画像生成で最も厄介だったのは、絵のうまさそのものではなく、文字と構造が崩れることだった。ChatGPT Images 2.0は、その弱点を正面から潰しにきたモデルである。密な文字描画、非ラテン文字を含む多言語出力、複数画像の連続生成、自己点検、Web検索を一体化し、単発の「それっぽい絵」ではなく、実務でそのまま使える視覚成果物に近づけている。
OpenAIが2026年4月22日に公表したこの更新は、画質向上だけに留まらない。ChatGPT、Codex、APIで利用でき、思考モードでは調査、構成、検証まで画像生成の中に取り込む。画像を描く機能が強くなっただけでなく、画像を作る前後の仕事まで含めた制作経路が変わっているのだ。
何が新しくなったのか
ChatGPT Images 2.0の変化を最も端的に言えば、画像の「見た目」よりも「正確さ」と「組み立て方」が大きく前進した点にある。OpenAIはこのモデルを、細かな指示追従、物体同士の関係性の再現、密な文字の描画、アスペクト比への追従で従来より強いと説明している。APIでは最大2K解像度に対応し、縦長のポスターから横長のバナーまで、用途に合わせた出力を狙いやすくなった。

2.0は、thinkingモードによってWeb検索、複数画像生成、自己点検を画像生成の流れに組み込んだ。画像を1枚描いて終わりではなく、情報収集、構成、検査を通したうえで出力する設計になっている。
この更新で大きいのは、非ラテン文字の品質が実用域に迫ったことでもある。OpenAIは日本語、韓国語、中国語、ヒンディー語、ベンガル語で特に改善が大きいとしている。従来の画像モデルは英語やラテン文字に比べ、複雑な文字列や密なレイアウトで崩れやすかった。2.0はそこをかなり押し戻し、文字が単なるラベルではなく、デザインの一部として機能するところまで持ち上げた。

加えて、1回で最大8枚まで、キャラクターやオブジェクトの連続性を保ちながら出力できる。これは単なる一括生成ではない。別々の画像を後から並べるのではなく、最初から連続するセットとして作れる。Web検索と組み合わせれば、時事性のある説明図、更新の早い地図、複数カットの比較画像まで、生成の中で整合性を取れる。
画像生成の使い方がどう変わるのか
2.0で変わるのは、ユーザーがAIに与える指示の粒度である。これまでは「1枚の絵をうまく出す」ことが中心だったが、これからは「どの順番で何を作るか」を前提にした依頼になる。OpenAIが示す用途は、ローカライズ広告、インフォグラフィック、解説図、教育コンテンツ、デザインツール、クリエイティブプラットフォーム、Web制作製品まで広い。いずれも、単発の美しい画像より、正確な文字、整ったレイアウト、複数サイズへの展開が重要な領域である。
たとえば、1枚のメニュー画像を作るだけなら、従来モデルでもそれなりに見栄えはした。しかし、店頭ポスター、SNS告知、縦長ストーリー、横長バナーの各サイズで文字やロゴを崩さずにそろえるには、複数回の生成と手作業の調整が必要だった。Images 2.0は、こうした断片的な作業をまとめて扱いやすくする。1つのプロンプトから複数のサイズと構図をまたいで出力できるため、制作物を1枚ずつ繋ぐのではなく、最初から「一式」として組みやすい。
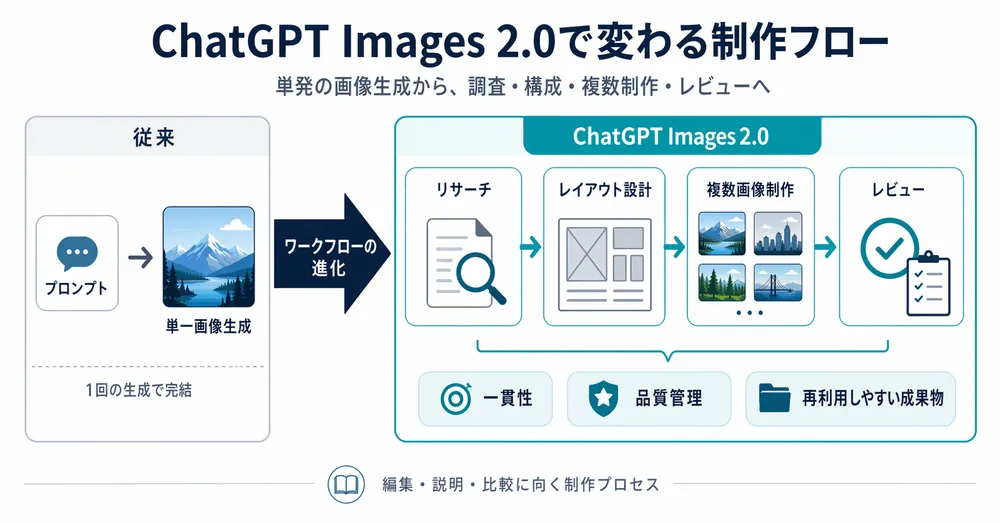
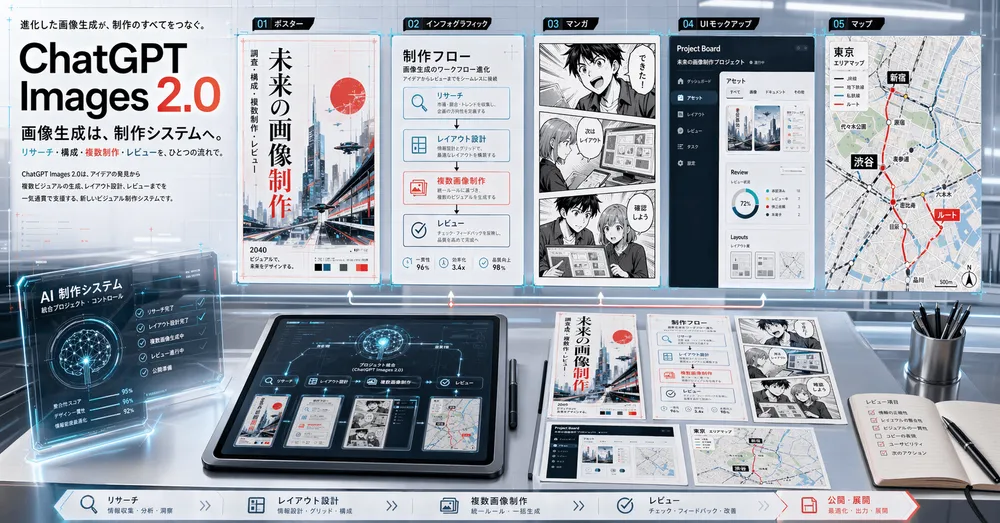
この変化は、漫画、スライド、地図、UIモック、説明図で特に効果的だ。画像の中に入る文字量が多いほど、従来モデルの弱点が露出しやすかったが、2.0は文字、アイコン、UI要素、密な構図、細かなスタイル制約に強い。つまり、画像を「雰囲気の確認」に使うのではなく、「そのまま配布する素材」に近いところまで持っていきやすい。
採用判断を分ける軸は、外部公開物か社内たたき台かである。社内会議用の下書きなら多少の崩れを許容しやすいが、対外向けの告知物や教育資料では、文字の正確さと図の読み取りやすさがそのまま採用可否を左右する。2.0は後者で価値が出やすい。
思考モードの意味もここで大きい。画像を作る前に、必要な情報をWebで集め、アップロード素材を整理し、レイアウトを考え、出力後に自己点検する流れは、制作の前段をAI側に移す。人間がやる仕事は、毎回の細部修正よりも、どのアウトプット群が目的に合うかの選定へ寄っていく。画像生成は「描画ツール」から「視覚的な制作相棒」に近づいた。
ただし、これはクリエイティブの自動化を意味しない。むしろ、初稿の精度が上がることで、人間は最終的な編集判断に集中しやすくなる。広告、教材、社内説明、製品紹介のように、正確さと速度を両立したい場面では、最初のたたき台の品質がそのまま制作コストを左右する。2.0は、そのたたき台の質を引き上げるモデルである。
どこまで使えて、何がまだ曖昧か

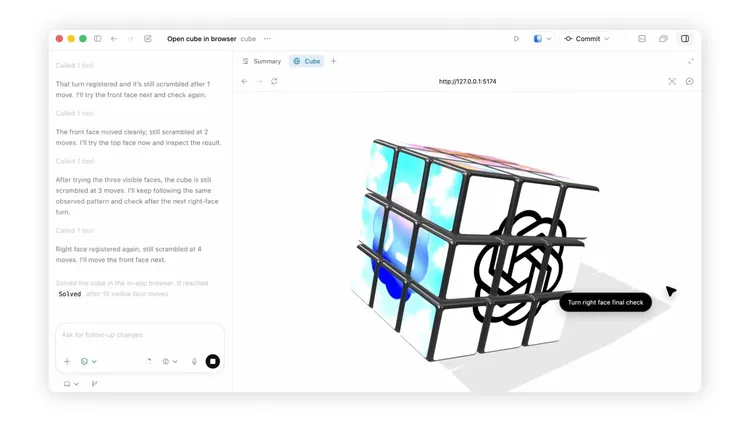
強みが増えた一方で、2.0は万能ではない。OpenAI自身が挙げる制約はかなり具体的で、完全に一貫した物理世界モデルを要する課題、折り紙の手順、ルービックキューブのようなパズル、隠れた面や斜め向き、反転した面に正確さが要る細部ではまだ苦戦する。細かく反復する砂粒のような密なディテールも限界を試しやすい。
ラベルや図解は、見た目が整っていても確認が要る。説明図、部品名、矢印の向き、対応関係のような精密な要素は、非ラテン文字の改善が大きくても、図表の意味対応まで自動で保証されるわけではない。生成物をそのまま公開するより、最終チェックを挟む前提で使うほうが安全だ。
さらに、知識カットオフは2025年12月である。したがって、最新の出来事や最近変わった固有名詞、制度、製品情報を含む画像は、Web検索が使えてもなお、検証を省けない。thinkingモードは更新情報を取り込みやすくするが、現時点での正確性を自動的に保証するわけではない。時事性の高い図解や地図ほど、出力後の見直しが重要になる。
APIでは2K解像度まで対応し、それ以上の出力は現在betaで、不安定になる場合がある。高解像度の静止画や大型の商用素材を前提にするなら、単に「より大きく出せる」ではなく、「どの範囲なら安定して再現できるか」を先に見極める必要がある。実運用では、サイズを上げれば良いという話ではなく、要求精度と安定性のバランスを取る話になる。
安全策とコストはどう見るべきか
高いリアリズムは、同時に高い悪用可能性を意味する。ChatGPT Images 2.0のシステムカードは、実在の人物、場所、出来事をより説得的に偽装できる深刻なリスクを前提にしており、画像生成の安全対策を1層ではなく多層で組んでいる。具体的には、prompt層とimage層の分類器、上流での拒否、下流でのブロック、入力のブロック、出力のブロックを組み合わせる構成である。
これは「生成後に少し見張る」程度の対策ではない。危険なリクエストは生成前に拒否され、通った入力も別の安全モデルが監視し、最終出力まで確認する。さらにOpenAIは、ChatGPT Images 2.0でもC2PAメタデータを維持し、知覚できない堅牢な透かしを組み合わせる方針を示している。生成物の真正性をめぐる議論は残るが、少なくとも出自を示す手当てはモデル本体と並行して強化されている。
コストは導入判断の最後の条件として見るべきである。OpenAIのAPI料金では、GPT-image-2の画像は入力が100万トークンあたり8.00ドル、キャッシュ入力が2.00ドル、出力が30.00ドル、テキストは入力が5.00ドル、キャッシュ入力が1.25ドル、出力が10.00ドルとされる。安さだけで選ぶべきではない。Images 2.0の価値は、単発の画像単価ではなく、調査・構成・多言語・多サイズ展開まで含めた制作工数の圧縮にある。
したがって、採用の判断軸は「画像がきれいか」ではない。文字が読めるか、多言語で崩れないか、連続した画像群を一度に作れるか、Web検索と自己点検で制作の前提をどこまで内包できるか、そして安全性と検証コストを運用に組み込めるかである。ChatGPT Images 2.0は、画像生成を見栄えの競争から制作設計の競争へ押し上げたモデルだと言える。
Sources