FacetuneやVideoleap等のモバイルアプリで知られるスタートアップLightricksが、最新のAI動画生成モデル「LTXV-13B」をリリースした。オープンソースとして公開されたこのモデルは、コンシューマー向けハードウェアで動作しながらも、驚異的な速度と品質を両立。OpenAIやGoogleといった巨人に挑戦状を叩きつけている。
オープンソース化された驚異のAI動画生成モデル「LTXV-13B」とは何か?
Lightricksは、今回発表したオープンソース動画生成モデル「LTXV-13B」において、AI動画生成の分野に新たな金字塔を打ち立てたといえる。
このLTXV-13Bは、2023年11月に発表され注目を集めたLightricksのオリジナルモデル「LTXV」(20億パラメータ)を大幅にアップグレードしたものだ。 パラメータ数を130億へと飛躍的に増大させ、その機能を強化することで、動画出力の品質を劇的に向上させつつ、その驚異的な処理速度を維持しているとされる。 Lightricksの主力ツール「LTX Studio」の一部として利用可能なLTXV-13Bは、コンシューマーグレードのハードウェア上で動作しながらも、「驚くほどのディテール、一貫性、そして制御性」を備えた動画を生成できると謳われている。
LTXV-13Bの最大の魅力の一つは、そのオープンソースという性質にある。Hugging FaceおよびGitHubを通じて自由にダウンロード可能であり、年間収益が1000万ドル未満の組織であれば、無料でライセンス供与されるという太っ腹な条件も提示されている。 これにより、研究者や開発者はモデルの内部構造を深く理解し、改良を加えたり、独自の機能を追加したり、さらにはサードパーティ製のアプリケーションに統合したりといった自由な活用が可能になる。
Lightricksがこのようなオープンソース戦略を採る背景には、AI業界全体のイノベーションを加速させたいという強い思いがある。最新の技術進歩を誰もが利用できるようにすることで、さらなる発展の土壌を育むことを目指しているのだ。 また、基盤モデルをできるだけ多くの開発者の手に渡らせることで、同社の有料プラットフォームの利用者を増やすという、計算された戦略も見え隠れする。
なぜコンシューマーGPUで高速・高品質を実現できたのか? 核心技術「マルチスケールレンダリング」
LTXV-13Bが特に注目されるのは、高価なエンタープライズ向けGPUを必要とせず、一般的なコンシューマーグレードのGPU(グラフィックボード)で動作するという点だ。 これは、AI動画生成における大きな課題であった計算リソースの壁を打ち破るものであり、より多くのクリエイターにとって高度な動画生成技術が身近になることを意味する。
この効率性を実現する核心技術が「マルチスケールレンダリング」だ。 Lightricksの共同創業者兼CEOであるZeev Farbman氏は、これを「今回のリリースにおける最大の技術的ブレークスルー」と語る。
このアプローチは、 まるでアーティストが複雑な絵画を制作するプロセスに似ている。最初は粗いスケッチから始め、徐々に細部を描き込み、色彩を加えていくように、LTXV-13Bも動画を段階的に詳細化しながら生成する。 Zeev Farbman氏は「粗いグリッドから始め、シーンやオブジェクトの動きの大まかな近似を得る。その後、シーンはタイルに分割され、各タイルが徐々により詳細な情報で満たされていくのだ」と説明する。
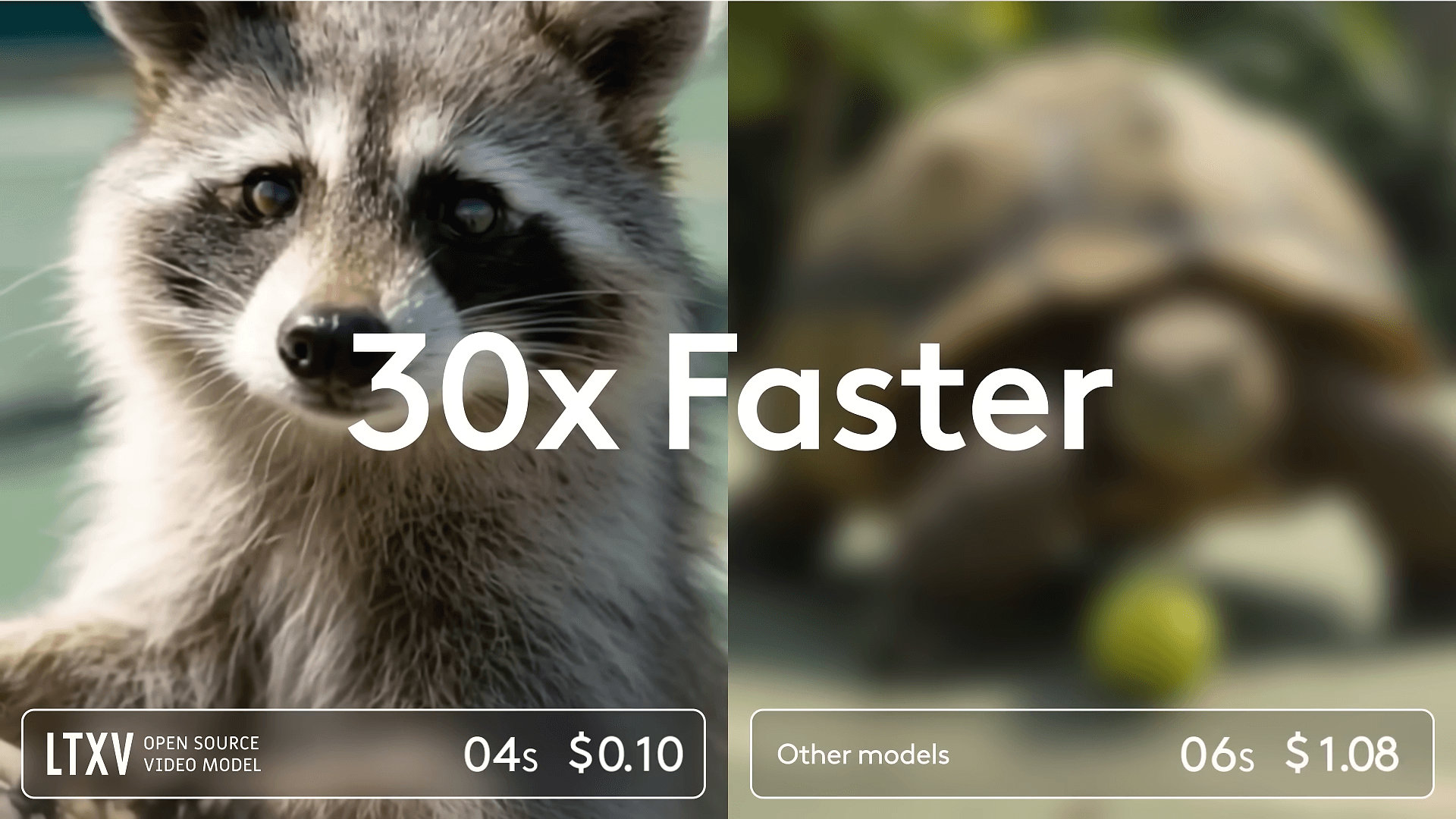
この手法の利点は主に二つある。第一に、より洗練された視覚的ディテールを持つ高品質な動画が得られること。 第二に、これが非常に高速であることだ。Zeev Farbman氏によれば、このアプローチにより「VRAMのピーク使用量は最終解像度ではなく、タイルサイズによって制限される」ため、同程度のパラメータ数を持つ競合モデルと比較して、高解像度ビデオのレンダリング速度が最大で30倍も高速になる場合があるとしている。
Zeev Farbman氏は、コンシューマー向けGPUとエンタープライズ向けGPUの主な違いはVRAM(ビデオメモリ)の量にあると指摘する。「NVIDIAはゲーミングハードウェアを厳格なメモリ制限付きで位置付けている。前世代の3090および4090 GPUは最大24GBのVRAMだったが、最新の5090では32GBに達する。一方、エンタープライズハードウェアは大幅に多くのメモリを提供する」と述べている。 LTXV-13Bは、これらのコンシューマー向けハードウェアの制約内で効果的に動作するように設計されており、「量子化や近似なしのフルモデルでも、3090、4090、5090といったトップクラスのコンシューマーGPU(ラップトップ版も含む)で実行できる」とZeev Farbman氏は強調する。
さらに、より圧縮された潜在空間を採用することで、品質を維持しながらメモリ使用量を削減することにも成功している。
LTXV-13Bの技術的詳細
LTXV-13Bの技術的な詳細と革新性は、Lightricksの研究者らによって発表されたプレプリント論文「LTX-Video: Realtime Video Latent Diffusion」でより深く明らかにされている。 この論文は、LTXV-13B(論文中ではLTX-Videoとして記述)が単なる既存技術の改良に留まらない、野心的なアプローチに基づいていることを示す。
LTX-Videoは、Transfomerベースの潜在拡散モデルであり、その核心は「Video-VAE(Variational Autoencoder)とDenoising Transformersの責任をシームレスに統合する」というホリスティックなアプローチにある。 従来の手法ではこれらコンポーネントが独立して扱われることが多かったのに対し、LTX-Videoは両者の相互作用を最適化し、効率と品質の向上を目指す。
特筆すべきは、その高い圧縮効率だ。論文によれば、Video-VAEは1:192という高い圧縮率を達成し、これはトークンあたり32x32x8ピクセルの時空間ダウンサンプリングによって実現されている。 この効率化は、「パッチ化処理をTransfomerの入力からVAEの入力へと再配置する」という設計変更によって可能になったと説明されている。 この高度に圧縮された潜在空間で動作することにより、Transfomerーは効率的に完全な時空間的自己注意(full spatiotemporal self-attention)を実行でき、これが時間的一貫性のある高解像度ビデオ生成に不可欠であるとされる。
しかし、高い圧縮率は本質的に微細なディテールの表現を制限する可能性がある。この課題に対処するため、LTX-VideoではVAEデコーダーに「潜在表現からピクセルへの変換」と「最終的なデノイジングステップ」の両方を担わせるという独創的な設計を採用している。 これにより、追加のアップサンプリングモジュールを必要とせずに、クリーンな結果をピクセル空間で直接生成し、微細なディテールの生成能力を維持できるとしている。
このモデルは、テキストからのビデオ生成(text-to-video)と画像からのビデオ生成(image-to-video)の両方のユースケースをサポートし、これらの能力は同時に学習される。 具体的な性能として、NVIDIA H100 GPU上で、768×512ピクセルの解像度を持つ24fpsの5秒間のビデオを、わずか2秒で生成できると報告されており、これは同規模の既存モデルを大きく凌駕するものだ。
さらに論文では、空間的および時間的な一貫性を向上させるためのRotary Positional Embeddings (RoPE)の採用 や、再構成タスクに特化した新しいReconstruction GAN (rGAN)の導入 など、様々な技術的改良点についても詳述されている。これらの技術的基盤が、LTXV-13Bの卓越した性能を支えているのだ。
著作権問題もクリアか? 倫理的なAIモデルとしての側面
AIによるコンテンツ生成において常に懸念されるのが、学習データの著作権問題である。この点において、LTXV-13Bは「倫理的なモデル」としての側面も持ち合わせている。
Lightricksは、Getty Images HoldingsおよびShutterstockという大手ストックフォトサービスと提携し、これらの企業が提供するライセンス済みの視覚資産からなる厳選されたデータセットでLTXV-13Bを学習させている。 Zeev Farbman氏は、「AIモデルの学習用データ収集は依然として法的なグレーゾーンだ」と認めつつ、「当社のエンタープライズセグメントにはこの種の問題を気にする大口顧客がいるため、彼らにクリーンなモデルを提供できるようにする必要がある」と、この提携の重要性を語る。
この高品質かつライセンス済みの学習データは、モデルの出力が視覚的に魅力的であるだけでなく、著作権侵害のリスクなしに商業的に安全に使用できることを保証するものである。 これは、特に著作権問題を懸念する企業市場において、Lightricksに有利に働く可能性がある。
LightricksのCEO、Zeev Farbman氏が語るLTXV-13Bの現在地と未来
Lightricksの共同創業者兼CEOであるZeev Farbman氏は、LTXV-13Bのリリースが「AI動画生成に関心のあるすべての人にとって極めて重要な瞬間」であると述べる。 「我々のユーザーは、より一貫性があり、より高品質で、より厳密な制御が可能なコンテンツを作成できるようになります」と、その進歩に自信を覗かせる。
Zeev Farbman氏は、LTXV-13Bが同社のすべての製品を特徴づける「スピード、創造性、ユーザビリティ」という理念に忠実でありながら、コンシューマー向けハードウェアで動作することを改めて強調する。
しかし、その一方で、現在のAI動画生成技術の限界についても率直に認めている。「もし私たちが正直に自分自身を見つめ、トップモデルを見たとしても、ハリウッド映画からはまだ程遠い。まだその段階には至っていません」とZeev Farbman氏は語る。
それでも、彼はアニメーションのような分野では、AIが時間のかかる制作作業を処理することで、すぐに実用的な応用が見込めると考えている。「ハイエンドアニメーションの制作コストを考えると、キーフレームやストーリーを考えるといった真の創造的な作業は、予算のごく一部です。しかし、キーフレーム作成は大きなリソースを必要とします」と指摘し、AIがこうした作業を効率化できる可能性を示唆する。
将来の展望として、Zeev Farbman氏は、異なるメディアタイプを共有された潜在空間で統合する「マルチモーダルビデオモデル」が次のフロンティアになると予測する。「それは音楽、音声、ビデオなどになるでしょう。そうなれば、優れたリップシンクを行うといったことも容易になる。これらすべての課題は消え去り、これらすべての異なるモダリティにわたって操作する方法を知っているマルチモーダルモデルが登場するでしょう」と、未来への期待を語る。
LTX Studioによるプロフェッショナルな動画制作体験
LTXV-13Bは、Lightricksのプレミアムプラットフォームである「LTX Studio」を通じて利用可能になる。 LTX Studioは、クリエイターがテキストベースのプロンプトを使ってアイデアを概説し、それを徐々に洗練させてプロフェッショナルなビデオを生成できるツールである。 高度な編集ツールにアクセスでき、カメラアングルの変更、個々のキャラクターの外観の調整、背景の建物やオブジェクトの編集、環境の適応など、多岐にわたる編集が可能になるとされている。
AI動画生成の民主化と、クリエイターにもたらす変革
LightricksによるLTXV-13Bのリリースは、単なる高性能な新モデルの登場以上の意味を持つ。そのオープンソース化という戦略は、AI動画生成技術の「民主化」を大きく前進させる可能性を秘めていると言えるだろう。これまで高価なハードウェアや専門知識がなければアクセスが難しかった最先端のAI技術が、より多くの研究者、開発者、そして何よりもコンテンツクリエイターの手に届くようになるのだ。
特に、コンシューマーグレードのハードウェアで動作するという点は、個人クリエイターや小規模な制作チームにとって朗報である。Zeev Farbman氏が指摘するように、年間収益1000万ドル未満のスタートアップやアーティストコミュニティがこの技術を無料で利用できることは、新たな才能の発掘や、これまでにない斬新な映像表現の誕生を後押しするかもしれない。
もちろん、Zeev Farbman氏自身が認めるように、AI動画生成技術はまだ発展途上にあり、ハリウッド映画のような長編・高品質な作品を完全に代替するには至っていない。 しかし、アニメーション制作の一部工程の効率化や、短尺動画コンテンツの制作、アイデアの視覚化といった領域では、既に大きな力を発揮し始めている。LTXV-13Bのようなモデルの登場は、その流れをさらに加速させるだろう。
著作権に配慮した学習データの利用という倫理的な側面も、今後のAI技術の社会実装においてますます重要になってくる。Lightricksの取り組みは、この点でも一つの模範を示すものと言えるのではないか。
LightricksがLTXV-13Bによって切り拓こうとしているのは、誰もが高度な動画生成AIの恩恵を受けられる未来だ。その挑戦は、動画制作のあり方を根底から変え、クリエイティビティの新たな地平を切り開く可能性に満ちている。
Sources
- GitHub: Lightricks/LTX-Video
- HuggingFace: Lightricks/LTX-Video
- VentureBeat: Lightricks just made AI video generation 30x faster — and you won’t need a $10,000 GPU