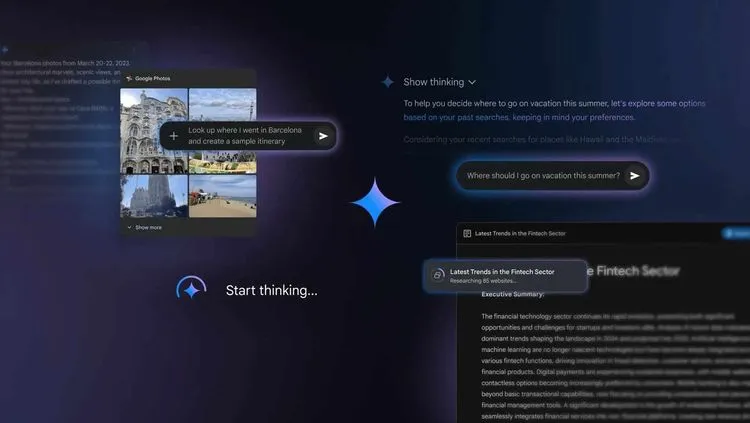
CloudflareはWebインフラの保護に新たなアプローチとなる「AI Labyrinth(AIの迷宮)」機能を発表した。この機能は、許可なくWebサイトをクロールするAIボットに対して単にブロックするのではなく、AIで生成された無関係な事実のページに誘導し、時間とリソースを無駄にさせる革新的な手法だ。同機能は無料プランを含むすべてのCloudflareユーザーにオプトイン形式で提供されている。
伝統的ブロックから誘導作戦へ:AI Labyrinthの仕組み
従来のブロック戦略との違い
Cloudflareの新アプローチは、従来のブロック&防御戦略とは一線を画している。不正なクローリングを検出した場合、リクエストをブロックする代わりに、AIが生成した一連のページへのリンクを提供する。これらのページは実際のWebサイトの一部ではないが、本物のように見えるため、クローラーはこれらのページを探索することになり、貴重な時間とコンピューティングリソースを浪費することになる。
「悪質なボットをブロックすると、攻撃者に検出されたことを知らせてしまい、アプローチの変更を促すことになります。これは終わりのない軍拡競争につながります」とCloudflareは説明している。
コンテンツの生成と安全性への配慮
AI Labyrinthが生成するコンテンツは、保護対象のWebサイトとは無関係だが、誤情報の拡散を防ぐため、科学的事実に基づいた生物学、物理学、数学などに関する中立的な情報を活用している。Cloudflareはこのコンテンツを自社の商用プラットフォーム「Workers AI」サービスを使用して作成している。
これらのトラップページとリンクは一般の訪問者には見えず、アクセスもできない設計になっているため、通常のWeb閲覧で誤ってこれらのページにたどり着くことはない。
次世代ハニーポットとボット検出の進化
ハニーポットの新たな形
AI Labyrinthは、Cloudflareが「次世代ハニーポット」と呼ぶ機能も備えている。従来のハニーポットは、人間には見えないがHTMLコードを解析するボットには検出されるリンクだった。しかし、現代のボットはこれらの単純なトラップを見抜くのが上手くなっており、より洗練された欺瞞が必要となっている。
「AIで生成された無意味なページを4リンク以上も深く探索する実際の人間はいません。そこまで探索する訪問者はボットである可能性が非常に高く、これは悪質なボットを識別してフィンガープリントする新しいツールとなります」とCloudflareは説明する。
機械学習フィードバックループの構築
この識別は機械学習フィードバックループに組み込まれ、AI Labyrinthから収集されたデータはCloudflareのネットワーク全体でボット検出を継続的に向上させる。どのクローラーがこれらの隠されたパスをたどっているかを分析することで、それまで検出できなかった新しいボットパターンとシグネチャを特定できるのだ。
技術的実装:AIでAIに対抗する戦略
コンテンツ生成パイプライン
AI Labyrinthの技術的実装は、Workers AIとオープンソースモデルを活用して多様なトピックに関するHTMLページを作成している。パフォーマンス維持のため、コンテンツはオンデマンドではなく事前に生成され、XSS(クロスサイトスクリプティング)脆弱性を防ぐために浄化された後、高速アクセス用にR2ストレージに保存される。
Cloudflareによれば、「トピックの多様なセットを最初に生成し、次に各トピックのコンテンツを作成することで、より多様で説得力のある結果が得られた」という。
シームレスな統合と検索エンジン保護
事前生成されたコンテンツは、カスタムHTMLトランスフォーメーションプロセスを通じて、元のページの構造やコンテンツを乱すことなく既存のページに隠しリンクとして統合される。各生成ページには、SEO(検索エンジン最適化)を保護するために検索エンジンのインデックス作成を防止するメタディレクティブが含まれている。
これらのリンクは慎重に実装された属性とスタイリングにより人間の訪問者には見えない。このアプローチの影響を最小限に抑えるため、リンクはAIスクレイパーと疑われるものにのみ提示され、正当なユーザーや検証済みのクローラーは通常通りブラウズできる。
簡単な有効化
AI Labyrinthの有効化は非常に簡単で、Cloudflareダッシュボード「セキュリティ」→「設定」の「ボット管理セクション」内で単一のトグルを切り替えるだけで良い。有効化すると、AI Labyrinthは追加の設定なしで即座に機能し始める。
急増するAIクローリングの問題と規模
増え続けるAIクローラートラフィック
Web上でのAIクローリングの規模は、Cloudflareのデータによれば相当なものだ。同社によると、AIクローラーは彼らのネットワークに対して毎日500億以上のリクエストを生成しており、これは処理するウェブトラフィック全体の約1%に相当する。この数字はCloudflareが世界最大級のWebインフラプロバイダーの一つであることを考えると、かなりの規模を示している。
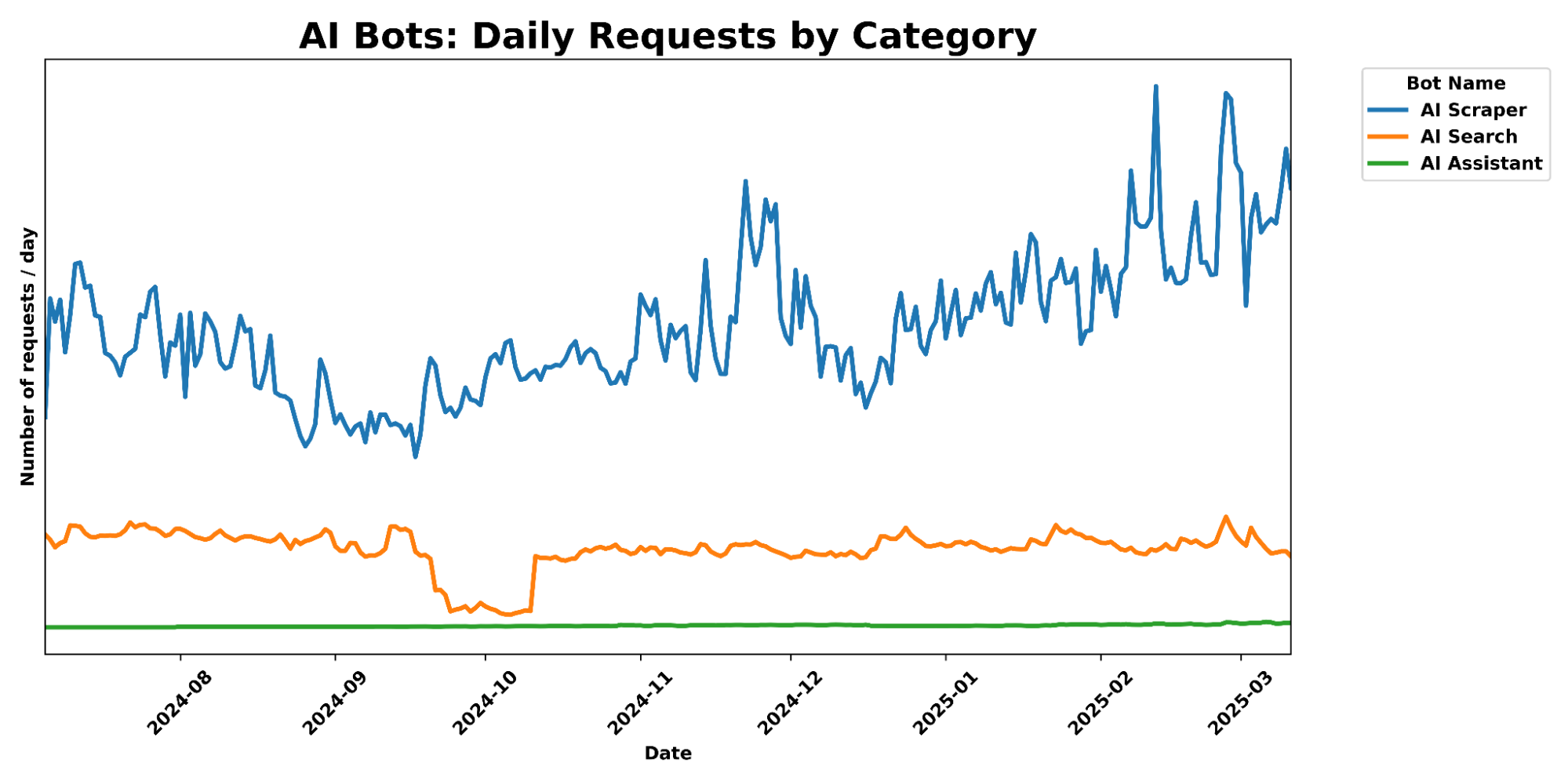
同様のツールとの比較
AI Labyrinthの登場は、積極的なAIクローリングに対抗するツールの増加傾向に合致している。1月には「Nepenthes」という、同様にAIクローラーを偽コンテンツの迷路に誘い込むソフトウェアが報告された。
両者はクローラーをブロックせずリソースを無駄にさせるという基本概念を共有しているが、Nepenthesは「攻撃的なマルウェア」としてボットを長期間閉じ込めることを目的としているのに対し、Cloudflareは自社のツールを正当なセキュリティ機能として位置付けている点が異なる。
コンテンツ無断収集の法的問題
多くのクローラーは、サイト所有者の許可なくウェブサイトデータを収集してAI言語モデルをトレーニングしており、これはコンテンツ作成者や出版社からの多数の訴訟を引き起こしている。AI Labyrinthは、知的財産を脅かすのではなく保護するAIの防御的応用を表している。
今後の展開:AIによる防御の未来
継続的な進化
Cloudflareはこれを「ボットを阻止するために生成AIを使用する最初の反復」と位置付けている。将来の計画には、偽コンテンツをより検出しにくくすることや、ウェブサイトの構造にこれらの偽ページをよりシームレスに統合することが含まれている。
「ウェブサイトとデータスクレイパー間の猫とネズミのゲームは続いており、今はAIが戦いの両側で使用されています」とArs Technicaは指摘している。
AI対AIの新時代
AIクローラーがどれほど迅速にこのような罠を検出して回避するようになるかは不明であり、これによってCloudflareが欺瞞戦術の複雑さを高める必要が生じる可能性がある。また、AIを使用することでのエネルギー消費や環境への影響を懸念する声もある中、AI会社のリソースを意図的に無駄にする戦略には賛否両論があるだろう。
Source
- Cloudflare: Trapping misbehaving bots in an AI Labyrinth