2025年12月1日、中国のAI研究所DeepSeekは、最新のオープンソース言語モデル「DeepSeek V3.2」およびその実験的バリアントである「Speciale」を公開した。
同社によれば、今回のバージョンアップにより、Googleの「Gemini 3 Pro」やOpenAIの「GPT-5」といった、現在のAI市場を支配する商用フロンティアモデルに対し、オープンソース陣営が初めて「推論(Reasoning)」と「エージェント能力」において対等、あるいは特定の領域で凌駕する性能を叩き出したという。
特に注目すべきは、国際数学オリンピック(IMO)および国際情報オリンピック(IOI)で「金メダルレベル」に到達したその推論能力と、それを支えるDeepSeek Sparse Attention (DSA) という新たなアーキテクチャだ。本稿では、公開されたテクニカルレポートを基に、V3.2がもたらす技術的ブレイクスルーと、それが業界構造に与えるインパクトを見ていきたい。
DeepSeek Sparse Attention (DSA):長文脈処理の「呪縛」を解く
DeepSeek V3.2の最大の技術的革新は、従来のTransformerモデルが抱えていた構造的な非効率性を根本から解決しようとするアプローチ、「DeepSeek Sparse Attention (DSA)」にある。
全結合からの脱却
従来の標準的なAttentionメカニズム(Vanilla Attention)は、新しいトークンを生成するたびに、過去のすべてのトークンを再確認する必要があった。文脈長(Context Length)が長くなるにつれて計算量は二乗オーダー \(O(L^2)\)で増加し、これが長文脈処理におけるコストと速度のボトルネックとなっていた。
DSAはこの問題を、計算量を\(O(Lk)\)(\(k\)は選択されたトークン数、\(k \ll L\))に削減することで解決した。その仕組みは人間の「速読」や「検索」に近い。
Lightning IndexerとTop-k Selector
DSAの中核には以下の2つのコンポーネントが存在する。
- Lightning Indexer(ライトニング・インデクサー): クエリトークンと過去のトークンとの関連性を高速にスコアリングする軽量なモジュール。
- Fine-grained Token Selection(詳細トークン選択): インデクサーのスコアに基づき、真に重要なトークン(Top-k)のみを動的に抽出してAttentionを適用する。
テクニカルレポートによれば、このインデクサー自体はFP8(8ビット浮動小数点)で実装可能なほど軽量でありながら、重要な文脈情報の取りこぼしを防ぐ高度な学習が行われている。これにより、DeepSeek V3.2は128Kという長いコンテキストウィンドウを持ちながら、H800 GPUクラスター上での推論において劇的なコスト削減と高速化を実現した。これは、RAG(検索拡張生成)や長大なコードベースを扱うエージェントワークフローにおいて、決定的な競争優位性となる。
「Speciale」の衝撃:数学・競技プログラミングでの金メダル獲得
V3.2のリリースにおいて、エンジニアや研究者を最も驚愕させたのは、実験的バリアントである「DeepSeek-V3.2-Speciale」のパフォーマンスだ。
思考の連鎖を解き放つ
通常モデル(V3.2)はコストと応答速度のバランスを考慮してトークン生成数に制限が設けられているが、「Speciale」はその制限を緩和し、モデルが納得いくまで「思考(Thinking)」を続けることを許容したバージョンである。
その結果は圧倒的だ。
- 国際数学オリンピック(IMO 2025): 金メダル相当のパフォーマンス。
- 国際情報オリンピック(IOI 2025): 金メダル(全体10位相当)。
- ICPC World Final 2025: 2位相当。
これは、OpenAIのo1シリーズやGoogleのGemini 3 Proが目指してきた「System 2(熟慮型)」の推論能力を、オープンソースモデルが完全にキャッチアップしたことを意味する。特に、Codeforcesのレーティングにおいて「Speciale」は2701を記録し、GPT-5 High(2537)を上回った。
ただし、この高性能には代償がある。「Speciale」はGemini 3 Proと比較して、同じ問題を解くために平均して約3.5倍(Gemini: 2.2万トークン vs Speciale: 7.7万トークン)のトークンを消費する。これは「思考の密度」においてまだ改善の余地があることを示唆しているが、オープンソースでこのレベルの推論が可能になった事実は、学術界や産業界に計り知れない恩恵をもたらすだろう。
ポストトレーニングへの投資:パラダイムシフトの証明
DeepSeekの戦略において特筆すべきは、「事後学習(Post-Training)」へのリソース配分の劇的な増加である。
「1%」から「10%超」への転換
わずか2年前、業界では事前学習(Pre-training)が全てであり、事後学習(RLHFなど)にかける計算リソースは全体の1%程度に過ぎなかった。しかし、DeepSeek V3.2では、この事後学習の予算が事前学習コストの10%を超えている。これは、AIモデルの進化の主戦場が「知識の詰め込み」から「推論能力と行動規範の強化学習」へと完全にシフトしたことを裏付けている。
大規模合成エージェントタスク
高度な推論とツール使用能力を獲得するために、DeepSeekは人間によるデータ作成の限界を突破する「合成データパイプライン」を構築した。
- 1,800以上の合成環境: GitHubのIssueに基づいた再現可能な実行環境や、旅行計画などのタスク環境を自動生成。
- 85,000以上の複雑なプロンプト: エージェントタスク用のプロンプトを体系的に生成。
これらの合成データを用いた強化学習(RL)により、V3.2は未知の環境やツールに対する汎化性能を飛躍的に高めている。特に、GRPO(Group Relative Policy Optimization)アルゴリズムに導入された「Off-Policy Sequence Masking」などの安定化技術は、モデルが自身の生成した(時には誤った)試行錯誤から効率的に学習することを可能にした。
エージェント機能の真価:「Thinking in Tool-Use」
開発者にとって最も実用的な進化は、推論プロセスとツール使用(Function Calling)の統合である。
推論と行動の断絶を防ぐ
従来のモデルでは、ツールを使用するたびにそれまでの「思考過程(Reasoning Trace)」がコンテキストから失われたり、あるいは冗長に再生成されたりする問題があった。DeepSeek V3.2は、「Thinking Context Management」 を導入した。
これは、ユーザーからの新しい入力があるまでは思考履歴を保持し、ツール実行の結果のみを追記していく仕組みだ。これにより、モデルは「なぜそのツールを使ったのか」という文脈を維持したまま、複数のツールを連続して使用(Multi-turn Tool Use)することが可能になる。
さらに、プロンプトに<think>タグを明示的に導入することで、モデルに対して「まず思考し、その後にツールを呼び出す」という挙動を強制する「コールドスタート」手法も確立されている。これは、複雑なソフトウェアエンジニアリングタスク(SWE-benchなど)において、GPT-5を上回るスコア(SWE Multilingualで70.2% vs GPT-5の55.3%)を記録する原動力となった。
ベンチマーク比較と市場への影響
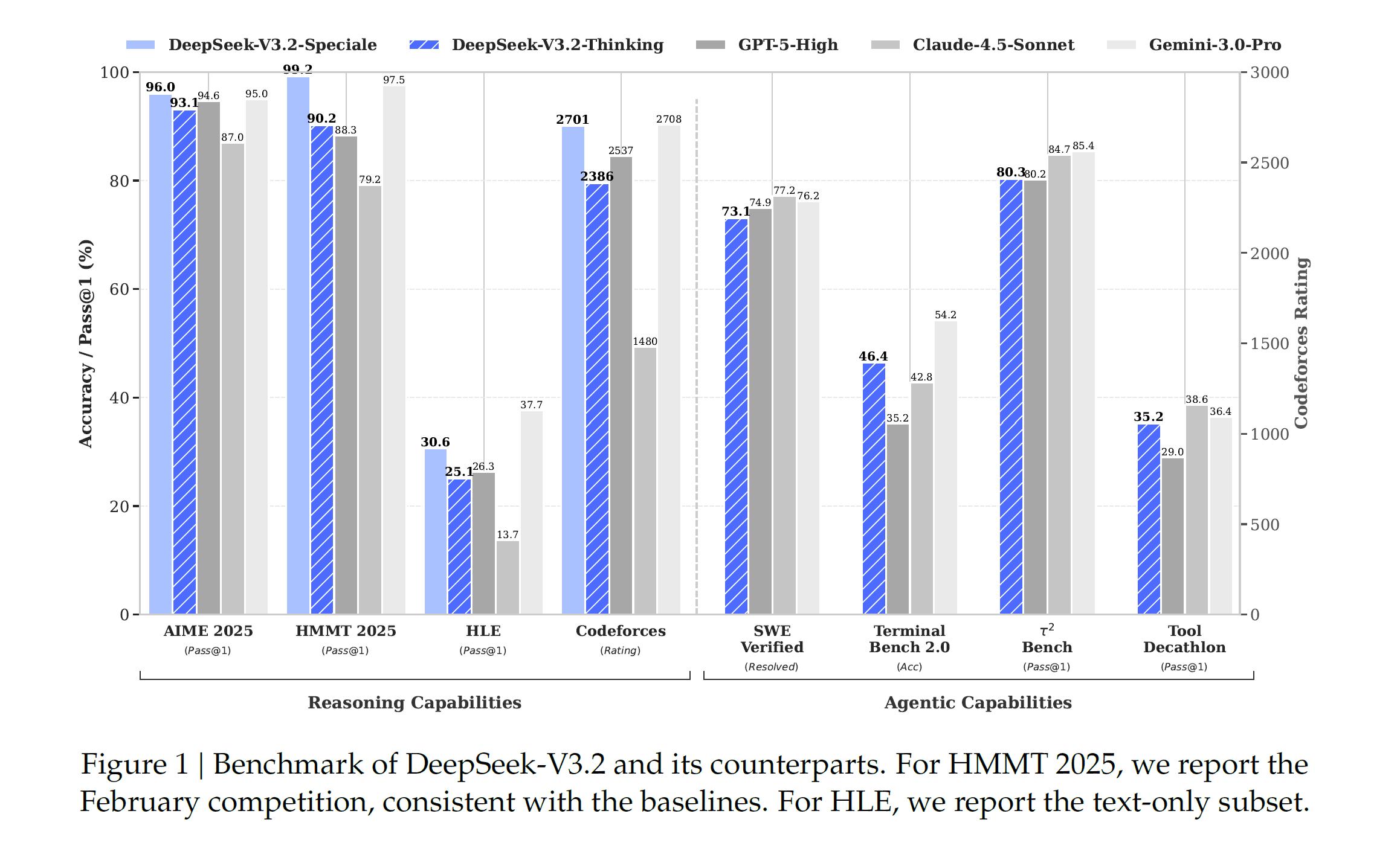
VS Giant Tech(GPT-5, Gemini 3 Pro)
提供されたベンチマークデータを分析すると、DeepSeek V3.2の立ち位置が明確になる。
- 数学・コーディング: GPT-5 Highとほぼ互角、一部でGemini 3 Proに迫る。
- エージェント・ソフトウェア開発: GPT-5を明確に上回るケースが多い(SWE Multilingual, Terminal Bench 2.0)。
- 一般知識: ここが弱点である。MMLU-Proなどの知識集約型タスクでは、依然としてGemini 3 ProやGPT-5に劣後する。
DeepSeekチーム自身も、この「知識の幅(Knowledge Breadth)」におけるギャップを認めており、事前学習データの拡充による解決を目指している。
価格破壊とAIの民主化
V3.2はApache 2.0ライセンスで公開され、API価格も攻撃的な設定がなされている。これは、OpenAIやGoogleが展開する高価なフロンティアモデルに対する強力な「価格圧力」となる。特に、自律型エージェントのように大量のトークンを消費するワークフローにおいて、安価で高性能、かつローカルホスティングも可能なV3.2の存在は、企業の採用基準を根底から覆す可能性がある。
次世代の競争は「推論効率」へ
DeepSeek V3.2の登場は、2025年のAI業界における決定的なモーメントである。「オープンソースはクローズドソースに数年遅れる」という定説は、もはや過去のものとなった。特に推論能力においては、その差は消失しつつある。
しかし、課題も残る。「Speciale」が示したように、最高の性能を引き出すためには膨大なトークン消費が必要であり、Gemini 3 Proのような「思考の効率性(Intelligence Density)」においては、まだクローズドソースモデルに一日の長がある。
今後の競争の焦点は、単なる「正答率」から、「いかに少ない思考ステップ(トークン)で複雑な問題を解決できるか」という推論効率へと移行するだろう。DeepSeekが示した「DSA」と「事後学習偏重」のアプローチは、その競争における重要な羅針盤となるはずだ。
開発者や企業にとって、V3.2は単なる選択肢の一つではない。それは、AIエージェント開発における「コスト」と「能力」のトレードオフを再定義する、極めて戦略的なツールであると言えるだろう。
Sources
- Hugging Face: deepseek-ai/DeepSeek-V3.2