが重要だ。
- 「LLM-as-a-judge(LLMを評価者として使う)」の活用: 研究結果は自由形式のテキストであり、単一の正解がない場合も多いため、LLMを評価者として用いることが有効である。Anthropicは、事実の正確性、引用の正確性、完全性、情報源の品質、ツールの効率性といった基準で0.0-1.0のスコアと合否を判定する単一のLLM評価者を導入し、数百の出力をスケーラブルに評価できるようになった。
- 人間の評価で自動化が漏らす部分を補完する: LLM評価が有効である一方で、人間のテスターは、AIが生成するハルシネーション(幻覚)、システムの故障、あるいは初期のエージェントが権威ある情報源よりもSEOに最適化された「コンテンツファーム」を好むといった、自動評価では見落とされがちなエッジケースや微妙な偏りを特定する。人間による手動テストは、自動評価があっても不可欠である。
プロダクション運用を支える「エンジニアリングの課題と解決策」
AIエージェントをプロトタイプから実際のプロダクションシステムへと移行させるには、数々のエンジニアリング上の課題を克服する必要がある。特に、エージェントシステムは非常に「ステートフル(状態を持つ)」であり、エラーが複合的に影響し合うため、些細な問題がシステム全体を破綻させる可能性がある。
企業のCIO(最高情報責任者)がAIエージェントの導入を検討する際に注意すべき点も、このエンジニアリングの課題に集約されている。
- ステートフルなエージェントとエラーの複合: エージェントは長期間にわたり稼働し、多くのツール呼び出しを通じて状態を維持する。このため、エラーが発生した場合に単に最初からやり直すことは費用とユーザー体験の点で非現実的だ。Anthropicは、エラーが発生した時点から処理を再開できるシステムを構築し、ツールが失敗した際にエージェント自身が適応できるよう、AIの知性を活用している。
- CIOへの示唆: AIエージェント導入の際は、単なる機能だけでなく、エラー発生時のリカバリ戦略や、エージェントが自律的に問題に対処できるような設計が不可欠である。ベンダーが提供するエージェントソリューションの堅牢性を確認すべきだ。
- デバッグの困難さ: エージェントは動的な意思決定を行い、実行ごとに非決定性を持つため、デバッグは非常に難しい。Anthropicは、エージェントがなぜ失敗したのかを診断し、修正するために「フルプロダクショントレーシング」を導入した。これにより、個々の会話の内容を監視することなく、エージェントの意思決定パターンや相互作用構造を監視し、根本原因を特定できるようになった。
- CIOへの示唆: エージェントの挙動を監視し、問題発生時に原因を特定できる「オブザーバビリティ(可観測性)」ツールは、AIエージェントプラットフォームにおいて極めて重要となる。
- デプロイメントの複雑さ: プロンプト、ツール、実行ロジックが絡み合うエージェントシステムは、ほとんど常に稼働しているため、アップデートのデプロイメントは複雑だ。既存の稼働中のエージェントに影響を与えないよう、Anthropicは「レインボーデプロイメント」のような手法を用いて、徐々に新しいバージョンにトラフィックを移行させている。
- CIOへの示唆: AIエージェントのデプロイは、従来のソフトウェアデプロイよりも複雑になることを理解する必要がある。安定した運用を維持するためのデプロイ戦略が求められる。
- 同期実行のボトルネックと非同期実行への展望: 現在のリードエージェントはサブエージェントが完了するのを待つ同期実行方式を採用しており、情報フローにボトルネックが生じる。Anthropicは、将来的にはエージェントが並行して作業し、必要に応じて新しいサブエージェントを作成できる「非同期実行」への移行を目指している。
- その他のヒント:
- エンドステート評価: 複数ターンにわたる会話で状態が変化するエージェントの評価では、プロセスではなく、最終的な状態が正しいかどうかに焦点を当てる「エンドステート評価」が有効。
- 長期間の会話管理: 長い会話では文脈窓の制約が問題になるため、エージェントが完了した作業を要約し、重要な情報を外部メモリに保存する仕組みが不可欠。
- サブエージェントのファイルシステムへの出力: サブエージェントが直接外部のファイルシステムに結果を出力することで、リードエージェントを介した情報伝達のオーバーヘッドを減らし、情報の忠実度を高めることができる。
未来のAI研究とビジネスへの影響
Anthropicのマルチエージェント研究システムは、AIによる情報探索と複雑な問題解決の新たな地平を切り開いた。このシステムは、従来のRAGモデルのような静的な情報取得とは異なり、まるで熟練した研究者チームが動的に情報を探索・分析し、その過程で戦略を修正していくかのような柔軟性と効率性をAIにもたらす。
高いトークン消費量という課題は残るものの、単一エージェントを圧倒する性能向上は、そのコストを正当化する高価値なタスクにおいて、このシステムの導入が進むことを示唆している。特に、ビジネスにおける新たな機会の発見、複雑な医療オプションのナビゲート、難解な技術的バグの解決、学術研究や教育資料の開発、そして人や組織に関する情報の調査・検証といった分野での活用が期待されている。
「プロトタイプからプロダクションへの道のりは、予想以上に広かった」とAnthropicは述べている。しかし、綿密なエンジニアリング、包括的なテスト、詳細にわたるプロンプトおよびツール設計、堅牢な運用プラクティス、そして研究・製品・エンジニアリングチーム間の緊密な連携によって、マルチエージェントシステムは大規模かつ信頼性高く運用できることを証明した。
この革新的なアプローチは、AIが単なるツールから、私たちの最も複雑な課題を解決するための強力な「共同作業者」へと進化する、その重要な一歩となるだろう。Anthropicが提示したこの青写真は、未来のAI開発と、それがもたらす社会変革の可能性を私たちに示しているのだ。
Sources
- Anthropic: How we built our multi-agent research system


