
スペインを拠点とする大手グラフィックデザインプラットフォームFreepikが、AIスタートアップFal.aiとの協業により、新たなAI画像生成モデル「F Lite」をリリースした。特筆すべきは、このモデルがFreepik自身の保有するライセンス済みデータのみで学習されている点、そしてオープンソースとして公開された点だ。生成AIを取り巻く著作権問題が議論を呼ぶ中、この「クリーン」なモデルは業界に一石を投じるの物となるのだろうか?
なぜ今「著作権セーフ」なAIモデルなのか? – 生成AIを取り巻く法的リスク
近年、MidjourneyやOpenAI(DALL-E)、Stability AI(Stable Diffusion)といった高性能なAI画像生成モデルが次々と登場し、クリエイティブ業界に衝撃を与えている。しかし、その開発プロセスにおいては、インターネット上から収集された膨大なデータが利用されており、その中には著作権で保護されたコンテンツも含まれることが少なくない。
このため、アーティストや権利者からは著作権侵害を訴える声が上がり、実際に複数のAI企業が訴訟に直面している。 AI企業側は、学習目的でのデータ利用は「フェアユース(公正利用)」にあたると主張することが多いが、法的な決着はまだついていない。
このような状況下で、著作権問題をクリアした「安全な」データセットで学習されたAIモデルへの需要が高まっている。AdobeのFirefly、Getty Images、Shutterstockなどが既に同様のアプローチを取っているが、FreepikのF Liteは、この流れに乗りつつ、「オープンソース」という形でコミュニティへの貢献を目指す点が特徴的だ。
Freepikの新星「F Lite」とは? – 100億パラメータのオープンモデル

今回発表されたF Liteは、単なる新たな画像生成ツールの登場というだけに留まらない、いくつかの重要な特徴を持っている。
開発の背景:FreepikとFal.aiの協業
F Liteは、グラフィック素材プラットフォームとして知られるFreepikと、AIインフラを提供するスタートアップFal.aiの共同研究開発によって生まれた。 それぞれの強みを活かし、ゼロからモデル構築に取り組んだという。
学習データ:8000万枚の「安全な」画像
F Liteの最大の特徴は、その学習データにある。一般的な大規模モデルが数十億枚以上の画像を学習に用いるのに対し、F LiteはFreepikが権利を保有する、約8000万枚の高品質かつ著作権的に安全(legally compliant and SFW)な画像のみで学習されている。 これは、同規模の公開モデルとしては初めて、完全に「クリーン」なデータのみで学習されたケースとなる可能性がある。
技術基盤:DiTアーキテクチャと100億パラメータ
モデルの心臓部には、近年注目を集める「Diffusion Transformer(DiT)」アーキテクチャを採用。 パラメータ数は約100億に達し、テキストによる指示(プロンプト)を画像に変換する能力を持つ。
学習環境:NVIDIA H100 GPU 64基を駆使
この大規模モデルの学習には、NVIDIAの高性能GPU「H100」が64基用いられ、約2ヶ月の期間を要した。 これは、他の最先端モデルと比較すると「中程度」の計算資源とデータ量であり、限られたリソースでどこまでの性能が達成できるかを示す試金石とも言えるだろう。
オープンソースという選択:開発者コミュニティへの期待
FreepikとFal.aiは、F Liteのモデルウェイト(Regular版とTextured版の2種類)とコードをオープンソースライセンスで公開した。 これにより、開発者は自由にモデルを改変したり、特定のスタイルにファインチューニングしたり、あるいは他のツールと連携させたりすることが可能になる。 Freepikらは、コミュニティによる更なる改善とイノベーションに期待を寄せているようだ。
F Liteの技術的詳細と革新性
F LiteのTechnical Reportからは、その開発における工夫や発見が見て取れる。
DiTベースのアーキテクチャとクロスアテンション
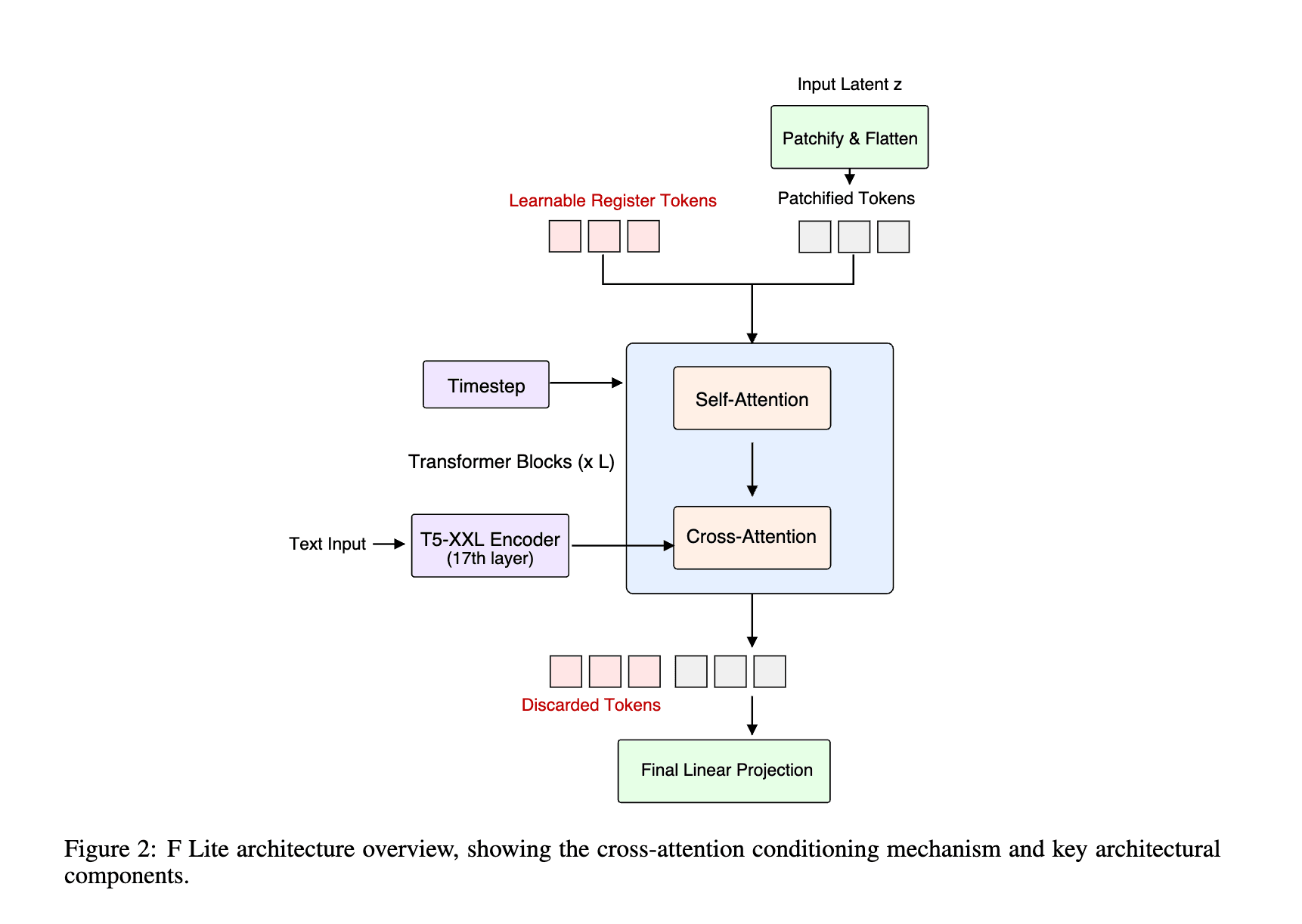
基盤となるのはDiTだが、テキスト情報を画像生成プロセスに組み込む方法として、計算効率(FLOP効率)を考慮し、クロスアテンション方式を採用している。 これは、画像トークンがテキストトークンに「注意(Attention)」を向けることで、指示内容を反映させる仕組みだ。 また、学習の安定化や表現力向上のために、Register TokensやResidual Value Connectionsといった比較的新しい技術も導入されている。
テキスト理解の鍵:T5エンコーダー中間層活用の妙
通常、テキストプロンプトの意味を理解するためには、T5のような大規模言語モデル(テキストエンコーダー)が用いられる。F Liteの開発チームは、T5-XXLエンコーダーの最終層ではなく、中間層(具体的には17層目)の出力を利用することで、学習効率が25-30%向上するという興味深い発見をした。 これは、最終層に近づくにつれて失われる情報の「一般性」が、画像生成のコンディショニングにはより適している可能性を示唆している。
安定性と効率を追求した学習戦略
大規模モデルの学習は不安定になりがちだが、F Liteでは「μ-Parameterization (μP)」と呼ばれる手法を用いて、ハイパーパラメータ(学習率や重み減衰など)を安定化させている。 また、「Warmup-Stable-Decay (WSD)」学習率スケジュールや、画像の解像度に応じてノイズの加え方を調整する「Resolution-Aware Timestep Sampling」、学習中に画像パッチの一部をランダムに省略する「Sequence Dropout」など、効率と安定性を両立するための様々なテクニックが駆使されている。
さらなる品質向上へ:SFTとRLHFによるチューニング
初期学習(Pre-training)の後、さらに高品質な約10万枚のデータセットを用いたSupervised Fine-Tuning (SFT)と、人間の好みを学習させるReinforcement Learning from Human Feedback (RLHF) によって、モデルの出力品質とユーザーの指示への追従性が高められている。 RLHFにおいては、当初MaPOという手法を用いていたが、安定性に課題があったため、DeepSeekのGRPOという手法を応用し、より安定した改善を実現したという。
F Liteの実力は? – 得意分野と克服すべき課題
さて、肝心の生成画像の品質はどうだろうか? Freepik自身も認めているように、F Liteは万能ではなく、得意なことと苦手なことがある。
強み:イラスト、ベクタースタイル、複雑な指示への追従
F Liteは、その学習データの特性を反映し、特にイラストレーションやベクターグラフィック風の画像を生成することに長けている。 また、比較的長く詳細なプロンプトに対して、その内容を忠実に反映した多様な画像を生成できる能力も示している。
課題:写真のようなリアリティ、複雑な構造、短い指示、文字生成
一方で、いくつかの限界点も報告されている。
- 写真のような質感: 特にフォトリアリスティックな画像において、肌の質感や布地の細かなディテールなどが不足することがある。
- 複雑な構造や人体: 複雑な構図や人体の正確な描写において、不自然な点(アナトミカルなエラー)が生じることがある。これは生成モデル共通の課題でもあるが、F Liteでも見られるようだ。
- 短いプロンプト: 学習データが詳細な記述を伴うものが多かったためか、非常に短い、曖昧なプロンプトでは期待通りの結果が得られにくい傾向がある。
- 文字のレンダリング: 画像内に正確な文字を描画することは、依然として難しい課題のようだ。
なぜ限界があるのか?データと計算資源の制約
これらの限界は、モデルアーキテクチャや学習方法が根本的に間違っているというよりは、主に使用された学習データ量(約8000万枚)と計算資源(H100 64基 x 2ヶ月)の制約によるものだと開発チームは分析している。 より多くのデータと計算時間を投入すれば、これらの課題は大幅に改善される可能性がある、というわけだ。 DiffusionモデルのScaling Law(規模則)に関する研究も、この仮説を裏付けている。
誰でも使える? F Liteの利用方法と注意点
オープンソースとして公開されたF Liteだが、利用するにはいくつかの点に留意する必要がある。
公開場所:GitHubとHugging Face
モデルのコードはGitHubで、学習済みウェイト(パラメータ)はHugging Faceで(RegularとTextured)公開されている。 これらを利用すれば、ComfyUIのようなツールに組み込んだり、Pythonのdiffusersライブラリ経由で利用したり、あるいは自身でファインチューニングを行うことが可能だ。
デモ環境:Hugging FaceとFal.aiで試用可能
手軽に試してみたいユーザー向けに、Hugging Face SpacesとFal.ai上でデモが公開されている。 プロンプトを入力するだけで、F Liteが生成する画像を体験できる。
| F Lite Regular: | Hugging Face space | Fal |
| F Lite Texture: | Hugging Face space | Fal |
必要なスペック:最低24GB VRAM搭載GPU
ただし、ローカル環境でF Liteを動作させるには、それなりのマシンパワーが必要となる。具体的には、最低でも24GBのVRAM(ビデオメモリ)を搭載したGPUが必要だとされている。 一般的なコンシューマー向けPCでは少々ハードルが高いかもしれない。
選べる2つの「味」:RegularとTextured
Freepikは、特性の異なる2つのバージョンのウェイトを公開している。
- F Lite Regular: より予測可能で、プロンプトに忠実な汎用版。
- F Lite Textured: より豊かな質感と美的品質を持つが、エラーも出やすいクリエイティブ向け版。ベクター画像や短いプロンプトには不向きな場合がある。
用途に応じて使い分けることが推奨されている。
競合ひしめくAI画像生成市場におけるF Liteの位置づけ
F Liteは、AI画像生成モデルの市場において、どのような立ち位置を占めるのだろうか?
Adobe FireflyやGetty Imagesとの違い:オープンソースの意義
Adobe FireflyやGetty Images、Shutterstockなども、ライセンス済みデータに基づく「商用利用可能な」AIモデルを提供しているが、これらは基本的にクローズドなプロプライエタリモデルだ。 一方、F Liteはオープンソースである点が決定的に異なる。これにより、研究者や開発者はモデルの内部構造を理解し、自由に改良・拡張することができる。これは、AI技術全体の発展に貢献する可能性を秘めている。
著作権リスクを避けたい開発者にとっての福音となるか?
著作権侵害のリスクを懸念する企業や開発者にとって、F Liteは魅力的な選択肢となり得るだろう。学習データがクリーンであることが保証されているため、安心して利用・改変できる基盤モデルとして活用が期待される。 もちろん、前述の通り性能面での限界はあるため、現時点ですべての用途に適しているとは言えないが、今後のコミュニティによる改善次第では、その存在感を増していくかもしれない。
Freepikはどこへ向かうのか? – ストックフォト企業のAI戦略
Freepikは、もともとデザイナーや企業向けにベクター画像、写真、イラストなどのストックメディアを提供するスペインの企業だ。 近年、AI技術への投資を積極的に進めており、画像編集やコンテンツ作成を支援するAIツールを提供してきた。
今回のF Liteリリースは、単なる技術デモンストレーションに留まらず、FreepikのAI分野におけるリーダーシップを示し、プラットフォームの価値を高め、開発者コミュニティとの連携を深める狙いがあると考えられる。将来的には、F Liteをベースにした新たなサービス展開なども視野に入れているのかもしれない。
オープンソースAIの未来を拓くか

FreepikとFal.aiによるF Liteのリリースは、いくつかの点で注目に値する。
第一に、著作権的にクリーンなデータのみで学習された、比較的大規模(100億パラメータ)なAI画像生成モデルをオープンソースで公開した点。これは、責任あるAI開発のあり方を示す一つのマイルストーンと言えるだろう。
第二に、限られたデータと計算資源の中で、最新の技術トレンドを取り入れながら高性能モデルを構築する試みとその技術詳細を公開した点。これは、他の研究者や開発者にとって貴重な知見となる。
第三に、性能面での限界を認めつつも、オープンソースコミュニティの力による今後の発展に期待を寄せている点。
Freepikは、より多くのクリエイターが利用できるよう、GPU要件を緩和した軽量版「micro version」の開発も計画しているという。
F Liteが今後、コミュニティの手によってどのように進化していくのか、そして著作権問題を巡る議論が続く中で、このような「オープンでクリーンな」モデルがAIエコシステムの中でどのような役割を果たしていくのか、注目していきたい。
Sources