
中国のAIスタートアップDeepSeekが9月29日、実験的な大規模言語モデル「DeepSeek-V3.2-Exp」を発表した。新技術「スパースアテンション」の導入により、性能を維持しつつAPI価格を最大75%も引き下げるという衝撃的な内容だ。しかし、この発表の真の核心は価格破壊だけではない。Huaweiの国産AIチップ「Ascend」とソフトウェアスタック「CANN」に初日から最適化されたという事実は、NVIDIAのCUDAエコシステムからの脱却を目指す中国独自のAI戦略が、新たな段階に入ったことを明確に示している。
衝撃の価格設定、100万トークンが3セント未満に
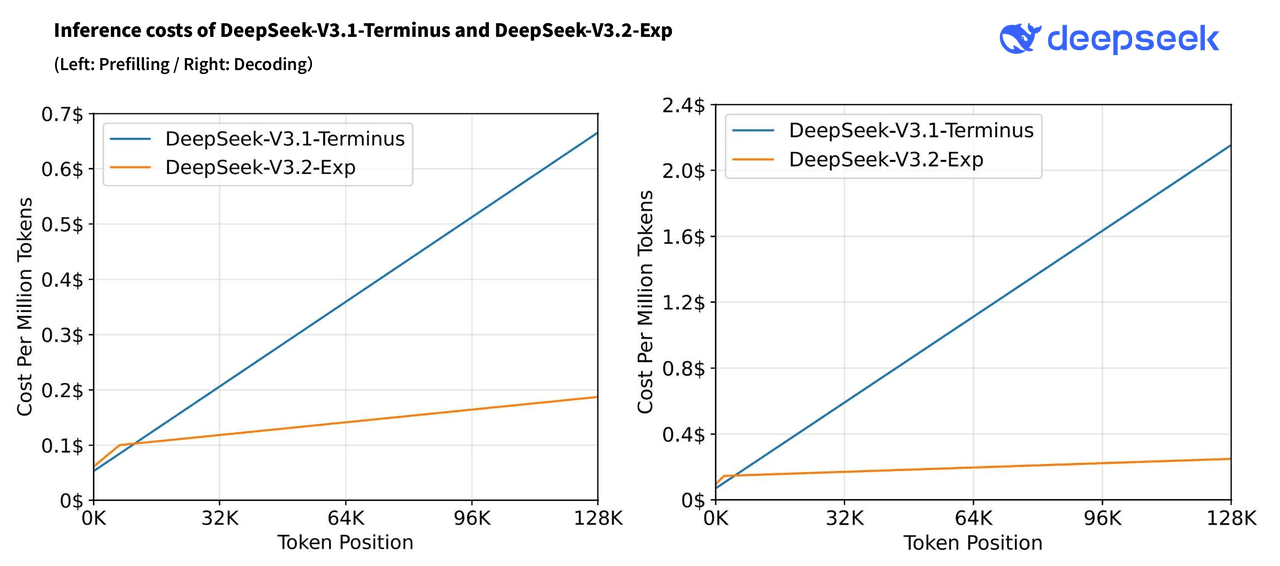
今回の発表で最も市場に衝撃を与えたのは、その圧倒的な低価格だ。DeepSeek-V3.2-ExpのAPI価格は、前モデルV3.1-Terminusと比較して50%から75%という大幅な引き下げが行われた。
具体的には、API呼び出しにおける料金は以下の通りとなる。
| トークン種別 | 新価格(V3.2-Exp) | 旧価格(V3.1-Terminus) | 削減率 |
|---|---|---|---|
| 入力(キャッシュヒット時) | $0.028 / 100万トークン | $0.07 / 100万トークン | -60% |
| 入力(キャッシュミス時) | $0.28 / 100万トークン | $0.56 / 100万トークン | -50% |
| 出力 | $0.42 / 100万トークン | $1.68 / 100万トークン | -75% |
キャッシュヒット時の入力トークンに至っては、100万トークンあたりわずか0.028ドル(約4円)という驚異的な価格設定だ。これは、OpenAIやAnthropicといった欧米の主要プロバイダーが提供する最も安価なモデルと比較しても、極めて競争力の高い水準だ。 この価格破壊は、AIアプリケーション開発のコスト構造を根底から覆す可能性を秘めている。
価格破壊の心臓部「DeepSeek Sparse Attention (DSA)」とは何か
この劇的なコスト削減を可能にしたのが、新モデルの核となる「DeepSeek Sparse Attention (DSA)」と呼ばれる技術だ。
従来の多くの大規模言語モデルが採用する「Dense Attention(密なアテンション)」機構は、入力された文章(コンテキスト)内のすべての単語(トークン)同士の関係性を計算する。これは非常に強力だが、コンテキストが長くなると計算量が二乗関数的に爆発し、膨大な計算資源(メモリと計算パワー)を消費するという根本的な課題を抱えていた。
これに対し、DSAは「重要な情報だけを選んで注目する」という、より効率的なアプローチをとる。DeepSeekの技術レポートによれば、DSAは2段階のプロセスで動作する。
- Lightning Indexer: まず、長いコンテキストの中から、タスクに関連性が高いと判断される部分的な抜粋を高速に特定する。
- Fine-grained Token Selection: 次に、その抜粋の中からさらに重要なトークンを選択し、限られたアテンションの計算資源をそこに集中させる。
この仕組みにより、モデルはすべてのトークンを網羅的に比較する必要がなくなり、特に数万から十数万トークンに及ぶ長文コンテキストを処理する際の推論コストを劇的に削減できる。DeepSeekによると、128,000トークンのコンテキストレベルでは、推論コストは前モデル比でプリフィル(初期読み込み)時に約3.5倍、デコーディング(生成)時に6〜7倍も低くなるという。
性能はほぼ同等を維持
効率性を追求する一方で、性能が犠牲になっていない点も注目すべきだろう。DeepSeekが公開したベンチマーク結果では、V3.2-Expは前モデルV3.1-Terminusとほぼ同等の性能を維持している。
| ベンチマーク | DeepSeek-V3.1-Terminus | DeepSeek-V3.2-Exp |
|---|---|---|
| MMLU-Pro (推論) | 85.0 | 85.0 |
| GPQA-Diamond (推論) | 80.7 | 79.9 |
| Codeforces (コーディング) | 2046 | 2121 |
| BrowseComp (エージェント) | 38.5 | 40.1 |
一部の複雑な推論タスクでわずかなスコア低下が見られるものの、全体としては性能を維持しており、DSAが効率性と性能のバランスを巧みに取った技術であることを示唆している。 専門家からは、スパースアテンションは重要な情報を見落とすリスクもはらむとの指摘もあるが、DeepSeekは現時点でその懸念を払拭する結果を示した形だ。
真の狙いは「脱NVIDIA依存」、中国AIエコシステム構築が加速
この発表が持つ戦略的な重要性は、HuaweiのAscendチップと、その上で動作するソフトウェアプラットフォーム「CANN (Compute Architecture for Neural Networks)」に初日から最適化されている点にある。 これは単なる互換性の確保ではない。NVIDIAのCUDAプラットフォームが独占的な地位を築くAI業界において、中国が国家レベルで推進する「AI主権」確立に向けた、極めて意図的な一歩である。
NVIDIAのCUDAは単なるプログラミングモデルではなく、膨大なライブラリ、最適化されたカーネル、そして世界中の開発者が蓄積してきたノウハウの集合体だ。この牙城を切り崩すことは容易ではない。
しかし、DeepSeekの今回の動きは、その壁に正面から挑むものだ。
DeepSeekはコードとチェックポイントをHugging Faceに公開すると同時に、技術レポートも投稿した。同社はV3.2-Expを「次世代アーキテクチャへの中間ステップ」と位置づけている。
注目すべきは、DeepSeekだけでなく、関連コミュニティも一斉に動いていることだ。vLLM-AscendコミュニティはV3.2-Expをサポートするためのカスタムオペレータのインストール手順を迅速に公開し、CANNチームも推論レシピを公開した。 これは、DeepSeekというモデル開発企業、Huaweiというハードウェア企業、そしてオープンソースコミュニティが三位一体となって、CANNエコシステムを「第一級のターゲット」として育成しようとしている証左に他ならない。
米国の半導体輸出規制により、中国企業がNVIDIAの最新鋭AIチップを入手することは極めて困難になっている。このような状況下で、Huawei Ascend、Cambricon、Hygonといった国産アクセラレータ上で最先端のAIモデルをスムーズに動作させることは、中国のAI産業にとって死活問題である。 DeepSeekの今回のリリースは、その課題に対する明確な回答であり、中国がAIにおけるハードウェアとソフトウェアの垂直統合を加速させていることを世界に示した。
企業導入の現実解か? 考慮すべきリスクと課題
圧倒的なコストパフォーマンスとオープンなライセンス(MITライセンス)は、多くの企業にとって魅力的だろう。 ベンダーロックインを避け、自社インフラでモデルを運用したい企業にとって、DeepSeek-V3.2-Expは有力な選択肢となりうる。
しかし、特に欧米の企業が導入を検討する際には、いくつかの慎重な評価が必要だ。
- データセキュリティとコンプライアンス: DeepSeekのAPIを利用する場合、データは香港に拠点を置く企業のサーバーを経由する。金融や医療など、厳格なデータガバナンスが求められる業界では、地政学的なリスクを慎重に評価する必要がある。
- 中国政府による検閲: 過去には、中国製AIモデルが特定のトピック(天安門事件、台湾問題など)に対して検閲された回答を生成する事例が報告されている。グローバルなサービス展開を考える企業にとって、これは無視できない問題だ。
- 技術の信頼性: V3.2-Expはあくまで「実験的」モデルであり、スパースアテンションの長期的な安定性や、予期せぬ挙動のリスクは未知数な部分もある。
これらのリスクを許容できない場合は、オープンソースとして公開されているモデルの重みをダウンロードし、完全に自社の管理下にあるインフラで運用するという選択肢もある。
AI業界の勢力図を塗り替える一手となるか
DeepSeek V3.2-Expの登場は、AI業界における競争の軸が、モデルの性能(賢さ)だけでなく、運用効率(コスト)とエコシステムへと明確に移行していることを象徴している。
今回の発表は、単なる一企業の技術革新に留まらない。米国の規制強化を逆手に取り、中国が独自の技術標準とエコシステムを構築しようとする強い意志の表れである。価格競争を仕掛けて欧米企業の足元を揺さぶりつつ、その裏では着々と「脱NVIDIA依存」の基盤を固めている。
AI開発の地政学的な分断がますます鮮明になる中で、DeepSeekのこの一手が、世界のAI勢力図をどのように塗り替えていくのか。筆者は、その動向を注意深く見守る必要があると考える。
Sources
- DeepSeek: Introducing DeepSeek-V3.2-Exp