
新しい人工知能(AI)モデルが、「一般知能」を測定するために設計されたテストにおいて、人間レベルの結果を達成した。
12月20日、OpenAIのo3システムは、ARC-AGIベンチマークで85%のスコアを記録し、これまでのAIの最高スコアである55%を大きく上回り、人間の平均スコアと同等となった。また、非常に困難な数学テストでも好成績を収めた。
人工一般知能(AGI)の創造は、主要なAI研究所すべての掲げる目標である。一見すると、OpenAIはこの目標に向けて少なくとも重要な一歩を踏み出したように見える。
懐疑的な見方は残るものの、多くのAI研究者や開発者は何かが変化したと感じている。多くの人々にとって、AGIの実現が以前より現実的で、緊急性が高く、予想よりも近づいているように思える。彼らは正しいのだろうか?

汎化と知能について
o3の結果が意味することを理解するには、ARC-AGIテストが何を測定しているのかを理解する必要がある。技術的には、新しい状況に適応する際のAIシステムの「サンプル効率」- つまり、システムが新しい状況の仕組みを理解するために必要な例示の数を測定するテストである。
ChatGPT(GPT-4)のようなAIシステムは、サンプル効率が高くない。人間のテキストの何百万もの例から「訓練」され、どの単語の組み合わせが最も可能性が高いかという確率的な「ルール」を構築している。
その結果、一般的なタスクはかなり得意である。しかし、一般的でないタスクは、そうしたタスクに関するデータ(サンプル)が少ないため、苦手としている。
AIシステムが少数の例から学習し、より高いサンプル効率で適応できるようになるまでは、非常に反復的な作業や、時々の失敗が許容される作業にしか使用されないだろう。
限られたデータのサンプルから、未知または新規の問題を正確に解決する能力は、汎化能力として知られている。これは知能の必要不可欠な、基本的な要素として広く考えられている。
グリッドとパターン
ARC-AGIベンチマークは、小さなグリッドマス目の問題を使用してサンプル効率の高い適応能力をテストする。AIは左のグリッドを右のグリッドに変換するパターンを理解する必要がある。
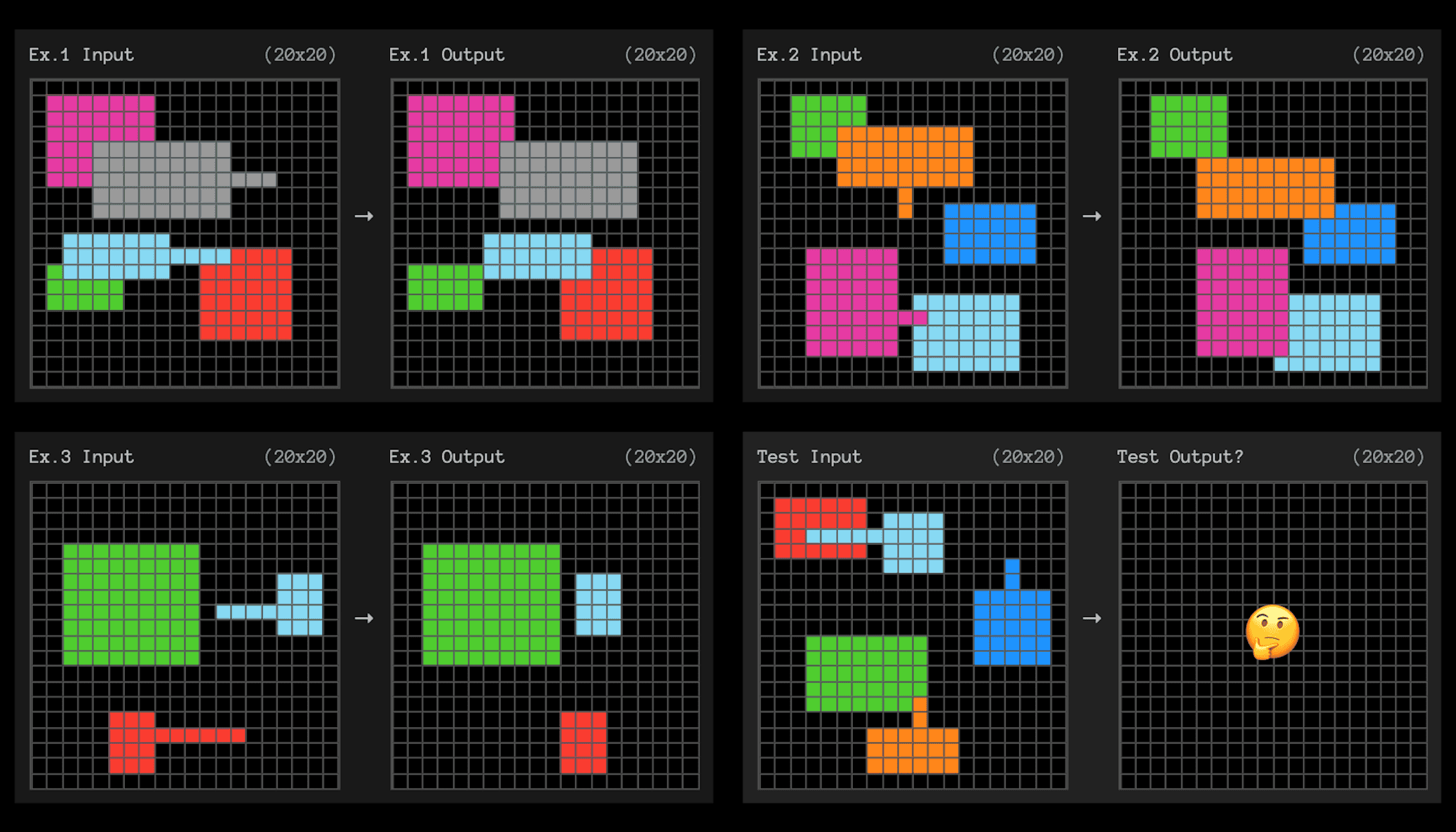
各問題は学習用に3つの例を提供する。AIシステムは、3つの例から4つ目に一般化できるルールを理解する必要がある。
これらは学校で経験したかもしれないIQテストによく似ている。
弱いルールと適応
OpenAIがどのように実現したのかは正確にはわからないが、結果からo3モデルは高い適応性を持っていることが示唆される。わずかな例から、一般化可能なルールを見つけることができる。
パターンを理解するには、不必要な仮定を避け、必要以上に具体的にならないようにする必要がある。理論的には、求める結果を得るための「最も弱い」ルールを特定できれば、新しい状況への適応能力を最大化したことになる。
弱いルールとは何を意味するのか?技術的な定義は複雑だが、弱いルールは通常、より単純な文で説明できるものである。
上記の例では、ルールを平易な言葉で表現すると、「突き出た線のある形は、その線の端に移動し、重なる他の形を『覆い隠す』」というようなものになるだろう。
思考の連鎖を探索?
OpenAIがこの結果をどのように達成したのかはまだわからないが、o3システムが意図的に弱いルールを見つけるように最適化されたとは考えにくい。しかし、ARC-AGIタスクで成功するためには、それらを見つけ出しているはずである。
わかっているのは、OpenAIが一般目的版のo3モデル(難しい問題について「考える」時間をより多く取れる点で他のモデルとは異なる)から始め、その後ARC-AGIテストに特化した訓練を行ったということである。
このベンチマークを設計したフランスのAI研究者François Cholletは、o3がタスクを解決するための異なる「思考の連鎖」を探索し、何らかの緩やかに定義されたルールまたは「ヒューリスティック」に従って「最良」のものを選択していると考えている。
これは、GoogleのAlphaGoシステムが世界のGo チャンピオンを打ち負かすために、異なる手順の可能性を探索した方法と「大きく異なるものではない」という。
これらの思考の連鎖は、例に適合するプログラムのように考えることができる。もちろん、囲碁のAIのような仕組みであれば、どのプログラムが最良かを決定するためのヒューリスティック(緩やかなルール)が必要となる。
同等に有効に見える何千もの異なるプログラムが生成される可能性がある。そのヒューリスティックは「最も弱いものを選ぶ」や「最も単純なものを選ぶ」といったものかもしれない。
しかし、AlphaGoのような場合、彼らは単にAIにヒューリスティックを作成させた。これがAlphaGoのプロセスだった。Googleは異なる手順の連鎖を、より良いものとより悪いものとして評価するようモデルを訓練した。
まだわからないこと
では、これは本当にAGIに近づいているのだろうか?もしo3がそのように機能しているのであれば、基礎となるモデルは以前のモデルとそれほど変わらないかもしれない。
モデルが言語から学習する概念は、以前より汎化に適しているわけではないかもしれない。代わりに、このテストに特化したヒューリスティックを訓練する追加のステップを通じて、より汎化可能な「思考の連鎖」を見つけているだけかもしれない。証拠は、いつものように実際の結果にあるだろう。
o3についてはほとんどすべてが未知のままである。OpenAIは、いくつかのメディアプレゼンテーションと、一握りの研究者、研究所、AIセーフティ機関による初期テストに情報開示を限定している。
o3の可能性を真に理解するには、評価、その能力の分布の理解、失敗する頻度と成功する頻度など、広範な研究が必要となる。
o3が最終的にリリースされれば、平均的な人間と同程度の適応能力があるかどうかがより明確になるだろう。
もしそうであれば、自己改善する加速された知能の新時代を迎え、革命的な経済的影響をもたらす可能性がある。AGI自体の新しいベンチマークと、それをどのように統治すべきかについての真剣な検討が必要となるだろう。
そうでなければ、これは依然として印象的な結果ではあるが、日常生活は大きく変わらないままだろう。
