MIT、Microsoft、Googleの研究者たちが、多様な機械学習アルゴリズムを統一する画期的なフレームワーク「I-Con」を発表した。まるで化学における周期表のように、既存の手法を体系化し、未知のアルゴリズム発見への道筋を示すこの「機械学習の周期表」は、AI研究開発に新たな時代をもたらす可能性を秘めている。
I-Conフレームワーク:「機械学習の周期表」の誕生
近年、機械学習、特に表現学習(Representation Learning)の分野では、新しい手法や損失関数が次々と登場し、目覚ましい進歩を遂げてきた。しかし、その多様性ゆえに、個々の手法がどのように関連し、どのような原理に基づいているのかを理解することは困難になりつつあった。
このような状況に対し、MIT、Microsoft、Googleに所属する研究者チーム(Shaden Alshammari氏、John Hershey氏、Axel Feldmann氏、William Freeman氏、Mark Hamilton氏ら)は、「Information Contrastive Learning(I-Con)」と名付けられた統一フレームワークを開発した。この研究成果は、機械学習分野のトップカンファレンスであるICLR 2025で発表される予定である。
I-Conの核心は、驚くほどシンプルである。「多くの機械学習アルゴリズムは、データ点間の関係性を学習するという共通の数学的概念で書き直すことができる」という洞察に基づいているのだ。具体的には、I-Conは様々な手法が「教師あり表現」と「学習された表現」という二つの条件付き確率分布間の統合されたKLダイバージェンス(Kullback-Leibler divergence)を最小化していることを明らかにした。KLダイバージェンスとは、二つの確率分布がどれだけ似ているかを示す尺度である。
研究チームは、この単一の情報理論に基づいた方程式を用いることで、教師あり学習、教師なし学習、自己教師あり学習にまたがる23以上もの著名な機械学習アルゴリズム(論文発表時点)を、同じ枠組みの中で説明できることを証明した。これには、以下のような多様なタスクの手法が含まれる。
- 次元削減: SNE, t-SNE, PCA
- クラスタリング: K-Means, Spectral Clustering, Normalized Cuts
- 対照学習: SimCLR, MoCoV3, CLIP, InfoNCE, SupCon, Triplet Loss
- 教師あり学習: Cross Entropy, Harmonic Loss
- その他: 大規模言語モデル(LLM)の基盤となるMasked Language Modelingなど
これらのアルゴリズムは、それぞれ異なる種類の「関係性」(例えば、データの近接性、クラスラベルの共有、クラスタへの所属など)を学習・近似しようとするが、その根底にある数学的な目的関数はI-Conによって統一的に記述されるのである。
なぜ「周期表」なのか?体系化と予測能力
研究チームがI-Conフレームワークを「周期表」と呼ぶのには理由がある。化学の周期表が元素を特性に基づいて整理し、未発見の元素の存在を予言したように、I-Conフレームワークもまた、既存の機械学習アルゴリズムを体系的に整理するだけでなく、新たなアルゴリズムの発見を促す力を持っているからだ。
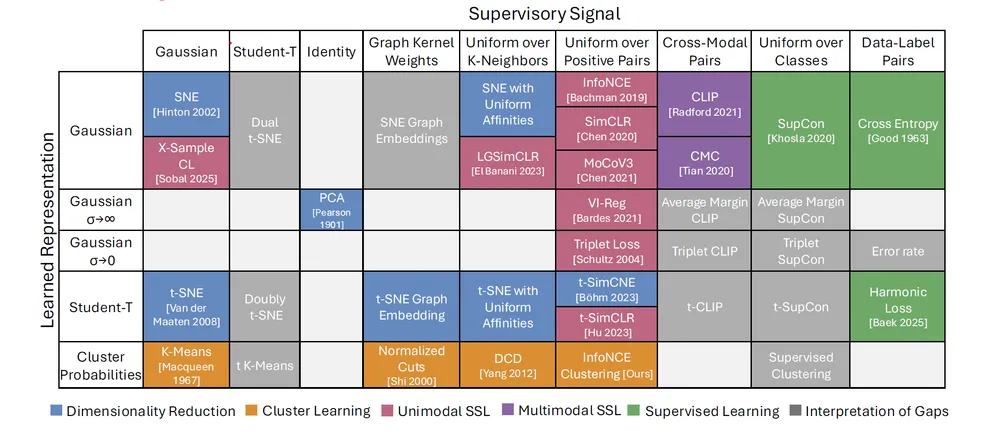
研究チームは、I-Conの枠組みで様々なアルゴリズムを分析する中で、特定の「関係性」の定義(論文中の”Supervisory Signal”)と、それを近似する方法(論文中の”Learned Representation”)が繰り返し現れることに気づいた。そこで、これらの組み合わせを表形式で整理することを試みた。これが「機械学習の周期表」である。
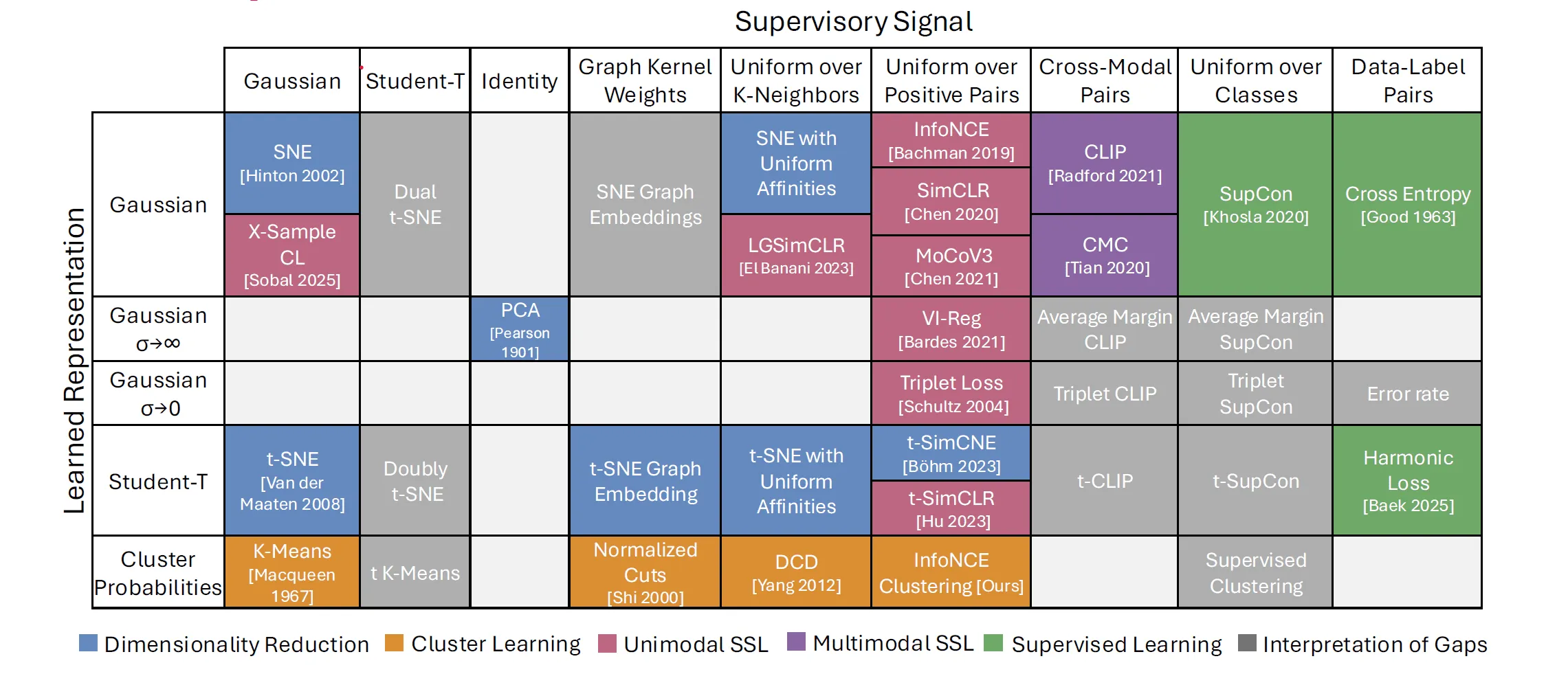
この表を作成したところ、既存のアルゴリズムが特定のマス目にきれいに収まることが分かった。さらに驚くべきことに、既知の手法で埋められない「空欄」が多数存在することも明らかになった。これらの空欄は、まだ開発されていないが、理論的には存在する可能性のある新しい機械学習技術を示唆しているのである。
MITの大学院生であり、本研究の筆頭著者であるShaden Alshammari氏は、「これは単なる比喩ではありません。私たちは機械学習を、当てずっぽうに進むのではなく、探求できる構造を持つシステムとして捉え始めています」と語る。
I-Conを理解する:クラスタリングの舞踏会
I-Conの背後にある数学的な考え方を直感的に理解するために、研究者たちは「舞踏会」の例えを用いている。
大きな舞踏会場でのパーティーを想像してほしい。あなたは数人の知り合いを除き、ほとんどが見知らぬゲストだ。突然、主催者がグラスを鳴らし、夕食のためにテーブルに着くよう合図する。あなたは友人と一緒に座るために、急いで部屋を見渡すだろう。
この場面は、I-Conにおける「クラスタリング」を理解する簡単な方法を提供している。
- 各ゲスト = データ点
- 友人 = 近い関係にある(類似した)データ点
- 各テーブル = クラスタ
ゲストは友人と一緒に座るとき最も満足し、データの構造を反映した、密なグループ(クラスタ)を形成する。しかし、必ずしもすべての友人が同じテーブルに座れるわけではない。より良い座席配置(クラスタリング)は、より多くの友人グループを維持できる。この観点から見ると、クラスタリングとは、複雑な友人関係のネットワークを、同じテーブルに座ることで形成できる関係性(クラスタ)で近似しようとする試みと言える。

広義には、多くの機械学習アルゴリズムが、この舞踏会の場面に似ている。ゲスト(データ点)がどのように友人を見つけ、テーブル(クラスタ)に配置されるか(関係性を学習・近似するか)にわずかな違いがあるだけなのだ。I-Conでは、「関係性」の定義が非常に柔軟であり、視覚的な類似性、共通のクラスラベル、クラスタのメンバーシップなど、様々な種類を取り扱うことができる。
発見の経緯:偶然から生まれた統一理論
興味深いことに、研究者たちは最初から「機械学習の周期表」を作ろうとしていたわけではなかった。Alshammari氏がWilliam Freeman教授の研究室で、画像クラスタリング(類似画像を近くのクラスタにまとめる手法)を研究していたことがきっかけとなった。
彼女は、研究していたクラスタリングアルゴリズムが、対照学習(Contrastive Learning)と呼ばれる別の古典的な機械学習アルゴリズムと数学的に類似していることに気づいた。さらに深く掘り下げると、これら二つの異なるアルゴリズムが、同じ根底にある方程式(I-Conの原型)で再構成できることを発見したのである。
Microsoftのシニアエンジニアリングマネージャーであり、本研究のシニア著者でもあるMark Hamilton氏は、「私たちはほとんど偶然にこの統一方程式にたどり着きました。Shadenが二つの手法を結びつけることを発見すると、私たちはこのフレームワークに取り込める新しい手法を夢想し始めました。試したほとんどすべての手法が追加可能でした」と述べている。
この発見を起点として、チームは様々なアルゴリズムをI-Conの枠組みで検証し、その驚異的な一般性を確認していった。そして、その成果を体系的に示す方法として「周期表」のアイデアが生まれたのである。
I-Conが可能にする革新:新アルゴリズム開発と性能向上
I-Conフレームワークの真価は、既存のアルゴリズムを説明するだけでなく、研究者が新しいアルゴリズムを設計するためのツールキットを提供する点にある。
空欄を埋める:新アルゴリズムの創出
周期表の空欄は、新技術開発の指針となる。研究チームは実際に、この周期表の一つの空欄を埋める試みを行った。彼らは、近年の対照学習における「Debiased Contrastive Learning」(後述)の進歩と、クラスタリングの手法を組み合わせることで、全く新しい画像クラスタリングアルゴリズムを開発した。
この新アルゴリズムは、人間によるラベル情報を一切使用せずに画像を分類するタスクにおいて、既存の最先端(State-of-the-Art: SOTA)の手法と比較して、大規模画像データセットImageNet-1Kで8%も高い精度を達成するという驚くべき成果を上げた。これは、I-Conが単なる理論的な整理に留まらず、実用的なイノベーションを生み出す力を持っていることの強力な証拠である。
Debiasing(デバイアス化)技術の一般化
I-Conはまた、特定の手法のために開発された技術を、他の手法に応用する道を開く。その一例がDebiasingである。
Debiased Contrastive Learningは、対照学習において、ネガティブサンプル(似ていないはずのサンプル)の中に、実はポジティブサンプル(似ているサンプル)が偶然含まれてしまう問題(サンプリングバイアス)を補正するために開発された技術である。これにより、特にクラス数が少ない場合に性能が向上することが知られていた。
舞踏会の例えで言えば、Debiasingは「すべてのゲスト間に、ごく少量の友情を加える」ようなものだ。これにより、パーティー全体の雰囲気が良くなるだけでなく、より良い座席配置(クラスタリング)を作りやすくなる。
研究チームは、I-Conフレームワークを用いることで、このDebiasingの考え方を、元々開発された対照学習だけでなく、クラスタリングを含むI-Conの枠組み内のあらゆる手法に原理的に適用できることを示した。実際に、Debiasing技術をクラスタリングに応用することで、その精度を向上させることにも成功している(論文 Figure 5, Table 3参照)。これは、異なるドメインで培われた知見を、I-Conを通じて体系的に移転できる可能性を示唆している。
機械学習の未来への影響
I-Conフレームワークは、急速に拡大し、時に混沌とも見えるAI研究開発分野に、秩序と構造をもたらす可能性を秘めている。
研究開発の加速
I-Conは、研究者に対して以下のような恩恵をもたらす。
- 体系的な理解: 多種多様なアルゴリズムの根底にある共通原理を理解しやすくなる。
- 効率的な開発: 過去のアイデアを再発明することなく、既存の知見を組み合わせたり、改良したりできる。
- 新たな発見の促進: 周期表の「空欄」が示す未踏領域を探求する指針となる。
Hamilton氏は、「情報科学に根差した、たった一つの非常にエレガントな方程式が、機械学習における100年にわたる研究を網羅する豊かなアルゴリズム群を与えてくれることが示されました。これは多くの新たな発見への道を開きます」と期待を述べる。
ヘブライ大学のYair Weiss教授(本研究には不参加)も、「毎年発表される論文の数が無限に見える現代において、既存のアルゴリズムを統一し、接続する論文は非常に重要ですが、極めて稀です。I-Conはそのような統一的アプローチの優れた例であり、他の機械学習ドメインにも同様のアプローチが適用されることを期待させます」とコメントしている。
AI分野全体への示唆
AI技術が社会の隅々に浸透していく中で、I-Conのような基礎的な理解を深める研究は、分野全体の健全な発展に不可欠である。それは、単に直感に頼るだけでなく、目的を持ってイノベーションを進めるための羅針盤となる。
AI分野以外の人々にとっても、これは機械学習のような複雑な分野でさえ、単純なパターンが発見されるのを待っているかもしれない、という示唆を与えてくれる。かつて周期表が化学に秩序をもたらしたように、I-Conは、学習の根底にある構造を理解するための希望に満ちた一歩なのである。知能そのものを解き明かすのではなく、学習とは本質的に「関係性をマッピングする技術」なのかもしれない、という視点を提供してくれる。
そして、この「機械学習の周期表」には、まだ多くの空欄が残されている。それは、未来の研究者たちが新たな発見によって埋めていくべき、広大な可能性の空間を示しているのである。
論文
- OpenReview.net: A Unifying Framework for Representation Learning
参考文献