
AMDは、Radeon RX 9000シリーズ向けに全面的に刷新したRDNA 4 GPUアーキテクチャを発表した。新しいコンピュートユニット、強化されたレイトレーシングコア、AI機能の向上が特徴で、ゲーマー向けに最適化されている。
RDNA 4アーキテクチャ:ゲーマーのために新設計

AMDのRDNA 4アーキテクチャは、前世代のRDNA 3およびRDNA 3.5の発表以来、大きな期待を集めてきた。RDNA 4アーキテクチャは、ウルトラエンスージアスト向けのSKUには採用されないものの、ゲーマーを主なターゲットとして設計されており、根本的な見直しによって、特にハイエンドゲーミングにおける性能向上を目指している。
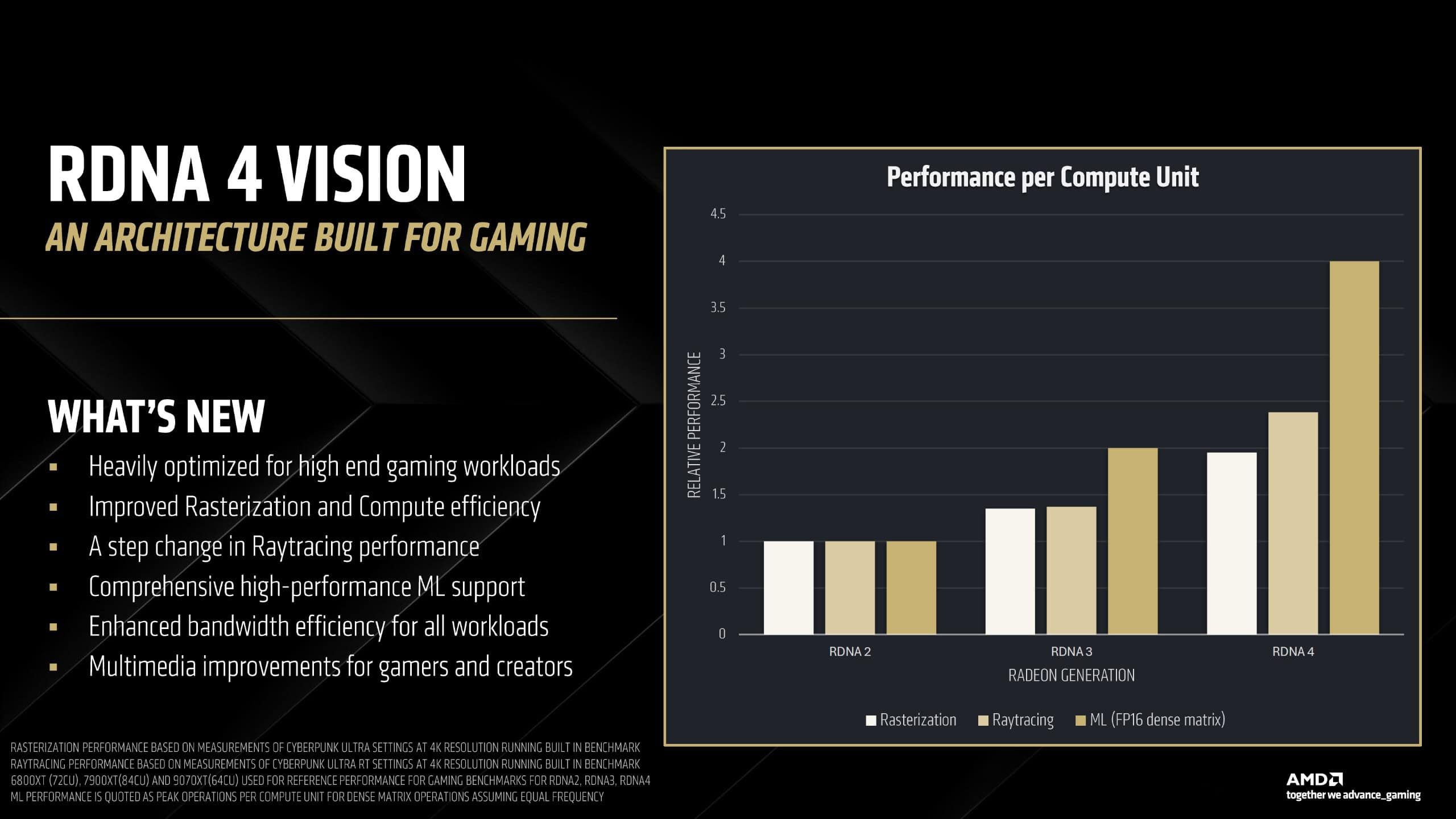
最初に、AMDはRDNA 4に以下の新しい変更をもたらしている:
- ハイエンドゲーミングワークロードに最適化
- ラスタライズとコンピュート効率の向上
- レイトレーシングパフォーマンスの大幅な改善
- 包括的な高性能MLサポート
- すべてのワークロードにおける帯域幅効率の向上
- ゲーマーおよびクリエイター向けのマルチメディア改善
RDNA 2と比較して、RDNA 4 GPUは、コンピュートユニットあたり、ラスタライズで約2倍、レイトレーシングで約2.5倍、ML(FP16 dense matrix)ワークロードで3.5倍の性能向上を実現しているとのことだ。
コンピュートユニットの強化

RDNA 4の新しいコンピュートユニットには、Dual SIMD32ベクトルユニット(並列演算ユニット)と強化された行列演算が含まれている。これらは2倍の16ビットおよび4倍の8ビット/4ビット密行列レート、4:2構造化スパーシティ(計算の効率を高める技術、+2倍のレート)、新しい8ビットフロートデータタイプ、トランスポーズを伴う行列ロードを提供する。
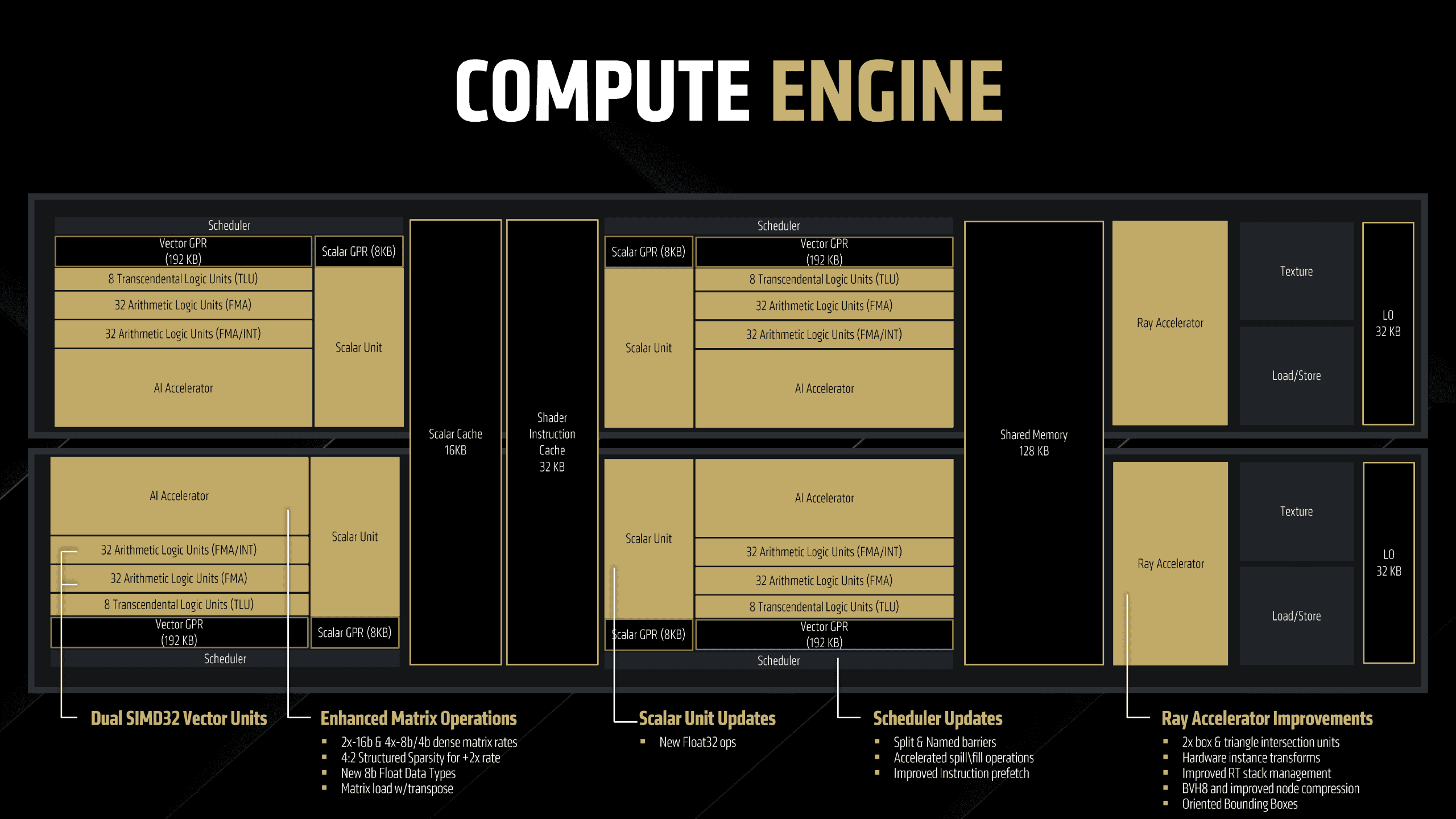
RDNA 4シェーダー(描画処理を行うプログラム)には、レジスタを動的に割り当てるという重要な改善が施されている。必要に応じてプールからレジスタを要求し、作業が完了するとプールに解放することが可能になった。これにより、メモリレイテンシ(応答時間)の処理が向上し、共有コアの効率が大幅に向上している。
スカラーユニット側では、新しいFloat32操作が追加され、スケジューリングの更新にはスプリットおよび名前付きバリア、加速されたスピル/フィル操作、改善された命令プリフェッチが含まれている。
レイトレーシングの進化

RDNA 4で最も注目すべき改善点の一つがレイトレーシング性能の向上だ。第3世代レイトレーシングユニットは、レイ交差率(光線と物体の交差を計算する速度)を2倍に向上させ、改善されたBVH圧縮、加速されたレイトラバーサルとシェーディング、定向バウンディングボックスを提供している。
各レイアクセラレータには、ボックスとトライアングルの交差ユニットが2倍、ハードウェアインスタンス変換、改善されたRTスタック管理、BVH8および改善されたノード圧縮、定向バウンディングボックスが含まれている。
これらの新しいレイトレーシングアップグレードにより、BVH(Bounding Volume Hierarchy、3D空間を効率的に検索するためのデータ構造)のメモリ要件がRDNA 3と比較して60%未満に削減されている。また、ボックスごとに回転をエンコードすることでトラバーサルコスト(探索コスト)を削減する新しいソリューションも実装されている。これにより、トラバーサル性能が10%向上している。
これらの変更の結果、RDNA 4 CUは同じクロック速度と帯域幅で、RDNA 3と比較してレイのトラバーサル性能が2倍になっている。
AI処理能力の向上

AIワークロード向けに、AMDは第3世代行列加速エンジンを導入した。これらのエンジンは改善されたテンソル密度率、新しい8ビットフロートデータタイプ、構造化スパーシティサポート、ML基盤の超解像を提供している。
RDNA 3のCUは512のFP16演算(16ビット浮動小数点演算)をサイクルごとに処理できたが、スパーシティサポート(計算の効率を高める技術)はなかった。RDNA 4では、密な演算のためのFP16スループットをベースラインで2倍、スパース演算でさらに2倍、FP8ワークロードでさらに2倍にしている。これにより、RDNA 3のFP16と比較して、RDNA 4のFP8では最大8倍高いAIスループットを実現している。
実世界の例として、AMDはStable Diffusion XL(AI画像生成モデル)を使用して、64 CUを持つRX 9070 XTと84 CUを持つRX 7900 XTを比較した。古いGPUはコンピュートユニットで31%のアドバンテージを持っていたが、9070 XTは2倍近いパフォーマンスを達成した。
メモリとキャッシュシステム
RDNA 4ではメモリとキャッシュの階層も再設計されている。第3世代のInfinity Cacheの容量は64MBのままだが、モノリシックチップの一部として、より低いレイテンシとスループットを実現している可能性が高い。
メモリサポートはRDNA 3から変更されていない。NVIDIAが発表されたBlackwell RTX 50シリーズのすべてのソリューションをGDDR7メモリに移行する一方、AMDは最大20Gbpsのクロックを持つGDDR6メモリを引き続き使用している。
コマンドプロセッサも改良され、拡張されたパケットアクセラレータを特徴としている。キャッシュは最大64MBの第3世代Infinity Cache、8MBのL2キャッシュ、2MBの集約CUキャッシュでよりバランスが取れている。
メディアエンジン

メディアエンジンとディスプレイエンジンについてだが、まず、新しいメディアエンジンは、以下を通じて強化されたゲームストリーミングと録画を提供する:
- H.264低遅延エンコード品質が25%向上
- HEVCエンコード品質が11%向上
- BフレームによるAV1エンコード効率の向上
- 720pで最大30%のエンコードパフォーマンス向上
- FFMPEG、OBS、Handbrakeに最適化
- VCN低電力ビデオ再生(AV1およびVP9で50%のパフォーマンス向上)
ディスプレイエクスペリエンスも向上しており、ほとんどの2ディスプレイ構成でアイドル電力を低減する強化されたFreeSync電力最適化モード、ビデオ再生のためにビデオフレームのスケジューリングをGPUにオフロードしてCPU電力を節約するハードウェアフリップキューサポート、高品質の画像とシーンを提供し、単一のトグルですべてのAPIで機能するRadeon Image Sharpening 2が提供される。
RDNA 4ブロックダイアグラム (Navi 48 GPU)
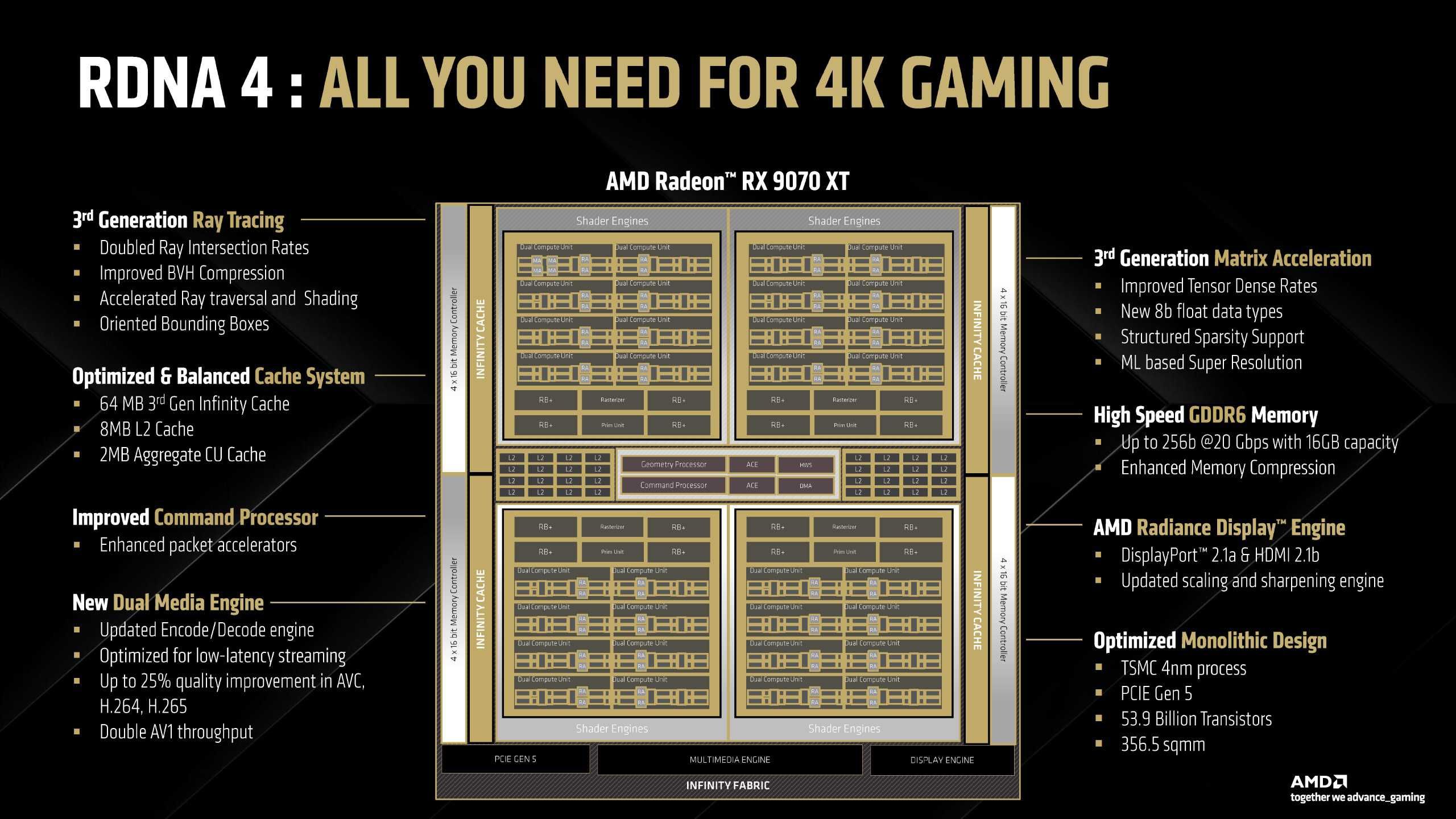
RDNA 4 GPUはTSMC 4nmプロセスノードで製造され、最大539億個のトランジスタを搭載し、SKUのサイズは356.5mm2である。チップはPCIe Gen5にも完全対応。
Navi 48 GPU(Radeon RX 9070 XT)は、4つのシェーダーエンジンで構成され、それぞれが複数の「デュアルコンピュートユニット」を搭載している(WGPではない)。各デュアルコンピュートユニットは2つのコンピュートユニットを備えており、シェーダーエンジンあたり合計8つのDCUまたは16のCUがある。チップ全体では、合計32個のDCUまたは64個のCUとなり、合計4096個のストリームプロセッサまたはシェーダーユニットとなる。
各DCUには2つのレイアクセラレータエンジンがあり、シェーダーエンジンあたり合計16個のRA、全体で64個のRAとなる。また、各DCUには4つのマトリックスアクセラレーションエンジンが搭載されており、シェーダーエンジンあたり合計32個のMA、全体で128個のMAとなる。各シェーダーエンジンには、4つのRB+ブロック、ラスタライザーエンジン、プリムユニットブロックも搭載されている。チップの外縁には、4つのセクションの第3世代Infinity Cacheと4つの4×16ビットメモリコントローラーがある。
L2キャッシュはGPUの中央にあり、2つのジオメトリプロセッサ、2つのACEユニット、それぞれ1つずつのHWSとDMAも含まれている。チップはInfinity Fabricを使用して接続されている。
AMDのパストレーシングの未来
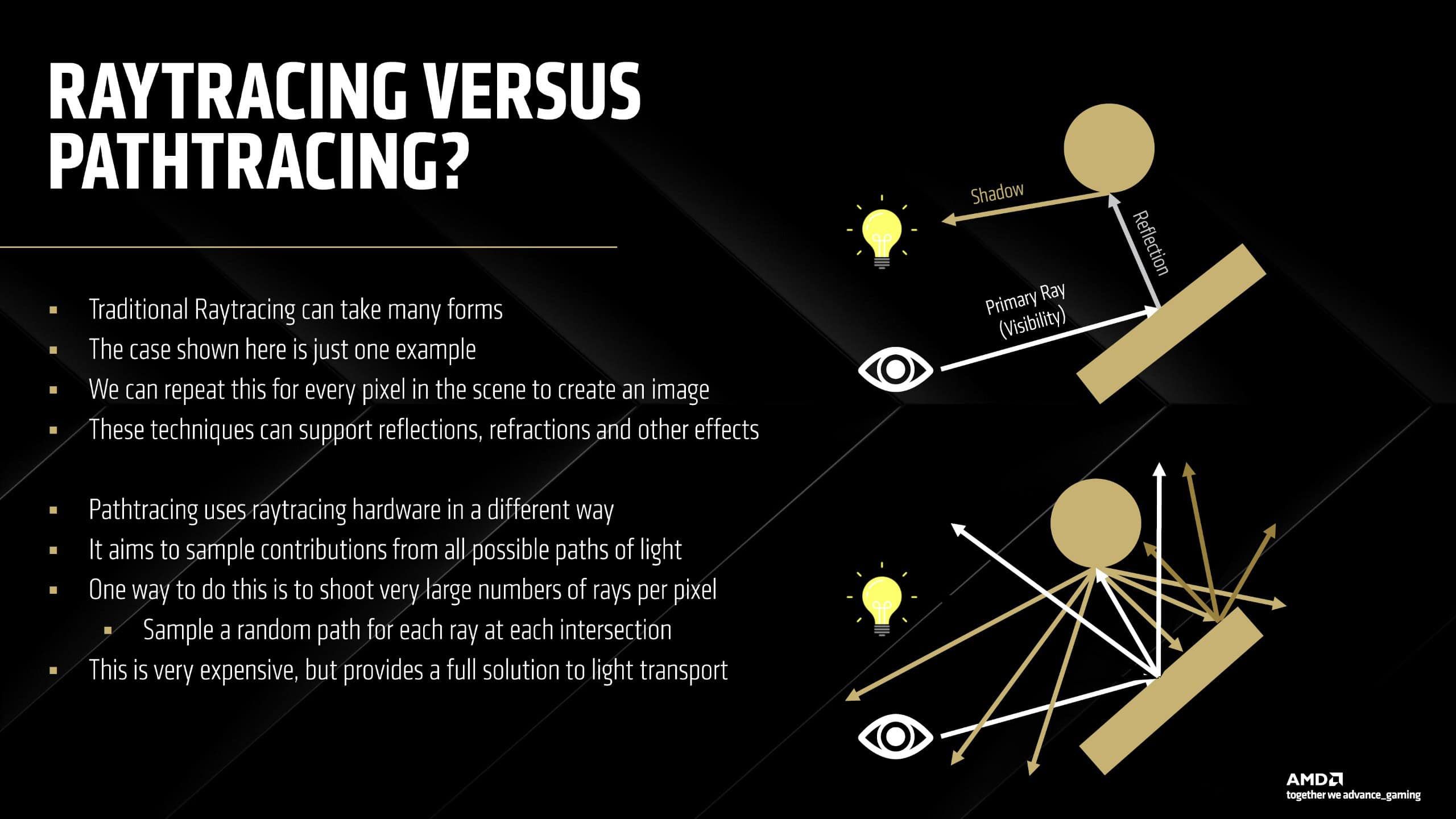
レイトレーシングは、PCゲームの世界では時代遅れの用語と見なされることが多い。確かに、シーンをよりリアルに見せるために光線を追跡する1つの形式であり、コンソール分野でようやく注目を集め始めたばかりだが、競合他社はパストレーシングと呼ばれる別のタイプのレイトレーサーを使用していると見られている。レイトレーシングが単一のプライマリレイを使用して反射、影、屈折をソースにキャストするのに対し、パストレーシングは光のすべての可能なパスを使用する、より高価な技術だ。
NVIDIAのパストレーシングの研究成果は、『Cyberpunk 2077』や『Alan Wake II』などのゲームで見ることができ、これらは最もグラフィック要求の高いタイトルの一部と見なされており、非常に美しい。パストレーシングの使用は、アップスケーリングやフレーム生成などの新しい技術によって可能になったが、NVIDIAはレイ再構築と呼ばれる全く新しい技術にも投資した。これは、エンジン内のデノイザーを削除し、AI/MLを使用して画像を再評価および再構築することにより、パストレーシングをより効率的に実現するのに役立つ。
AMDも、RDNA 4のパストレーシング機能のために、独自のニューラルスーパーサンプリングおよびデノイズ技術で同様のアプローチに従っているようだ。
XenoSpectrum’s Take
AMDのRDNA 4アーキテクチャは、長年の課題であったレイトレーシング性能とAI性能に重点を置き、ゲーミングGPU市場における競争力を大幅に強化する可能性を秘めている。特に、AIアクセラレータの強化は、FSR 4などのアップスケーリング技術の画質向上に貢献し、NVIDIAのDLSSに対抗する上で重要な要素となるだろう。モノリシック設計への回帰とTSMC N4Pプロセスノードの採用は、電力効率とパフォーマンスのバランスを取るための戦略的な選択と思われる。
ただし、RDNA 4がハイエンドGPU市場でNVIDIAの最上位モデルに対抗しないことは明らかだ。AMDは、メインストリームセグメントに焦点を当て、価格性能比で優位に立つことを目指している。供給不足が続く現状では、Radeon RX 9000シリーズの実際の価格と入手性は、MSRPとは大きく異なる可能性がある。今後の詳細なベンチマークテストと市場の動向に注目する必要がある。
Source