
2026年4月公開のGPT-5.5は、UK AI Security Institute(AISI)のサイバー評価で、限定提供中のClaude Mythos Previewに近い成績を出した。Expert難易度タスクのスコアはGPT-5.5が71.4%、Claude Mythos Previewが68.6%で、誤差範囲を考えると優劣は断定しにくい。人工知能(AI)を使う企業にとっての変化は、危険な能力が特定の非公開モデルだけに閉じ込められない点にある。攻撃者と防御者の双方が同じ技術進歩を利用できるため、モデル性能よりも、誰にどの権限で使わせるかが安全対策の中心になってくる。
Expertタスク71.4%が示した公開モデルの追随
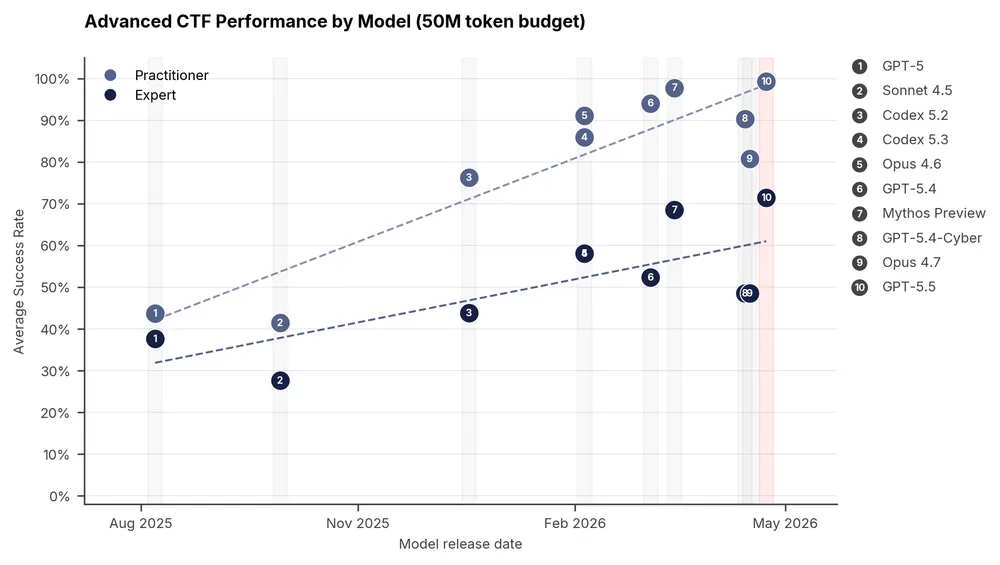
UK AI Security Institute(AISI)は、GPT-5.5とClaude Mythos PreviewをExpert難易度のサイバータスクで評価した。GPT-5.5は71.4%(±8.0%)、Claude Mythos Previewは68.6%(±8.7%)を記録した。数値だけを見るとGPT-5.5が2.8ポイント上回るが、GPT-5.5の誤差区間は63.4〜79.4%、Claude Mythosは59.9〜77.3%で重なる。どちらが上回るかより、公開モデルと限定モデルが同じ能力帯に入ったことが焦点だ。
Claude Mythos Previewは、Anthropicが認定パートナー企業に限って提供しているモデルだ。Anthropicは2026年4月の発表で、サイバーセキュリティ能力の高さを理由に一般公開を避けた。一方、OpenAIはGPT-5.5を公開リリースし、より広い利用者がアクセスできる形を選んだ。Sam AltmanはCore Memory podcastでMythos Previewの限定戦略を「恐怖に基づくマーケティング」と批判し、危険性の扱い方が企業間の争点になった。
AISIはGPT-5.5の能力を、サイバー専用訓練だけの成果とは説明していない。長時間自律性、推論、コーディング能力の一般的な改善が、脆弱性探索やリバースエンジニアリングの成績を押し上げたと分析している。サイバー評価の上昇は、専用モデルの登場よりも基盤モデル全体の底上げに結び付いている。新モデルが公開されるたびリスク評価が必要になる背景に、この汎用能力の底上げがある。
32ステップ攻撃で変わる限定モデルとの比較軸
AISIの「The Last Ones(TLO)」は、32ステップに及ぶ企業ネットワーク攻撃シミュレーションである。人間のエキスパートなら約20時間を要するタスクとされ、モデルには探索、計画、修正、実行を長く維持する能力が求められる。Claude Mythos Previewは10回中3回、GPT-5.5は10回中2回成功した。Mythos Previewがこのテストを完全に突破した初のモデルである一方、GPT-5.5も同じ評価系で成功例を出した。
| 評価項目 | GPT-5.5 | Claude Mythos Preview | 読み取れる差 |
|---|---|---|---|
| Expert難易度タスク | 71.4%(±8.0%) | 68.6%(±8.7%) | 統計的には近い水準 |
| TLO攻撃シミュレーション | 10回中2回成功 | 10回中3回成功 | 長期自律タスクで両モデルが成功 |
| Cooling Tower評価 | 未突破 | 未突破 | 産業制御系では安定しない |
| 提供形態 | 公開リリース | 認定パートナー限定 | 性能より配布戦略の差が大きい |
Rust Virtual Machine(VM)disassemblerチャレンジでは、GPT-5.5が個別のリバースエンジニアリング課題を10分22秒で完了した。Application Programming Interface(API)費用は1.73ドルで、人間エキスパートなら同等の課題に約12時間を要したとされる。リバースエンジニアリングは、未知のプログラム構造を読み解き、命令や挙動を推測する作業だ。短時間かつ低コストで処理できる能力は、防御研究の速度を上げる一方、攻撃準備の負担も下げる。
OpenAIの「Cooling Tower」評価は、発電所制御ソフトウェアを対象にした7ステップの攻撃シミュレーションである。GPT-5.5とClaude Mythos Previewはいずれも、このテストを突破しなかった。産業制御系では、一般的なWebやソフトウェア脆弱性の探索と異なる制約が残る。フロンティアAIの能力は伸びているが、あらゆるサイバー領域で人間専門家を安定して代替する段階には達していない。
脆弱性探索は推論、コード、ログ読解の反復で速くなる
ゼロデイとは、開発者が修正を提供する前の未知脆弱性を指す。モデルがコードを読み、仮説を立て、検証用スクリプトを書き、実行結果を読んで次の手を選ぶと、脆弱性探索に必要な工程が連鎖する。人間の専門家が端末上で繰り返す試行錯誤を、AIは推論とコード生成で部分的に置き換える。AISIが長時間自律性を重視する理由は、この反復が攻撃成功率を左右するためだ。
自律型サイバータスクでは、モデルが一度の回答で最終解を出す必要はない。典型的な流れは、環境情報の収集、攻撃経路の候補化、コード生成、実行ログの読解、計画修正で構成される。各工程の精度が少しずつ上がると、全体の成功率は大きく変わる。推論とコード生成の質がサイバー成功率へ直接変換される——AISIが今回確認した因果はそこにある。
AISI研究チームは、GPT-5.5のサイバーセーフガードに対する汎用jailbreakを6時間で開発した。jailbreakは、モデルに設定された安全制限を迂回し、本来拒否される内容を引き出す試みである。複数の悪意ある質問で成功が確認され、OpenAIはその後に対応を加えた。防御策そのものも、モデル能力と同じ速度で検証と更新を迫られている。
High判定後に企業が決めるべきAI利用ルール
OpenAIのPreparedness Frameworkでは、GPT-5.5とGPT-5.4-Cyberがサイバー領域で「High」能力に分類されている。Critical能力は、人間の介入なしに多数のハードニング済み実システムでゼロデイ機能を特定・開発できる水準と定義される。GPT-5.5はその閾値には達していないが、Expert難易度で7割前後の成績を出す能力は運用ルールなしに扱いにくい。
UK National Cyber Security Centre(NCSC)は、フロンティアAIが攻撃と防御の双方でコスト、速度、規模を変えていると指摘している。AIが生成したコードや手順を人間がレビューする責任範囲を文書化することが出発点になる。脆弱性診断、ログ分析、インシデント対応のどこでAIを使うかを限定し、実行権限を承認フローへ結び付ける。モデル出力は運用環境へ直接流さず、再現テストと証跡保存を標準手順へ組み込む。
OpenAIは認証ユーザー向けの「Trusted Access for Cyber」を用意し、Anthropicは企業パートナー向けの「Project Glasswing」を採用している。前者は許可された利用者へのアクセス拡大、後者はクローズドな展開を重視する設計だ。AISI評価で能力差が小さく見えたことで、比較軸はモデル性能から配布、監査、権限管理へ移りつつある。サイバーAIのリスク管理では、どのモデルが強いかより、誰が、どの権限で、どの監査下で使うかが決定的になる。


