
人類は半導体というシリコンのキャンバスに、極小のトランジスタというスイッチを数百億個も敷き詰め、0と1が支配する決定論的な宇宙を構築してきた。計算機とは本来、同じ入力を与えれば必ず同じ出力を返す「完璧な秩序」の体現者である。しかし、人工知能が単なるデータ識別機から、未知の画像や文章を創り出す「生成AI」へと進化したことで、この決定論的宇宙に巨大なパラダイムの亀裂が生じた。
生成モデルには、数学的な正確さに加えて、予測不可能な「ランダム性」というカオスが不可欠となる。キャンバスに全く新しい絵を描くためには、潜在空間と呼ばれる広大な確率の海から、偶然の座標を拾い上げる作業(サンプリング)を経なければならない。秩序を極めたシリコンチップの上で、いかにして「完璧なサイコロ」を振るのか。これまでエンジニアたちは、ソフトウェアのアルゴリズムで疑似乱数を生成したり、ノイズ発生に特化した専用回路を外付けしたりして急場を凌いできた。だが、このパッチワークのような設計思想は、チップ上のシリコン面積を無駄に食いつぶし、データ転送の遅延を生み、何より膨大な電力を浪費する原因となっていた。
「秩序と無秩序。この相反する2つの性質を、たった一つの極小デバイスの中で自在に切り替えることは不可能なのか」
ソウル大学校(SNU)電気情報工学部の李鍾浩(Jong-Ho Lee)教授率いる研究チームは、材料科学と量子力学の深淵に潜む「電子の揺らぎ」を制御することで、この難題に鮮烈な解答を出した。学術誌『Nature Communications』に発表された彼らの研究は、ハフニウム酸化物をベースとした強誘電体メモリを利用し、電圧をわずかに調整するだけで「確率のサイコロ」から「正確無比な計算機」へとデバイスの振る舞いを完全に切り替える、画期的なアーキテクチャの実証である。
完璧な秩序に潜むカオスの渇望。生成AIが直面するハードウェアの矛盾
近年のAI技術を牽引する画像生成モデル(変分オートエンコーダや拡散モデルなど)は、人間の脳の働きを模倣したニューラルネットワークで構成されている。その出力プロセスは大きく二つの段階に分かれる。第一段階は、学習したデータの特徴が分布する多次元の「潜在空間」から、ランダムな変数を抽出する確率的サンプリングである。第二段階は、抽出された変数をシード(種)として、何百万もの重みパラメータを用いた膨大なベクトル・行列積(VMM)計算を行い、ピクセルの集合体である画像へと復元(デコード)する処理である。
計算そのものは寸分の狂いも許されない決定論的なプロセスである一方、サンプリングには真の意味での確率的ノイズが要求される。既存のハードウェアアーキテクチャにおいて、この二つの要求を満たすことは構造的な矛盾を抱え込むことと同義であった。従来のプロセッサは決定論的な演算に特化して設計されている。そのため、ノイズを生成するためだけに乱数生成器(TRNG)のような追加のハードウェアブロックを配置するか、外部メモリとの間で頻繁にデータをやり取りする必要がある。
スマートフォンやウェアラブルデバイスのようなエッジ環境で生成AIを動かそうとする際、この分離されたアーキテクチャは致命的なボトルネックとなる。バッテリー駆動の限られた電力と小さなチップ面積の中で、ノイズ生成とデコード計算のモジュールを行き来するデータの移動は、演算そのものよりもはるかに多くのエネルギーを消費してしまう。高度な生成モデルを小さなデバイスに収めるためには、この物理的なデータ移動を根絶する全く新しいアプローチが必要とされていた。
誘電体が囁くノイズ。フェルミ準位と欠陥が仕掛ける電子のトリック
ソウル大学校のチームが目を向けたのは、ハフニウム酸化物()を用いた強誘電体トンネル接合(FTJ)というミクロな素子である。強誘電体とは、外部から電圧をかけると内部の電気的な極性(分極)の向きが揃い、電圧を切ってもその状態を長期間保持する性質を持つ材料だ。これをナノメートル単位の極薄いトンネル絶縁膜と組み合わせることで、抵抗値を複数段階にわたって自在に記憶できるアナログメモリを実現できる。これは、ニューラルネットワークの「重み」をそのまま物理的な抵抗値として保持し、オームの法則とキルヒホッフの法則を利用して一瞬でVMM計算を実行する強力な演算素子となる。
しかし、研究チームの真のブレイクスルーは「計算」の方にあるのではない。彼らは、通常は素子の劣化や誤作動の原因として忌み嫌われる「欠陥(トラップ)」を、極めて洗練されたノイズジェネレーターへと昇華させた。
FTJの構造は、上部電極(チタンナイトライド:TiN)と下部電極(多結晶シリコン)で、厚さ7 nmの 強誘電体層と1.2 nmの トンネル障壁を挟み込んだものである。この極薄の障壁の内部には、製造過程における原子配列の乱れに起因する「電子の落とし穴(トラップ状態)」が点在している。
研究チームは、TiN電極に3.2 Vという絶妙な電圧を印加すると、電極内の電子が持つエネルギー(フェルミ準位 )の高さが、トンネル障壁内に存在する特定のトラップのエネルギー準位(、伝導帯の端から1.9 eV下にある)とピタリと一致することを発見した。
日常の風景に例えるなら、ダムの水位(電圧)をミリ単位で微調整し、水面の高さを水門の縁と完全に同じ高さに合わせた状態を想像してほしい。波のわずかな揺らぎによって、水が水門を越えたり越えなかったりするだろう。ミクロな世界では、電子がトラップに飛び込んだり(捕獲)、飛び出したり(放出)する速度が完全に釣り合い、コインの裏表を予測するような確率的イベントへと変貌する。この電子の出入りによって、素子を流れる電流は「高い状態」と「低い状態」の間で予測不可能に激しくスイッチングを繰り返す。物理学において「ランダムテレグラフノイズ(RTN)」と呼ばれるこの現象こそが、生成AIが待ち望んでいた完璧な「物理ダイス」なのである。
そして魔法は続く。電圧を2.0 Vへと下げると、フェルミ準位の高さがトラップから大きく外れ、電子はもはや落とし穴に出入りできなくなる。素子は突如として沈黙し、RTNは姿を消す。残されるのは、1/fノイズ領域で極めて安定した抵抗値を示す、信頼性の高い記憶素子である。一つの極小素子が、指揮棒(電圧)の振り方ひとつで、ノイズを撒き散らすカオスから、静寂の中で行列積をこなす演算器へと劇的な変容を遂げる。
10万回の反復に耐えるシリコン上の想像力。圧倒的なエネルギー効率
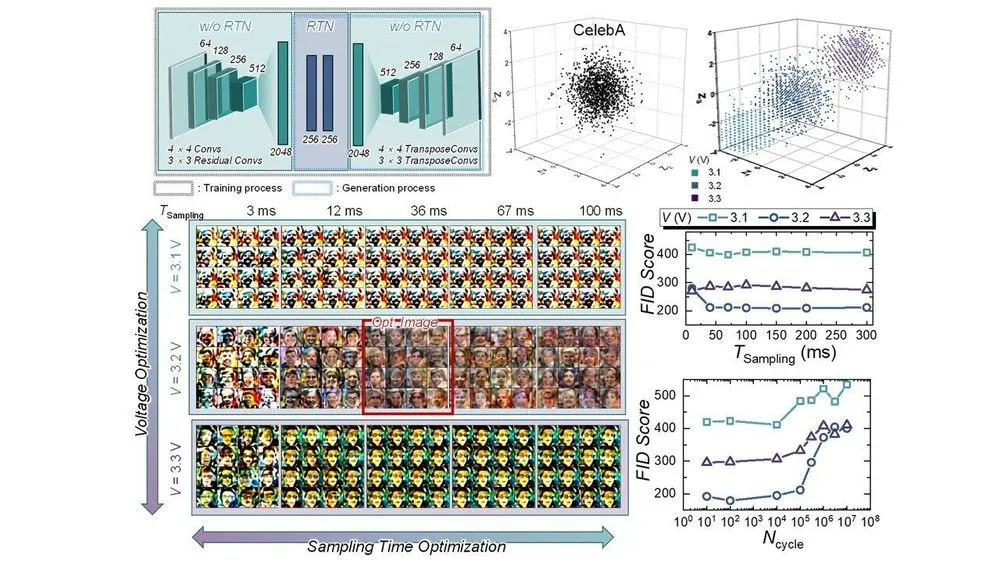
理論上の美しさを現実のシリコン上に具現化するため、チームは標準的なCMOS半導体製造プロセスと完全に互換性のある手法を用い、6インチウェハー上に20×20のNOR型FTJアレイを実際に製造した。
実証実験では、顔画像データセット(CelebA)を用いて変分オートエンコーダ(VAE)をハードウェア上で動かし、未知の顔画像を生成させた。確率的サンプリングを行う際、RTNのランダム性が最も理想的なバランスに達するよう、3.2 Vの電圧下でサンプリング時間を36 ms(ミリ秒)に最適化。この条件下で抽出された潜在変数は、見事なガウス分布を極めて高い精度で再現した。電圧が高すぎても低すぎても、ノイズの発生確率が一方に偏り、生成される顔画像が特定の特徴に偏ってしまう(モード崩壊)現象が起きる。しかし、最適化されたFTJアレイは髪型や顔の向き、肌の質感など、多様な特徴をバランスよく生成することに成功した。
さらに驚異的なのは、その耐久性とエネルギー効率である。このFTJアレイは、強誘電体の分極反転(書き込みサイクル)を10万回($10^5$ サイクル)繰り返した後でも、生成画像の品質を示すFréchet Inception Distance(FID)スコアの悪化を引き起こさなかった。
| 評価指標・構成要素 | 従来型AIアクセラレータ (例: TPU, デジタルCMOS) | 提案手法 (HfO2 FTJアレイ) | 構造的優位性 (So What?) |
|---|---|---|---|
| サンプリング機構 | ソフトウェア疑似乱数 + 外部DRAM / 専用TRNG回路 | 単一素子でのRTN物理ノイズ抽出 (3.2 V動作) | ノイズ生成回路や外部メモリの配線を削減し、チップ面積とデータ転送遅延を劇的に排除。 |
| デコード計算機構 | デジタルMAC演算器 (SRAMから都度重みをロード) | 多値抵抗を利用したアナログVMM計算 (2.0 V動作) | メモリと計算を一体化(Compute-in-Memory)し、フォン・ノイマン型ボトルネックを打破。 |
| エネルギー効率 | ~430 fJ / MAC (8-bit) | < 10 fJ / MAC | 計算時の消費電力を40分の1以下に抑制。モバイル端末やバッテリー駆動機器でのエッジAI生成を現実にする。 |
| 製造プロセス | 先端微細化プロセスへの依存 | 既存のCMOSプロセスと完全互換 | 特殊な設備投資なしで、巨大な工場でのスケールアップと即時量産化が可能。 |
既存のデータセンターで稼働するテンソル・プロセッシング・ユニット(TPU)が1回の積和演算(MAC)に約430 fJのエネルギーを消費するのに対し、FTJアレイは10 fJを下回る極限の省電力を記録した。チップの面積、レイテンシ、消費電力という3つの物理的な枷を同時に外す、極めてエレガントな工学的飛躍である。
エッジデバイスが夢を見る未来。巨大GPU帝国への反逆と残されたパズル
この研究がもたらす最大の学術的・産業的インパクトは、AIハードウェア市場全体の勢力図を塗り替えるポテンシャルにある。
現在、生成AIの進化を根底で支えているのは、NVIDIAが供給する巨大で高価なGPU群である。しかし、これらのチップはデータセンターでメガワットクラスの電力を貪り食い、発熱の限界という物理的な壁に直面している。計算資源の極端な中央集権化は、莫大な運用コストだけでなく、通信遅延やプライバシー侵害のリスクを伴う。 一方、AppleやQualcommといったプレイヤーは、スマートフォンやスマートウォッチ上でAIプロセスを完結させる「オンデバイスAI」および「エッジNPU」市場の覇権を激しく争っている。ここで立ちはだかるのが、限られたバッテリー容量とシリコン面積という冷酷な制約だ。どれほど優れた生成アルゴリズムを開発しても、モバイル端末の上でノイズ生成とデコード計算を行き来させれば、バッテリーは瞬く間に尽きてしまう。
ソウル大学校のチームが示したアーキテクチャは、このエッジAI市場における強烈なゲームチェンジャーとなる。ノイズ生成と計算をたった一つの素子で完結させ、かつ強誘電体ハフニウム酸化物という「すでによく知られた材料」を用いたことは決定的だ。量子デバイスや特殊なスピン素子のように、基礎研究の実験室から抜け出すために数十年の歳月を必要としない。既存のメガファブ(巨大半導体工場)のCMOS製造ラインにそのまま乗せ、新たな設備投資なしで即座に量産化への道を描くことができる。
もちろん、リアルタイム処理に向けた工学的な課題は残されている。論文内でも言及されている通り、最適化された36 msというサンプリング時間は、高解像度の動画を30 fps(秒間30フレーム)で滑らかに生成するにはまだ時間がかかりすぎる。今後の研究ギャップとして、メモリアレイ自体の集積度を大規模に引き上げること、複数のビットストリームを同時並行でサンプリングするための回路設計、さらには微小なアナログ電流をデジタル信号に変換する周辺回路(ADC)の電力最適化が喫緊の課題となるだろう。
「確率的サンプリングと決定的計算。この二つの機能の同時実現こそが、生成AIハードウェアにおける最大の挑戦であった」と李教授は語る。
ノイズは長らく、半導体技術者にとって排除すべき敵であった。しかし今、彼らはそのノイズの波長を精緻に読み解き、創造性の源泉としてチップの中に飼いならした。手のひらの上の小さなシリコンが、外部のクラウドに頼ることなく自らの内なる揺らぎを絵筆に変え、自律的に「夢を見る」時代の足音が、確実に近づいている。