人類が手にした最も精密な思考機械であるプロセッサは、長年にわたり物理的な限界に直面している。現代のコンピュータは、演算ユニットの圧倒的な速度に対して、メインメモリへのアクセス速度が致命的に遅いという「メモリの壁」に苦しんできた。この速度差を埋めるため、プロセッサの内部にはキャッシュメモリと呼ばれる超高速な記憶領域が設けられている。しかし、限られた容量のキャッシュにどのデータを残し、どのデータを捨てるかを決める「置換ポリシー」の設計は、暗闇の中で針の穴に糸を通すような作業であった。
設計者たちは、膨大なシミュレーションを実行し、吐き出される無味乾燥なヒット率の数字を眺めながら、なぜ特定のデータが捨てられたのかという「理由」を推測するほかなかった。これまでの最適化は、まさに手探りの試行錯誤に依存してきたのである。
ノースカロライナ州立大学の研究チームは、この半世紀にわたる絶望的な状況に終止符を打つべく、自然言語による対話を通じてハードウェアの深層に隠された因果関係を解き明かすAI支援ツール「CacheMind」を開発した。これは情報要約ツールにはとどまらない。アーキテクトが「なぜこのメモリアクセスは失敗したのか」と問うことで、AIが数百万行のトレースデータから根本原因を抽出し、プロセッサ性能を飛躍的に向上させるための具体的な処方箋を提示する、真の「マイクロアーキテクチャの顕微鏡」の誕生である。
シリコンの迷宮。キャッシュメモリが抱える構造的アポリア
コンピュータの演算処理を、日常の学術研究に置き換えてみよう。巨大なデータセンターやハードディスクは、街の郊外にある巨大な公文書館である。プロセッサの演算ユニットは、その公文書館の膨大な資料を使って論文を執筆する学者に例えられる。学者が資料を確認するたびに郊外まで車を走らせていては、執筆は一向に進まない。そこで、学者の手元には小さな机(キャッシュメモリ)が用意される。
机の上には数冊の本しか置けないため、新しい本を開くには、すでに机の上にあるどれかの本を片付けなければならない。次にどの本が必要になるかを完璧に予測できれば、学者の作業効率は最大化される。これがキャッシュ置換ポリシーの究極の目標である。理論上の限界値であるベルディの最適ポリシー(Belady's optimal policy)は、「次に使われるまでの時間が最も長いデータを捨てる」という絶対的な法則に従って動く。だが、未来を完璧に見通すことは不可能であるため、実際のハードウェアでは「最も過去に使われなかったものを捨てる」というLRU(Least Recently Used)などの単純な経験則が用いられてきた。
近年では、過去のメモリアクセスのパターンから再利用までの距離を予測する「Mockingjay」や、模倣学習を用いてベルディの最適ポリシーの振る舞いに近づけようとする「PARROT」など、機械学習ベースの高度なアルゴリズムが登場している。しかし、これらの高度なポリシーは新たな問題を引き起こした。シミュレーションを実行してキャッシュのヒット率が低下した際、なぜそのアルゴリズムが特定のデータを誤って追い出したのかが、完全にブラックボックス化してしまったのである。
ChampSimやgem5といった業界標準のシミュレータが吐き出すのは、何百万行にも及ぶメモリアクセスの履歴(トレースデータ)である。特定のアドレスで発生した一連の出来事を手作業で抽出し、その背後にあるアルゴリズムの判断ミスを特定することは極めて困難だ。設計者たちは、集計された統計データという断片的な影絵を見て、元の立体の形を当てようと苦闘してきた。そこにあるのは「何が起きたか」という事象の羅列であり、「なぜ起きたか」という根本原因には決して辿り着けないという厚い壁が立ちはだかっていた。
見えない因果を言語化する。検索拡張生成が仕掛けるトリック
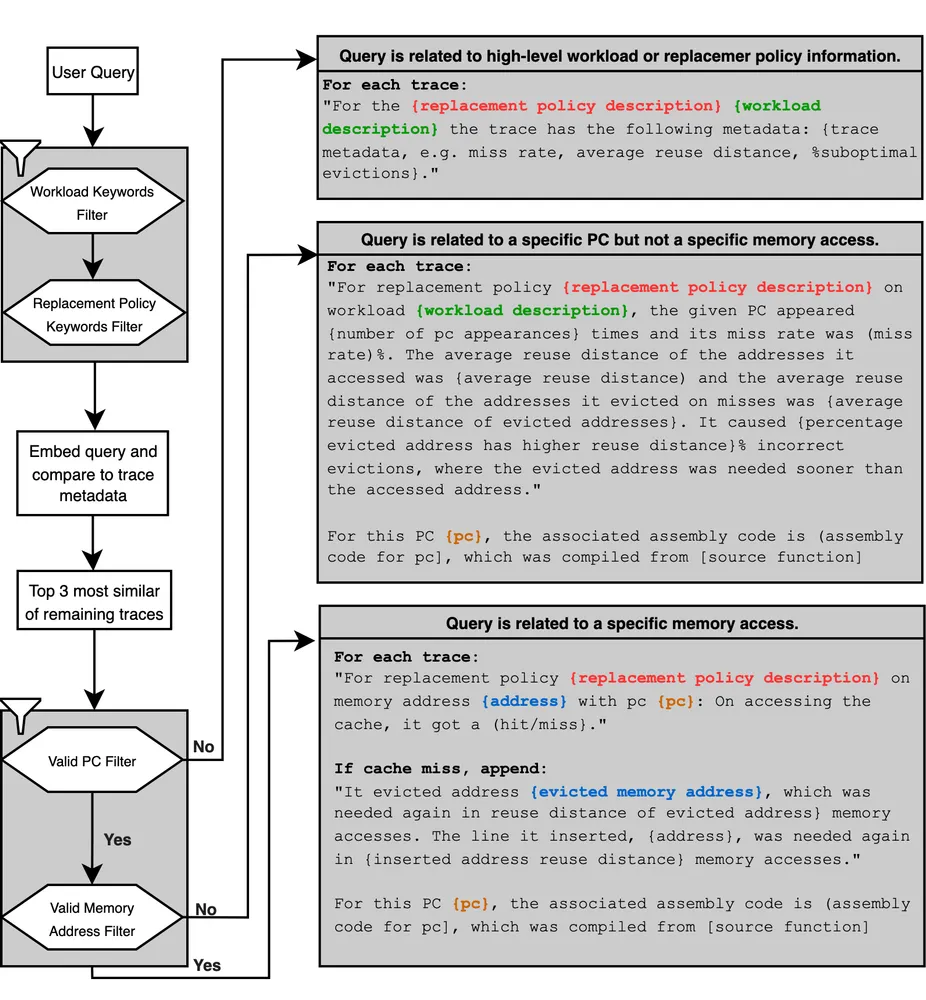
ノースカロライナ州立大学の研究チームが提示した解決策は、大規模言語モデル(LLM)と検索拡張生成(RAG)を組み合わせ、生のハードウェアトレースデータを人間が解読可能な文脈へと翻訳することである。「CacheMind」は、アーキテクトが「なぜこのメモリアクセスは、より多くのキャッシュ追い出しを引き起こしているのか」といった抽象的な疑問を自然言語で投げかけることを可能にした。
ここで直面する技術的な障壁は、LLMのコンテキストウィンドウの限界と、もっともらしい嘘(ハルシネーション)の発生である。数百万行のトレースデータをそのままLLMに入力すれば、モデルは情報の海に溺れて破綻する。一般的なテキスト検索に用いられるLlamaIndexのような既存のRAGシステムも、この領域では無力であった。既存のRAGは文章のベクトル類似度に基づく検索(コサイン類似度)を行うが、ハードウェアトレースデータは微細な数値やビットレベルの違いが極めて重要な意味を持つため、曖昧な類似度検索では正しいログを引き当てることができない。事実、既存ツールでの検索成功率はわずか10パーセントに留まった。
この限界を突破するため、CacheMindは二段構えの高度な検索機構を実装している。第一の機構である「Sieve」は、ユーザーの質問から関連するプログラムカウンタ(命令の実行位置を示す番地)やメモリアドレス、比較すべきポリシーを記号的に抽出し、巨大なデータベースから該当するデータの断片だけを高速に切り出すフィルタである。
さらに強力なのが、第二の機構である「Ranger」だ。これは、言語モデル自身にPythonコードを記述させ、データベースを動的に検索・集計させるエージェント型の検索システムである。事前に用意された検索テンプレートには収まらない、複数の事象を横断するような抽象的な質問に対しても、Rangerは90パーセントという極めて高い精度で必要なデータをピンポイントで抽出する。
抽出されたデータは、キャッシュのミス率やアクセス間の距離といった統計情報に加え、そのメモリアクセスを指示した元のソースコードやアセンブリコードと結合される。この緻密な「文脈」を与えられた言語モデルは、ハードウェアの微小な振る舞いとソフトウェアの論理構造を結びつけ、なぜそのキャッシュミスが発生したのかを論理的な文章として出力する。
試行錯誤からの脱却。新旧パラダイムの構造的差異
従来の手法とCacheMindがもたらすアプローチには、根本的な断絶がある。以下の表は、既存のシミュレータベースの解析プロセスと、今回の対話型アプローチの構造的差異を整理したものである。
| 比較項目 | 従来のシミュレータ解析 | CacheMindが提示する新パラダイム |
|---|---|---|
| 主要な出力 | ヒット率やミス率などの集計された静的統計データ | 特定の現象に対する自然言語での因果説明と根拠データ |
| 解析の粒度 | ワークロード全体のマクロな数値指標 | プログラムカウンタ(PC)やメモリアドレス単位のミクロな挙動 |
| インターフェース | 生ログファイルの出力と手動のスクリプト解析 | 自然言語による任意の質問と動的な検索・応答(対話型) |
| 改善のプロセス | パラメータを変更して再実行する盲目的な試行錯誤 | 根本原因の特定に基づく、ハードウェアとソフトウェアの協調的な修正 |
従来のアーキテクチャ研究では、新しいキャッシュ置換アルゴリズムを提案する際、それが「どの程度優れているか」をベンチマークのスコアで証明できても、「なぜ優れているのか」を局所的な命令レベルで説明することは困難を極めた。CacheMindは、特定のメモリアクセスが理想的なタイミングよりも早く追い出されてしまった理由を、具体的なコードの挙動と結びつけて説明する。これにより、アーキテクトはアルゴリズムの弱点をピンポイントで修正したり、ソフトウェア側にデータを事前読み込み(プリフェッチ)する命令を追加したりするといった、より高い次元での意思決定が可能になる。
プロセッサ性能を引き上げる強力な処方箋
研究チームは、業界標準のシミュレータ(ChampSimおよびgem5)を用いて、CacheMindの有用性を定量的に実証した。質問に対する的確な応答は、ツールの効能の一部に過ぎない。CacheMindが導き出した洞察は、プロセッサの実際の性能向上へと直結しているのだ。
具体的な成果の一つとして、特定のメモリ集約型ベンチマーク(mcfワークロード)において、CacheMindはキャッシュを無駄に占有している命令群(PC)を特定した。この分析に基づき、それらの特定の命令によるキャッシュへのデータ挿入を意図的に迂回(バイパス)させるようLRUポリシーのロジックを修正した結果、キャッシュのヒット率が相対値で7.66パーセント向上し、プロセッサの処理性能を示すIPC(1クロックあたりの実行命令数)が2.04パーセント向上した。
さらに興味深いのは、先述の機械学習ベースのポリシー「Mockingjay」の改良である。Mockingjayはキャッシュラインの再利用距離を予測するが、ノイズの多いデータで学習すると精度が落ちる。CacheMindの対話を通じて、再利用距離の分散が小さく予測しやすい「安定したプログラムカウンタ」を抽出し、そのデータのみを用いてMockingjayを再学習させた。その結果、ノイズに惑わされなくなったアルゴリズムは、元のモデルから0.7パーセントのスピードアップを達成した。
最も劇的な結果はソフトウェア側への介入によってもたらされた。あるテストプログラムにおいて、CacheMindはキャッシュミスの大半を引き起こしている単一のロード命令を特定した。この情報に基づき、将来のアクセスパターンを予測して事前にデータを読み込む「ソフトウェアプリフェッチ命令」をソースコードに直接挿入したところ、IPCは0.131452から0.231261へと約76パーセントも飛躍的に向上したのである。ハードウェアの微細な挙動をソフトウェアの改修へと繋ぐ、鮮やかな協調設計(Co-design)の実証である。
汎用AIの限界とファインチューニングの罠
この画期的な成果は、同時に生成AIを高度な科学技術領域に適用する際の新たな洞察と課題も提示している。
研究チームは、キャッシュメモリのドメイン知識に特化させて言語モデルを微調整(ファインチューニング)する実験も行った。一般的な直感では、専門知識を学習させれば精度が上がると考えられがちだ。しかし、この微調整はシステムの推論能力を向上させず、むしろ事実に基づかない回答(ハルシネーション)を発生させるリスクを高める結果となった。
これは近年指摘されている「ファインチューニングによる幻覚の悪化」という現象と一致している。狭いドメインのデータセットで言語モデルの重みを更新すると、モデルはその領域において過剰な自信を持つようになる。その結果、未知のデータやトリッキーな質問(例:「存在しないメモリアドレスへのアクセスはどうなるか」など)を投げかけられた際、「それは間違った前提である」と拒絶することができず、もっともらしい嘘を捏造してしまうのだ。
高度に専門的で厳密な論理的推論を要するハードウェア解析タスクにおいては、言語モデル自体の重みを変更するよりも、強力な汎用モデル(GPT-4oなど)を推論エンジンとして据え、精緻な検索機構(SieveやRanger)を通じて正確なデータセットを適切なタイミングで提供することの方が遥かに重要であることが示されている。
シリコン覇権を揺るがすアーキテクチャ設計の未来
CacheMindの登場は、単なる一大学の研究成果にとどまらず、プロセッサ設計における人間と機械の役割分担を根本から再定義する可能性を秘めている。
現在、Intel、AMD、Apple、さらにはAI半導体で市場を席巻するNVIDIAなど、巨大テクノロジー企業によるシリコン覇権の競争は苛烈を極めている。トランジスタの微細化が限界に近づく中、キャッシュメモリの効率化による1クロックあたりの性能向上は、データセンターの省電力化や巨大なAIインフラのランニングコスト削減に直結する死活問題である。
これまで、優秀なアーキテクトたちは数百万行の生ログの海に潜り、数週間かけてボトルネックを特定していた。CacheMindがこのプロセスを自然言語による即座の対話へと置き換えることで、チップの設計サイクルは劇的に短縮される。アーキテクトは「データをどう集めるか」という作業から解放され、「どの現象を観察し、どのような革新的なポリシーを設計すべきか」という、より高次な問いを立てることに専念できるようになる。
暗闇に包まれていたキャッシュメモリの迷宮に持ち込まれたこの強力な松明は、半導体産業全体に新たな最適化の波を起こす。AIの力によってAIを支えるハードウェアの限界を突破する、自己進化的なテクノロジーサイクルの幕開けである。
論文
- arXiv: CacheMind: From Miss Rates to Why -- Natural-Language, Trace-Grounded Reasoning for Cache Replacement
参考文献