
モバイルデバイスへの知能の実装は、長らく物理学と熱力学との終わりのない闘いであった。ユーザーが手のひらで稼働する音声アシスタントに求めるのは、冷徹に空調管理された巨大データセンターで稼働する数兆パラメータ規模の人工知能と同等のレスポンスである。だが、スマートフォンの限られたDRAM容量とバッテリーの制約は、巨大な言語モデルの常駐を容赦なく拒絶してきた。
この絶対的な物理の壁を迂回するため、業界はこれまで二つのアプローチを模索してきた。一つは、プライバシーという概念を担保に入れ、あらゆる処理をクラウドへ転送する手法。もう一つは、MoE(Mixture-of-Experts)アーキテクチャを採用し、処理のたびに小さなニューラルネットワークの断片を切り替える手法だ。だが、後者のMoEにも致命的な弱点が潜んでいる。文章をたった1トークン生成するごとに、フラッシュメモリからDRAMへ異なるパラメータ群を読み込む(スワップする)必要があり、その膨大なローディングコストがモバイルデバイスの細いメモリ帯域を瞬時に食いつぶしてしまうのだ。
完全にローカルで、プライバシーを守りながら、数十億から数百億パラメータに及ぶ知性をリアルタイムに叩き起こすことは不可能なのか。
2026年6月、WWDCの熱狂の直後にAppleが提示した解答は、半導体設計とソフトウェアの境界を完全に溶かしてしまう、極めてエレガントなアーキテクチャの刷新だった。同社が発表した「第3世代Apple Foundation Models(AFM)」[1]、そしてその中核をなす「Instruction-Following Pruning(IFP)」技術は、スマートフォンという閉鎖空間におけるAIの歴史に明確なパラダイムシフトを引き起こす。
「DRAMの壁」を打ち破る動的プルーニングの魔法
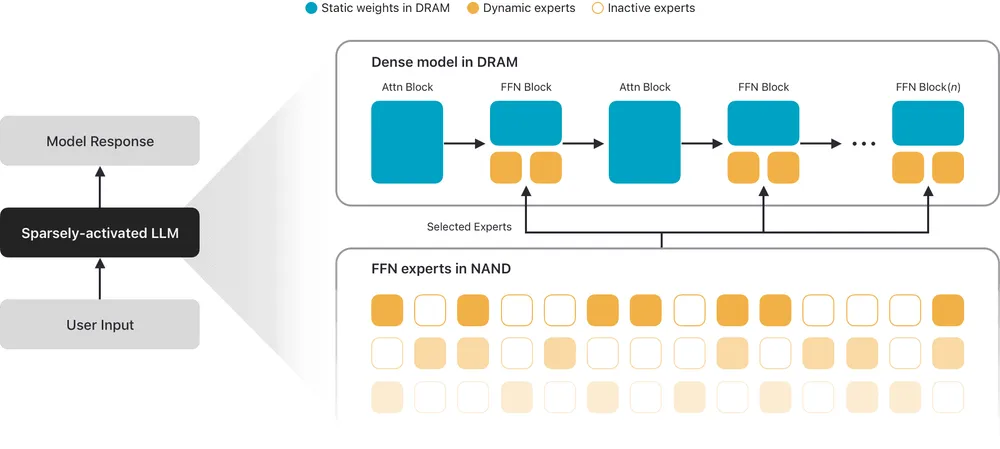
Appleの機械学習研究チームが新たに設計したオンデバイスの最高峰モデル「AFM 3 Core Advanced」は、総パラメータ数200億(20B)という、本来であれば最新のiPhoneのメインメモリを完全に埋め尽くしてしまうほどの容量を持つ。彼らはこの巨大な知性を常にDRAM(作業机)に広げておくという愚行を犯さなかった。代わりに編み出したのが、Instruction-Following Pruning(指示追従型プルーニング)[2]と呼ばれる全く新しい推論アプローチである。
この技術の根幹は、モデルの重みの大部分をNANDフラッシュストレージ(広大な書庫)に眠らせておき、ユーザーからのプロンプトが入力された瞬間に、必要な知識だけを切り出してDRAMに展開するという極めて合理的な仕組みにある。
従来のMoEが単語を一つ生成するたびに書庫と作業机を往復し続けるのに対し、IFP技術はプロンプトを受け取った直後、わずか3億パラメータ程度の超軽量な「予測器(Sparsity Predictor)」にタスクの性質を解析させる。例えば、指示が微分積分を求める数学の問題であれば数学に特化したニューラルネットワークの経路を、Pythonコードの生成であればそのための経路を瞬時に特定する。そして、200億のパラメータプールの中から、その瞬間のタスクに最も適した10億から40億(1B〜4B)のパラメータだけを抽出し、固定のサブネットワークを構築する。
トークン生成が始まると、抽出されたパラメータはDRAM上で完全に固定されたまま推論を行う。生成中に新たなパラメータを読み込む忌まわしいローディング遅延は一切発生しない。作業机には必要な専門書だけが置かれ、推論が完了するまで不要な資料の出し入れは行われない仕組みだ。
Appleが公開した論文データは、この動的プルーニングの破壊力を実証している。パラメータを9Bから3Bへ動的に切り詰めたIFPruningモデルは、最初から3Bで訓練された高密度モデルと比較して、コーディングタスク(HumanEvalなど)で最大14%、数学ベンチマーク(GSM8K等)で5%〜8%の圧倒的な性能向上を見せた。実際に稼働しているパラメータ数が同じ3Bでありながら、上位の9Bモデルに肉薄する計算能力を発揮している。限られたリソースの中で知能の密度を極限まで高める、純粋なエンジニアリングの勝利だ。
Siriを根底から作り変える5つの頭脳
今回の発表でAppleは、用途とハードウェアの制約に合わせてスケーリングする5つのモデルからなる「AFM 3ファミリー」の全貌を明らかにした。これらはiOS 27、iPadOS、macOSの深層に組み込まれ、エコシステム全体を直接駆動する実用的インフラとして稼働する。
| モデル名 | 稼働環境 | 規模 / アーキテクチャ | 主な役割と特徴 |
|---|---|---|---|
| AFM 3 Core | オンデバイス | 30億 (3B) / 密結合 (Dense) | 旧世代から基本性能を底上げした常時稼働のベースモデル。 |
| AFM 3 Core Advanced | オンデバイス | 200億 (20B) / 疎結合 (Sparse) | IFP技術で1〜4Bを動的活性化。自然な音声合成、高精度なコンテキスト理解。 |
| AFM 3 Cloud | サーバー (PCC) | 非公開 / 密結合 | 高速かつ効率的なサーバー側のワークホース。日常的な複雑なクエリを処理。 |
| ADM 3 Cloud (Image) | サーバー (PCC) | 非公開 / 画像生成特化 | Image Playground、Photosの空間リフレーミングなどの高度なピクセル生成。 |
| AFM 3 Cloud Pro | サーバー (PCC) | 非公開 / 大規模モデル | エージェント的なツール操作や高度な論理推論を担う最上位の頭脳。 |
日常的なインターフェースの質を劇的に引き上げる「AFM 3 Core Advanced」のマルチモーダル性能は群を抜いている。同モデルは人間によるブラインドテスト(Mean Opinion Score: MOS、5点満点)において、現在の本番環境のテキスト読み上げシステム(スコア3.82)を凌駕し、会話調の読み上げで「4.24」という驚異的な数値を叩き出した。MOSスコアにおける0.1の向上はユーザーが明確に違いを知覚できる閾値とされている。0.42もの飛躍は、新Siriの声が機械的な合成音の域を脱し、息遣いさえ感じさせる自然なアシスタントへと変貌したことを示している。
同時に、グローバル市場への影響も見逃せない。PFIGSCJK(ポルトガル語、フランス語、イタリア語、ドイツ語、スペイン語、中国語、日本語、韓国語)の多言語対応テストにおいて、オンデバイスの「AFM 3 Core」は旧世代モデルに対し43.0%の支持を獲得(旧世代は26.0%)。クラウド版の「AFM 3 Cloud」に至っては、旧モデルの6.9%という支持率を68.3%へと圧倒的に塗り替えた。英語圏特化というこれまでの批判を払拭し、全世界のユーザー体験を均質に引き上げる準備が整っている。
そして、iOS 27の深奥に配置された「System Orchestrator」がユーザー体験の要を握る。画面上の文脈(オン・スクリーン・コンテキスト)や個人的なデータを読み取るSpotlight Semantic Indexと連携し、ユーザーの要求がローカルの1〜4Bの頭脳で処理できるものか、あるいは広大な計算資源を必要とするものかをシステム側がミリ秒単位で冷徹にトリアージする。複雑な推論や数学的解法が必要な場合、オーケストレーターは即座に「AFM 3 Cloud Pro」へ処理を受け渡す。この最上位モデルは、ベースとなるAFM 3 Cloudと比較して数学タスクで14%の相対的改善を見せ、エージェント的なツール操作(Tool Execution)において比類ない精度を発揮する。
競合インフラを使い倒すプラグマティズムと知識蒸留
Apple Intelligenceがクラウドの力を必要と判断した時、リクエストは「Private Cloud Compute(PCC)」へと暗号化されたまま転送される。PCCはAppleが「iPhoneのプライバシー境界をクラウドまで拡張する」と豪語する独自のインフラだが、ここで極めて興味深い業界の力学が姿を現す。最上位の「AFM 3 Cloud Pro」を稼働させるため、AppleはGoogleおよびNVIDIAと手を結び、Google Cloud内にNVIDIA GPUを活用したPCCインフラを間借りしているのだ。
ソフトウェアエンジニアリング担当SVPのCraig Federighiは、WWDC後のプレス向けセッションで、この協業の性質について慎重かつ明確に線を引いた。
「我々はGoogleのGeminiアプリを組み込んでいるわけではない。iOS上にGoogleのクライアントコードは一切存在せず、Googleが一般顧客にデプロイしているモデルそのものを使っているわけでも、検索エンジンをシステムの基盤にしているわけでもない。我々が利用するGoogle Assistantの量は『ゼロ』だ」
Federighiの言葉を技術的な文脈で翻訳すれば、Appleは競合のサービスをOSの特等席に招き入れるという危険を冒したわけではない。彼らが行ったのは、高度に管理されたインフラの冷徹な外部委託である。
さらに深く踏み込めば、AI担当VPのAmar Subramanyaの口から語られた「Gemini frontier modelsからの出力を利用した洗練」という事実こそが、この協業の核心を突いている。これは機械学習の分野で「知識蒸留(Knowledge Distillation)」と呼ばれる手法だ。Appleは、数兆パラメータクラスと推測されるGoogleの最上位モデル(Gemini)の膨大な出力結果を教師として用い、自社の独自モデル(AFM)にその推論パターンや論理構造を効率的に流し込んで学習させたのである。
競合他社が自前の巨大データセンター構築に莫大な資本を投じて血を流す中、Appleは自社のエコシステムにおける10億台以上のユーザー接点と、圧倒的なプライバシー保護の枠組み(PCC)を盾に、インフラはGoogleとNVIDIAのものを使い倒し、最高峰の知識だけを蒸留して自社のモデルに吸収する。これほどプラグマティックで計算し尽くされた戦略は他に類を見ない。

サプライチェーンを揺るがすトレードオフと、次代の到達点
この野心的なアーキテクチャが業界全体にもたらす影響は、単なるソフトウェアのアップデートに留まらない。Instruction-Following Pruningによるオンデバイス推論は、DRAMのスワップコストを劇的に削減した反面、NANDフラッシュストレージには200億パラメータ分の重みデータ(数十GB規模)を常に待機させておく必要がある。
このストレージへの激しい圧迫は、Appleの今後のハードウェア展開とサプライチェーンに直接的な波及効果をもたらす。次期iPhoneラインナップにおいて、ベースモデルの最小ストレージ容量が128GBから256GBへと強制的に引き上げられる可能性は極めて高い。同時に、一時的に展開する1〜4Bのパラメータ群とOSの基本動作を支えるため、DRAMの搭載量も最低12GBが標準となるだろう。NANDフラッシュおよびDRAMのサプライヤー(Samsung、SK Hynix、Micronなど)にとって、AppleのこのAIアーキテクチャ移行は巨大な特需を引き起こす起爆剤となる。
技術的な課題も残されている。タスクごとに最適なニューラルネットワークの経路を選択する「Sparsity Predictor」の推論自体は軽量だが、最初のトークンが出力されるまでの遅延(Time-to-First-Token)にわずか数ミリ秒のオーバーヘッドを加える。この微小なレイテンシの蓄積が、サードパーティのアプリケーション内でどこまで滑らかに吸収されるかは、今後のソフトウェア最適化の進展に委ねられている。
iOS 27とAFM第3世代が示したパラダイムシフトの意義は揺るがない。デバイスの物理的限界を強引なハードウェアスペックの向上でねじ伏せるのではなく、人間の脳がタスクに応じて必要な領域だけを活性化させるように、動的かつエレガントに知性を切り出すアプローチ。そして、ローカルでの完結に固執せず、プライバシーという絶対的な防壁を構築した上で競合のクラウドインフラすら貪欲に取り込む柔軟性。
AIの進化が「パラメータの暴力的な巨大化」という単調な力比べに陥りつつある中、Appleはハードウェア、OS、そしてクラウドを貫く「徹底した最適化」という自らが支配する土俵へ、見事に戦局を引きずり込んだのである。


