
AIエージェントに「養蜂を始めるために必要な知識」を尋ねてみるがいい。言語モデルは巣箱の温度管理からミツバチの生態リズムまで、流暢かつ正確なアドバイスを即座に提示する。この時点では、AIは極めて優秀なアシスタントに見える。しかし、問いの解像度をビジネスの実戦レベルへと一段階引き上げ、「昨年の契約書の中でA社に関する条項を探し、それが現在のミツバチコロニーの供給トラブルとどう関連しているか」と尋ねた瞬間、事態は一変する。
AIはもっともらしい日付や実在しない担当者名を交え、完全に虚構のストーリーを自信満々に語り始める。業界で「ハルシネーション(幻覚)」と呼ばれるこの現象こそが、企業が自社の機密データや膨大な社内文書に生成AIを解き放つことを躊躇させる最大の障壁である。
これまで、この問題を解決するためのアプローチは、より巨大で賢いパラメータを持つ言語モデル(LLM)を開発するか、プロンプト・エンジニアリングの魔術に頼ることに集中してきた。しかし、韓国科学技術院(KAIST)のMin-Soo Kim教授率いる研究チームと、同大学発スタートアップGraphAI Co. Ltd.が導き出した結論は、全く異なる方向を指し示している。彼らは、AIが嘘をつく根本原因は「脳(LLM)」の計算能力にあるのではなく、事実を引き出すための「記憶の棚(データベース)」の構造的欠陥にあると断破した。
彼らがACM SIGMOD 2026で発表した次世代データベース技術「AkasicDB」と、それを基盤とする新たな検索拡張生成手法「Omni RAG」は、意味・関係性・事実という3つの異なる次元のデータを単一のエンジンの中で完全に同期させる。本稿では、AIの記憶処理アーキテクチャにおけるこのパラダイムシフトの全貌と、それがエンタープライズIT市場に突きつける構造的な変革を解き明かす。
意味、関係、事実。分断された検索パイプラインが生み出す「知の空白」
現在の企業向けAIエージェントの多くは、RAG(Retrieval-Augmented Generation:検索拡張生成)と呼ばれる技術の上に構築されている。ユーザーの質問を数値の配列(ベクトル)に変換し、高次元の数学的空間内で距離が近い文書を探し出し、それを文脈としてLLMに渡すという仕組みである。
このアプローチは、非構造化テキストの大海から「意味的に似ているもの」を掬い上げる能力には長けている。だが、現実の企業データは単なるテキストの羅列という単純なものではない。そこには「特定のプロジェクトにおける人物や組織の相関図(グラフ構造)」や、「日付、金額、カテゴリといった厳密な構造化データ(リレーショナル構造)」が複雑に絡み合っている。
従来のシステムで先述の「昨年の契約とA社の関係、そして供給トラブル」について調べようとした場合、内部では極めて非効率で脆弱なバケツリレーが行われる。まず、ベクトルデータベースが「意味的」に合致する条項を探り当てる。次に、グラフデータベースが「企業と人物の繋がり」をマッピングする。そこへリレーショナルデータベースが「昨年の契約」という条件でフィルターをかける。
これらを別々の専用システムとして稼働させ、最終的にアプリケーション層で結果を縫い合わせようとするアプローチ(Out-of-DB統合)を採用した場合、致命的な問題が発生する。各データベースは、後の工程で最終的にどのデータが必要になるか分からないため、安全を期して必要以上に大量の中間データを吐き出してしまう。あるいは、PostgreSQLのような一般的なリレーショナルデータベースに拡張機能(pgvectorやApache AGEなど)を継ぎ接ぎして無理やり同居させる手法(In-DB非ネイティブ統合)もある。この場合、全体を統括するクエリプランナはグラフやベクトルの空間的な特性を深く理解しておらず、すべての処理をリレーショナル処理の枠組みに強引に押し込めてしまう。
結果として検索プロセスに膨大な時間を浪費し、さらに条件のすり合わせの過程で真に必要な事実関係までもがこぼれ落ちてしまうのだ。検索システムから不完全な断片しか渡されなかったLLMは、その卓越した言語生成能力によって「空白部分」を滑らかな文章で推測し、論理の飛躍を埋め合わせてしまう。これが、AIがもっともらしい嘘をつくメカニズムの正体である。
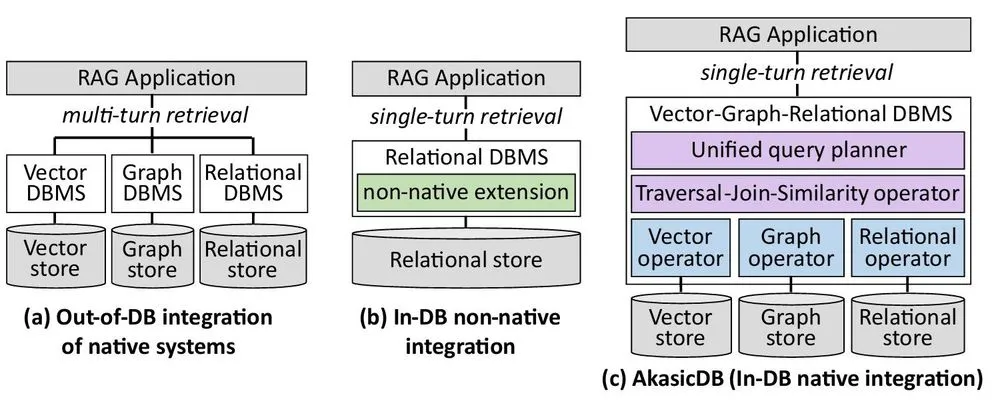
3つの脳葉を繋ぐ単一の神経網。AkasicDBが実装したネイティブ統合の深層
KAISTチームが開発した「AkasicDB」は、この分断されたインフラ構造を根底から作り直す。彼らはまず、グラフデータとリレーショナルデータを単一のエンジンで処理するために以前開発した「Chimera」というデュアルストア・アーキテクチャを土台に据えた。そこに、HNSW、IVF、Vamanaといった高度な近似最近傍探索(ANN)インデックスをサポートする専用のベクトルストアをネイティブな形で組み込み、堅牢なトリプルストア設計を完成させた。
AkasicDBの核心は、これら3つの異なるデータモデルをまたぐ複雑な検索を、単一のSQL/GQL(Graph Query Language)クエリとして表現し、一つの「統一クエリプランナ」の下で実行できる点にある。
内部では、Traversal-Join-Similarity演算子と呼ばれる革新的なメカニズムが稼働している。これを日常的なシチュエーションに翻訳するならば、言語学者(ベクトル)、探偵(グラフ)、会計士(リレーショナル)という3人の専門家が、それぞれ独立して調査を行い、後で手紙を交換して意見をすり合わせる(従来の手法)のではなく、彼らの能力をすべて併せ持つ一人の超人的な知性が、すべての思考プロセスを同時に、かつ矛盾なく進行させるような状態である。
この統合により、システムは検索の初期段階で「グラフの繋がり(トポロジー)」と「日付やカテゴリの条件(属性)」を加味しながら、探索すべきベクトルの範囲を動的に絞り込む。余分な中間データを生成する無駄を省き、ネットワークを通じて膨大なデータを移動させるレイテンシを消し去る。極限まで研ぎ澄まされた単一の実行計画が、LLMへと渡すコンテキストの純度を飛躍的に高めるのである。
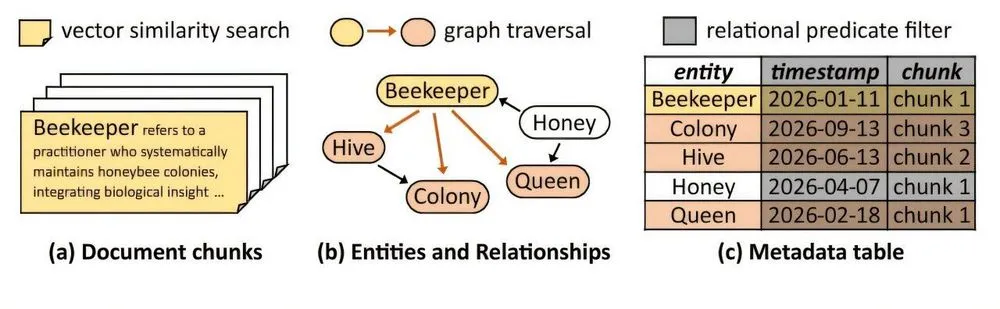
圧倒的なパフォーマンスを裏付ける実証データと「Omni RAG」の破壊力
AkasicDBの上に構築された新しいRAG手法「Omni RAG」のパフォーマンスは、従来のアーキテクチャがいかに深刻なボトルネックを抱えていたかを如実に示している。
UltraDomainデータセット(農業、コンピュータサイエンス、法律、およびそれらの混在領域からなる計数百万トークン規模のデータ)を用いた実験において、その効果は定量的に証明された。既存のシステム(pgvectorとAGEを組み合わせたPostgreSQLなど)では各データベース間の調整とデータ転送に手間取り、回答を導き出すまでに最大で21.3秒という長い時間を要していた複雑な検索クエリが、AkasicDB上ではわずか1秒未満で処理された。これは20倍以上という驚異的な高速化である。
さらに注視すべきは、回答の品質の劇的な向上である。構造化条件やエンティティ間の関係性を正確に把握した上でコンテキストが抽出されるため、LLMが推測で物語を補う余地が徹底的に排除された。その結果、従来のベクトル検索のみに依存するRAGと比較して、回答の精度は最大で78%向上した。
以下の表は、異なるアーキテクチャ間でのRAGの性能を比較したものである。
| アーキテクチャ | システム構成例 | 複雑クエリ処理時間 (ミリ秒) | 精度向上に対する優位性 | 構造的特徴 |
|---|---|---|---|---|
| Out-of-DB統合 | Neo4j + Milvus | 3,001 ~ 7,099 | 限定的 | 複数の独立システム。データ転送コストと過剰な中間データ生成がネック。 |
| In-DB非ネイティブ | PostgreSQL (pgvector + AGE) | 4,728 ~ 21,278 | 限定的 | 一つのDB上に拡張機能を付加。プランナの最適化が不十分で実行効率が著しく低い。 |
| In-DBネイティブ | AkasicDB (Omni RAG) | 583 ~ 942 | 最大78%向上 | 3つの機能を最下層で統合。単一プランナによる無駄のない一括実行。 |
とりわけ興味深いのは、データソースが複雑に絡み合い、複数の領域を横断するような質問(表の基盤となったMixデータセット環境)において、Omni RAGがベクトル単体のアプローチに対して28パーセントポイントという最大の精度差を叩き出している事実である。直面する問いの構造が入り組んでいればいるほど、ネイティブ統合アプローチの真価が発揮される。
仮想シミュレーション:法務・サプライチェーンにおける衝撃
この技術が実社会にもたらすインパクトを想像するために、グローバル製造業の調達部門における架空のユースケースを想定してみよう。
担当者がAIに「過去3年間に締結されたアジア太平洋地域の部品サプライヤーとの契約のうち、自然災害時の免責条項が含まれており、かつ現在稼働中のプロジェクトXに部品を供給している企業のリストとリスク評価を抽出せよ」と命じたとする。
従来のRAGシステムであれば、「自然災害」「免責」といったキーワードの類似性に基づく契約書を引っ張り出し、何となくプロジェクトXに関わっていそうな企業名を羅列するだろう。しかし、その契約がすでに失効しているものか、あるいは対象企業が孫請けとして間接的に関わっているだけなのかを正確に識別することは困難である。
対してOmni RAGを搭載したAkasicDBは、まずリレーショナルデータから「過去3年間」「アジア太平洋」というハードファクトによる強固なフィルターをかける。次にグラフデータから「プロジェクトXと直接的・間接的な供給関係にある企業ネットワーク」のトポロジーを辿る。その絞り込まれた厳密な枠組みの中で、ベクトルデータを用いて「自然災害時の免責条項」に意味的に合致する契約文面をピンポイントで抽出する。このプロセス全体が数ミリ秒のうちに完結し、根拠のある揺るぎない事実のみがAIのコンテキストとして提示される。企業法務やリスクマネジメントにおいて、この「絶対的な事実の担保」がもたらす価値は計り知れない。
データインフラ覇権を巡る次なる戦場とマクロな業界文脈
Min-Soo Kim教授は「AkasicDBはAIエージェント時代のコアデータインフラである」と明言している。彼らがターゲットとしているのは、防衛、製造、金融、法務といった「もっともらしい嘘」が致命的な事業リスクや法的責任に直結するハイステークスな領域である。
しかし、このパラダイムが市場を席巻するまでには、巨大なデータベースベンダーがひしめく業界の力学という壁を乗り越えなければならない。現在、エンタープライズ市場ではOracle、Amazon Web Services (AWS)、Microsoft Azureなどが強固なエコシステムを築き上げている。また、グラフデータベース領域ではNeo4jが、ベクトルデータベース領域ではPineconeやMilvusがそれぞれ専門領域での覇権を握っている。
既存のシステムから、このような新しいトリプルストア構造へとデータを移行し、基幹インフラを再構築することは、企業にとって莫大なコストとリスクを伴う大手術である。さらに、今回の検証はテラバイト級のメモリを搭載したオンプレミスの強力なサーバー環境下でのデモンストレーションである。パブリッククラウド上の分散システムとしてスケールアウトさせた際、この統合エンジンのパフォーマンスがどのように推移するかは、実用化に向けた重要な検証課題として残されている。
とはいえ、AkasicDBの登場が発するメッセージは極めて強烈である。世界のAI開発競争は、モデルのパラメータ数を増大させる「脳の巨大化」から、情報検索のアーキテクチャを根本から設計し直す「記憶の統合」へとシフトしつつある。私たちが長年直面してきたハルシネーションという絶壁は、無機質な知能の限界によるものではない。より整理され、高度に結合されたデータインフラによって、それは確実に解体されようとしている。