
テクノロジー
AIサーバーを増やすほどPC・スマホのメモリが高くなる理由:HBM需要が生んだ逆説的な供給構造
AIサーバー向けHBM増産が進むほど、PC・スマホ向け汎用DRAMの供給が細るという逆説的な構造を、TrendForceが2027年グローバルメモリ市場1.28兆ドル予測の根拠として提示。エージェント型AIのKVキャッシュ需要急増と製造ラインの奪い合いが生む二重の価格高止まり圧力を解説。
別名: Key-Value Cache, KV Cache, KVキャッシュ
KVキャッシュ(Key-Value Cache)は、大規模言語モデル(LLM)がテキストを生成する際、過去のトークンの計算結果(KeyとValue)をメモリ上に保持しておく仕組みである。これにより、新しいトークンを生成するたびに過去の文脈を再計算する必要がなくなり、推論速度が大幅に向上する。しかし、文脈(コンテキストウィンドウ)が長くなるほどKVキャッシュのデータ量は肥大化し、HBMの容量を圧迫するため、HBFのような大容量メモリでの管理が期待されている。
AIサーバー向けHBM増産が進むほど、PC・スマホ向け汎用DRAMの供給が細るという逆説的な構造を、TrendForceが2027年グローバルメモリ市場1.28兆ドル予測の根拠として提示。エージェント型AIのKVキャッシュ需要急増と製造ラインの奪い合いが生む二重の価格高止まり圧力を解説。

AI需要によるDRAM価格の高騰を受け、CXL接続の外部メモリアプライアンスがサーバー更新の主流となる可能性がある。CXLはDRAMの総供給量を増やさないが、サーバーごとのメモリ容量をプールし、必要なホストへ割り当てることで、設備投資の無駄を削減し、効率的なメモリ調達を可能にする。

Googleは、Gemma 4の推論を最大3倍高速化するMulti-Token Prediction対応ドラフトモデルを公開した。このモデルは、投機的デコード技術によりトークン生成と検証を分離し、VRAM帯域幅のボトルネックを解消することで、エッジデバイスやローカルPCでの推論品質を低下させることなく大幅に改善する。

DeepSeek-AIは、100万トークンのコンテキスト長を持つDeepSeek-V4シリーズのプレビュー版を公開した。DeepSeek-V4-ProとDeepSeek-V4-Flashは、それぞれ1.6兆と2840億のパラメータを持つMixture-of-Expertsモデルであり、長文推論のコスト効率を大幅に改善した。特に、Compressed Sparse AttentionとHeavily Compressed Attentionを組み合わせたハイブリッド注意機構により、1トークン推論FLOPsとKVキャッシュを大幅に削減し、大規模言語モデルの運用コスト低減に貢献する。

2026年、生成AI市場の爆発的な拡大に伴い、半導体業界はかつてない「メモリ危機」に直面している。NVIDIAのGPUが市場を席巻する一方で、その演算能力を支えるデータ供給路、すなわちメモリ帯域と容量が、物理的な限界を迎 […]

2026年1月、ラスベガスで開催されたCES 2026において、Phison Electronicsは、「aiDAPTIV+」テクノロジーの拡張版を発表した。同社はこれにより、高価なGPUメモリ(VRAM)の限界という、 […]
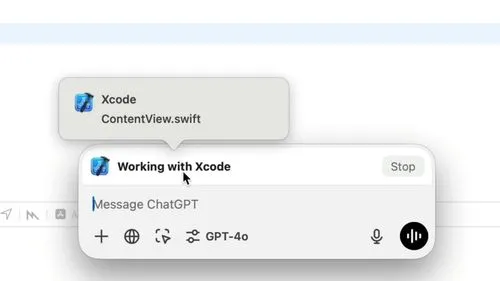
OpenAIは、macOS向けChatGPTネイティブアプリに大規模なアップデートを実施し、VS Code、Xcode、Terminal、iTerm2などの開発者向けアプリケーションとの連携機能を導入した。この新機能によ […]