
人類が人工の知性を生み出して以来、私たちはその驚異的な正答率やデータ処理能力に目を奪われてきた。医師よりも早く腫瘍の兆候を見抜き、膨大な文献を瞬時に読み解くなど、人間の情報処理能力をはるかに超えるタスクを軽々とこなしている。しかし、この輝かしい能力の裏には、科学者たちを長年悩ませてきた暗く深い亀裂が走っている。それは、AIが「自分が間違っているかもしれない」と自らを疑う能力を持たないことだ。
未知の病変、見たことのない道路標識、学習データに含まれていない概念。こうした「知らない情報」に直面したとき、人間であれば「わからない」「確信が持てない」と立ち止まり、周囲の助けを求めることができる。対して、現代の強力なディープラーニングモデルは、しばしば100パーセントの自信に満ちた態度で、完全に誤った判断を下す。この「過信(Overconfidence)」と呼ばれる現象は、大規模言語モデルがもっともらしい嘘をつくハルシネーションの温床であり、医療AIや自動運転といった人命を左右するシステムにおいては、取り返しのつかない判断ミスを引き起こす時限爆弾となっている。
なぜ人工知能はこれほどまでに傲慢な振る舞いを見せるのか。長年、研究者たちは出力された結果を外部から強制的に補正したり、不確実性を測るための監視システムを別途付け足したりして、この厄介な性質をなだめようと試みてきた。しかし、韓国科学技術院(KAIST)のセボム・ペク(Se-Bum Paik)特別教授率いる研究チームは、全く異なる視点からこの謎を解き明かした。AIの過信は、学習データの量が足りないから起きるのではない。ディープラーニングを構築する際の「最初の産声」そのものに欠陥があったのだ。
彼らが『Nature Machine Intelligence』誌に発表したブレイクスルーは、生命の発生プロセス、すなわち「胎児の脳」で起きている静かな現象にインスピレーションを得たものである。生データを与える前に「純粋なノイズ」をAIに浴びせるという極めてシンプルなアプローチが、AIに「無知の知」をもたらすメカニズムを紐解いていこう。
知識の蜃気楼。「ランダム初期化」が仕掛ける構造的な罠
問題の核心に迫るためには、現代のニューラルネットワークがどのように生まれ、学習を開始するのかを構造的に理解する必要がある。
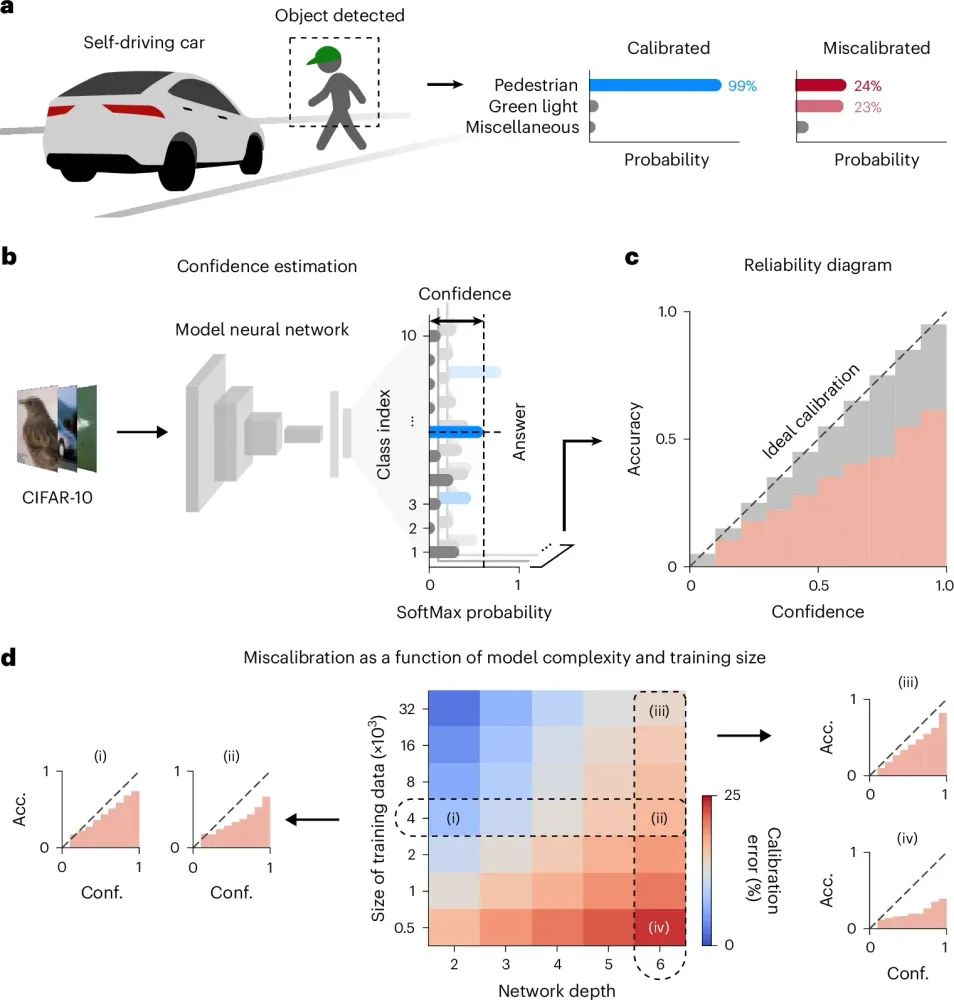
何も学習していない真っ新なAIモデルを用意したとき、その内部の結合パラメータ(重み)はすべてゼロになっているわけではない。もしすべてがゼロであれば、ネットワーク全体が均質になりすぎてしまい、誤差をうまく逆伝播させて新しい知識を吸収することができなくなる。そのため、深層学習の歴史においては、Xavier初期化やHe初期化に代表される「ランダム初期化(Random Initialization)」と呼ばれる手法が業界標準として確立されてきた。これは、各ニューロンのつながりに特定の分散を持ったランダムな初期値をあらかじめ与えておくアプローチである。これにより、ネットワーク内に適度な乱れが生じ、入力データから特徴を効率的に掴み取ることが可能になる。
しかし、KAISTの研究チームは、この長年の常識にメスを入れた。ランダムに初期化された直後、まだ何も意味のあるデータを学習していない状態のネットワークに対して、適当なノイズ画像を入力してみたのである。常識的に考えれば、何も学んでいないAIの予測確信度は「チャンスレベル(たとえば10個の選択肢があるなら、すべて約10%ずつの確率)」になるはずだ。
結果は衝撃的なものだった。全くの無知であるはずのネットワークは、ランダムなノイズに対して特定の答えを「極めて高い確信度」で出力したのである。
この現象の裏には、深層学習特有の数学的な構造が潜んでいる。ネットワークの最終段階では、数多くのニューロンからの信号を確率に変換するために「ソフトマックス関数(SoftMax function)」という計算式が使われる。この関数は、少しでも大きな信号(ロジット)があると、それを極端に強調して100%に近い値に押し上げてしまう性質、すなわち飽和状態を持っている。音量調整の壊れたメガホンを想像してほしい。かすかな風の音であっても、スピーカーからは耳を劈くような大音量として鳴り響く。ランダム初期化によって生じたネットワーク内の微小な偏りが、このメガホンを通ることで「絶対の自信」に変換されてしまっていたのだ。
この初期状態の過信は、その後の学習プロセスを通じて解消されることはない。間違った自己肯定感を持ったまま成長してしまうため、見たこともない未知のデータ(OOD: Out-of-Distribution)に対しても「知っている」と思い込み、堂々と間違った答えを返すようになってしまう。データセットのサイズが4,000件程度と小さく、ネットワークの層が深い(例えば6層以上)場合、この過信によるキャリブレーションエラーは顕著に増大する。
胎児の夢が教えるもの。ノイズが育むメタ認知の萌芽
この構造的な欠陥をどう修正するか。ここで研究チームは、人工知能の設計図から離れ、生物の脳の発達プロセスへと目を向けた。
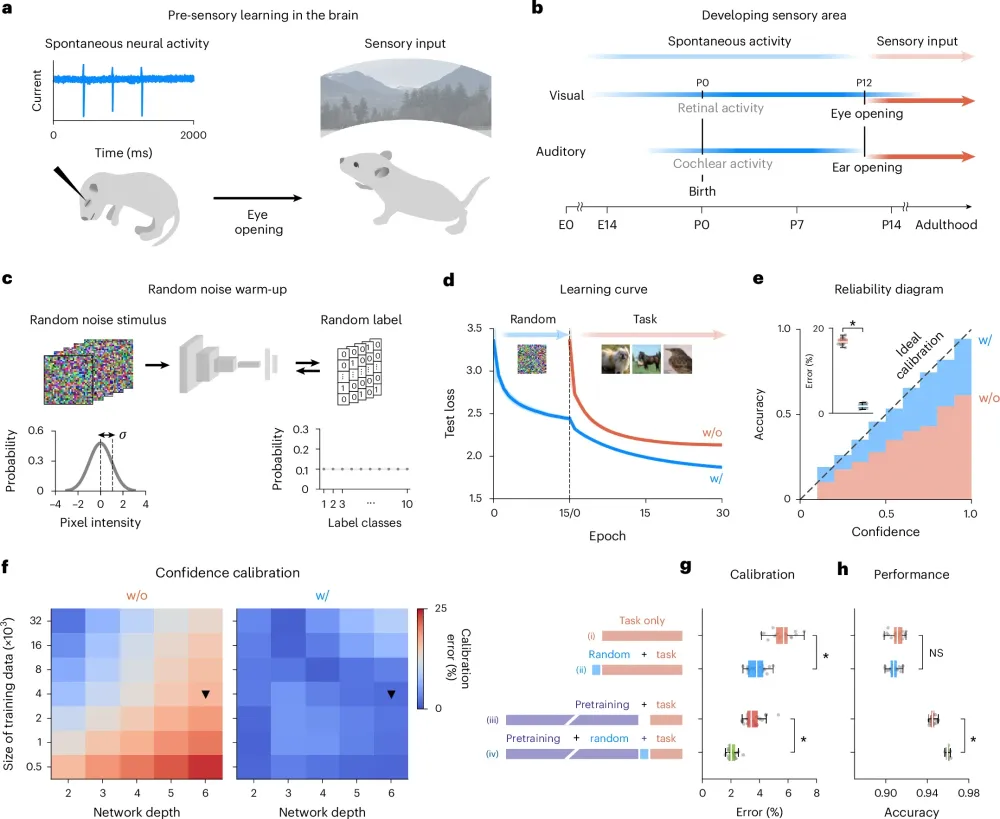
人間をはじめとする生物の脳は、誕生して外界の光や音を浴びる前から、すでに神経回路の配線を始めている。胎児の網膜や聴覚皮質では「自発的神経活動(spontaneous neural activity)」と呼ばれる現象が起きていることが長年の脳科学研究で明らかになっている。目を開けて世界を見る前から、網膜の細胞たちは外部からの刺激なしにランダムな電気信号(網膜波)を発火させ、脳の視覚野へと送り込んでいるのだ。これは言わば、脳が自ら作り出したノイズを用いたリハーサルである。
なぜ生物は、外界に触れる前に多大なエネルギーを使って無意味なノイズを処理しているのか。KAISTのチームは、この胎生期の「ノイズ処理」こそが、脳の感覚器のベースラインを整え、何が未知であるかを定義するための準備運動を担っているのではないかと仮説を立てた。
彼らはこの生命のメカニズムをAIの学習アルゴリズムに翻訳し、「ランダムノイズによるウォームアップ学習(warm-up training with random noise)」を考案した。
手法は驚くほどシンプルだ。実際の画像やテキストデータをAIに学ばせる前に、短期間だけ「完全なノイズデータ(砂嵐のようなガウス分布画像)」をネットワークに入力する。そして、そのノイズに対して「でたらめな正解ラベル」を割り当て、学習させるのである。 犬の画像を見て「犬」と答える訓練をする前に、意味のない砂嵐の画像を見て「これは分類不能なでたらめである」と認識する訓練を挟むのだ。このウォームアップを経ることで、暴走していたAIのロジットは沈静化し、ソフトマックス関数のメガホン効果が打ち消される。AIはここで初めて「自分はまだ何も知らない」という、謙虚な確率の平原に立つことができる。
既存の事後処理アルゴリズムを凌駕する「純粋な土壌改良」
このノイズウォームアップがもたらすブレイクスルーは、既存のキャリブレーション技術と定量的に比較することで、その真価がより明確になる。
これまでAIの過信を抑えるためには、「温度スケーリング(Temperature Scaling)」や「ODIN(Out-of-DIstribution detector for Neural networks)」、あるいは「エネルギースコア(Energy Score)」といった事後的な補正手法が主流だった。これらは、学習が終わった後のモデルに対して、別の「検証用データセット(ホールドアウトデータ)」を用意し、出力される確率分布を数学的に押し潰したり引き伸ばしたりして表面を取り繕うアプローチである。
しかし、KAISTのノイズウォームアップはこれらの手法とは根本的に一線を画す。事後処理ではなく事前準備であり、高価で作成に手間の掛かるホールドアウトデータは一切不要だ。純粋なガウス分布に基づく数学的なノイズを入力するだけで完了する。
| 比較項目 | 従来のアプローチ(温度スケーリング・ODIN等) | 本研究のノイズウォームアップ学習 |
|---|---|---|
| 介入のタイミング | 通常の学習がすべて完了した後、または別系統での処理 | 実データを学習する前の「初期化」直後 |
| 必要なデータ | 調整用の検証データ(ホールドアウトデータ)が別途必要 | 実データは一切不要。数学的なランダムノイズのみ |
| 計算コスト | 補助ネットワークの稼働や追加のハイパーパラメータ探索が発生 | わずかなノイズ学習エポックのみで完了し、極めて軽量 |
| 問題の解決アプローチ | 出力された過信スコアを上から押さえつけて表面を整える | 出力前の内部変数の暴走を防ぎ、根本的な土壌を改良する |
さらに注目すべきは、この手法が「生物学的な妥当性」を持つ学習アルゴリズムにおいても絶大な効果を発揮した点である。現在のAIは誤差逆伝播法(バックプロパゲーション)を用いて効率的に学習するが、人間の実際の脳はそのような精密な逆計算を行っていない。より生物の脳に近いとされる「フィードバックアライメント(Feedback Alignment)」というアルゴリズムでネットワークを訓練した場合、初期状態の過信問題はさらに悪化する傾向にあったが、ノイズウォームアップを導入することで見事にキャリブレーションが修復されることが論文の補足データで詳細に示されている。
アーキテクチャへの普遍性も極めて高い。古典的な多層パーセプトロンだけでなく、画像認識の業界標準であるResNetやDenseNet、そして次世代の覇権を握るVision Transformer(ViT)に至るまで、モデルの規模や種類を問わず一貫して過信を抑制する効果が確認された。
未知の領域を測るコンパス。OOD検知への応用
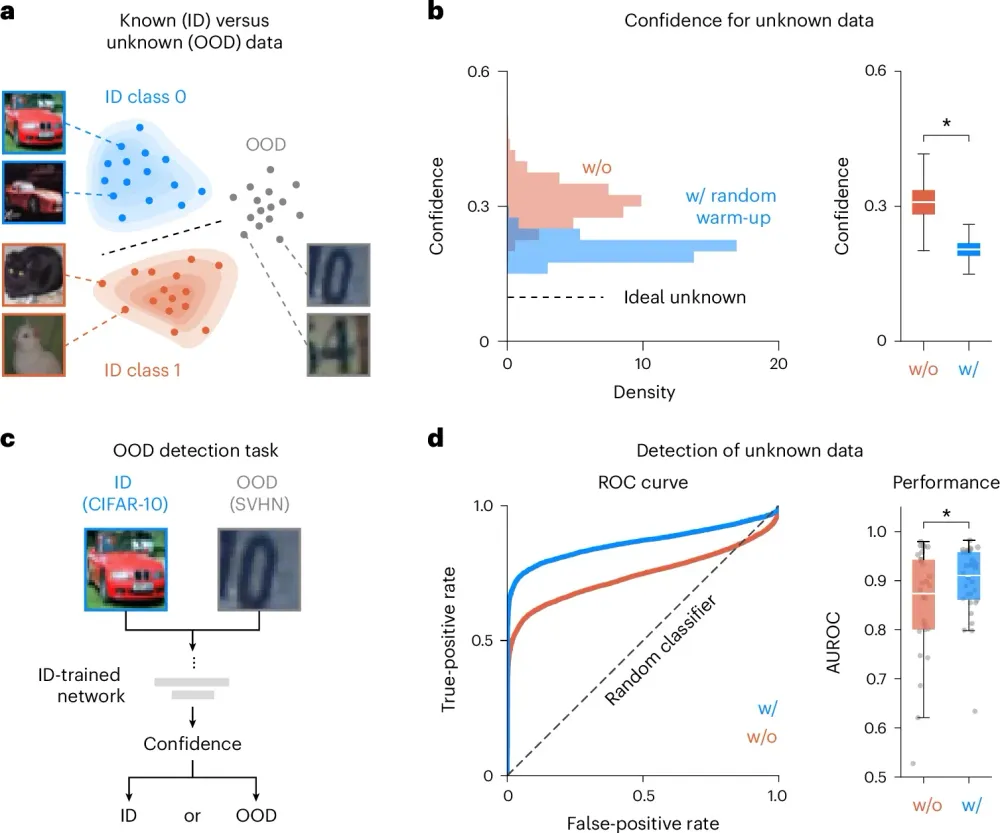
土壌が改良され、精度と確信度が美しく一致したAIは、未知のデータ(OOD)に対してどのような反応を示すのだろうか。
研究チームは、10種類の動物や乗り物の画像(CIFAR-10)で訓練したモデルに対し、見たこともない街中の番地の数字画像(SVHNデータセット)を入力し、その反応を観察した。 従来のAIモデルは、数字の画像を見せられているにもかかわらず、「これは99%の確率で犬である」といった過信に満ちた判定を下していた。しかし、ノイズウォームアップを経たモデルは、未知の画像に対して確信度を急激に低下させ、「よくわからない(チャンスレベルに近い確率)」という極めて妥当な反応を示したのである。
この性質により、AIが未知のデータを異常値として検知する能力(OOD検知能力)の精度指標であるAUROC(受信者動作特性曲線の曲線下面積)は大幅に向上した。近年注目を集めている「コンフォーマル予測(Conformal Prediction)」の枠組みにおいても成果を上げている。コンフォーマル予測とは、モデルが単一の答えを出すのではなく、「正解が95%の確率で含まれる選択肢のセット(予測区間)」を出力する手法だが、ノイズウォームアップを適用したモデルは、このセットのサイズを不必要に広げることなく、高い精度で正解を含有できることが示された。
残された課題と社会への波紋
この技術が実社会にもたらすインパクトは計り知れない。 自動運転車が、視界を遮る吹雪や見たことのない形状の落下物に遭遇した際、強引に「安全な道路」と誤認識して突っ込むのではなく、「システムには判断できない」と即座に人間に制御を明け渡すことができるようになる。医療現場においては、未発見の疾患やノイズの多いレントゲン画像に対して、AIが「確信度が低い」とアラートを出し、医師の慎重な介入を促すセーフティネットの役割を果たす。
また、ノイズウォームアップの驚くべき点は、その適応性の高さと低コストである。論文によれば、ImageNetの1億2000万枚の大規模データで事前学習を行うようなResNet-18モデルにおいても、その直前にわずか25万枚分のノイズ画像を見せるだけで、過信を抑制する強固な基盤が形成されることが確認された。この計算コストは全体の学習プロセスから見れば誤差の範囲に等しい。
目前に迫る課題も存在する。 現在の検証は、主に画像認識領域における相対的に小規模なタスクとネットワークアーキテクチャで行われている。世界を席巻している数千億パラメータ規模の大規模言語モデル(LLMs)への適用は、未検証の領域である。LLMのゼロからの学習には数百万ドルの計算コストがかかるため、学術機関のラボレベルでこの初期化プロセスの全容を系統的にテストすることは容易ではない。自然言語という極めて複雑な離散空間において、ランダムな文字トークンを「ノイズ」として与えることで同等の効果が得られるのか、今後の産学連携による大規模な実証実験が待たれる。
AIはこれまで、いかに正解を多く出力するかという覇権を激しく競い合ってきた。しかし、知性の真髄とは、すべてを知っていることではない。ソクラテスが説いたように、自らの限界を知り、不確実性という霧の中で立ち止まる勇気を持つことだ。
ノイズという一見無意味な混沌が、AIに「私は確信がない」とつぶやく知性を授けた。胎児の脳が暗闇の中で見る夢は、暴走するテクノロジーの手綱を握り直し、より安全で信頼できる人工知能との共生へと私たちを導く確かなコンパスになる。