
安さと性能は両立するのか?新しいAIモデルが登場するたびに突き付けられるこの問いに、Anthropicの新型モデル「Claude Sonnet 5」は一つの回答を示した。2026年6月30日に発表されたこのモデルは、上位モデルOpus 4.8より約6割安い価格でありながら、知識労働タスクを評価するベンチマーク「GDPval-AA v2」でOpus 4.8をわずかに上回ったとAnthropicは報告している。同社はこれを「最もエージェント的なSonnetモデル」と位置づけ、計画立案からブラウザ・ターミナル操作までを自律的にこなす能力を前面に押し出した。発表のタイミングは、Anthropicが機密裏にIPO目論見書(S-1)をSECに提出した直後にあたる。価格破壊とエージェント能力の両立は、上場準備を進める同社の事業戦略そのものを映し出している。
Sonnet 5の正体と位置づけ
Anthropicの公式発表によれば、Claude Sonnet 5は同社のSonnet系列の中で「最もエージェント的」と位置づけられたモデルだ。単発の応答を返すだけでなく、複数ステップにわたる計画を立て、ブラウザやターミナルといった外部ツールを使い分けながら、人間の介入なしにタスクを完遂する能力に重点が置かれている。学習データのカットオフは2026年1月、コンテキストウィンドウは100万トークンとなっており、長大なコードベースや複数文書にまたがる作業を一括で扱える設計だ。
この発表内容が示すのは、Anthropicがもはやモデルの「賢さ」だけを競う段階を終え、実務で完結するエージェントとしての完成度を競う段階に移ったということだ。チャットボックスに質問を投げて答えを得る使い方から、タスクを丸ごと任せて結果だけを受け取る使い方へ。Sonnet 5の位置づけは、その移行をSonnet系列という量産価格帯のモデルにまで広げた点にある。上位モデルOpus 4.8だけがエージェント能力を持つのではなく、安価なモデルでも実用に足るエージェント性能を確保するという方針転換だ。
ベンチマークで見るOpus 4.8との差
具体的な数値を見ると、Sonnet 5とOpus 4.8の差は縮まりつつも、依然としてOpus 4.8が優位な領域も残っている。
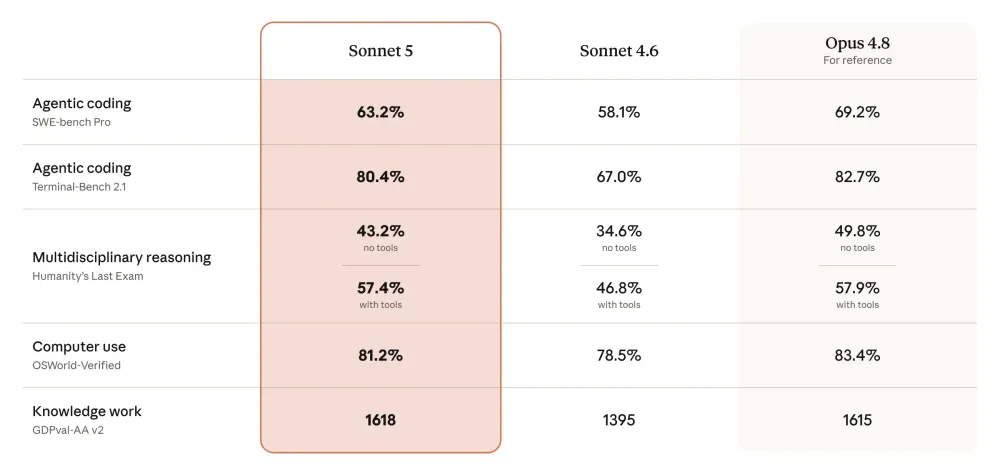
エージェント型コーディングを評価するSWE-bench Proでは、Sonnet 5が63.2%、旧モデルのSonnet 4.6が58.1%、Opus 4.8が69.2%という結果だった。
ターミナル操作能力を測るTerminal-Bench 2.1でも、Sonnet 5は80.4%とSonnet 4.6の67.0%から大きく伸びたが、Opus 4.8の82.7%にはわずかに届いていない。
一方、PC操作の自律実行能力を評価するOSWorld-Verifiedでは、Sonnet 5が81.2%を記録し、旧モデル比の78.5%から改善した。ツール使用込みの汎用知識評価であるHumanity's Last Exam(with tools)では、Sonnet 5が57.4%、Opus 4.8が57.9%とほぼ並んでいる。
最も重要な指標は、知識労働の実務能力を測るGDPval-AA v2でのスコアだ。これについて、Sonnet 5は1,618点を記録し、Opus 4.8の1,615点をわずかに上回ったという。
GDPval-AA v2は、OpenAIが業界専門家と共同開発したデータセットを基盤に、評価機関Artificial Analysisが運用するベンチマークだ。44業種・9業界にまたがる220のタスクで構成され、単純な一問一答ではなく、文書やスライド、図表、スプレッドシートといった実際の完成成果物をエージェント環境内で生成させ、人間の専門家がペアワイズ比較するEloスコアリング方式で評価する。
丸暗記した知識への依存度が低く、実際のオフィスワークに近い形で実務能力を測れる指標として注目されている。Sonnet 5がこの指標でOpus 4.8と肩を並べた、あるいはわずかに上回ったという報道は、価格差を踏まえると小さくない意味を持つ。
価格設計とトークナイザーの罠
Sonnet 5の価格体系は、2026年8月31日までの導入価格として、入力100万トークンあたり2ドル、出力100万トークンあたり10ドルに設定されている。この期間を過ぎると、標準のSonnet価格である入力3ドル・出力15ドルに移行する仕組みだ。比較対象となるOpus 4.8は入力5ドル・出力25ドルであり、標準価格に移行した後でも、Sonnet 5はOpus 4.8よりおよそ6割安いという計算になる。
ただし、この価格設計には見落とされがちな仕掛けがある。Sonnet 5はOpus 4.7と同様、新しいトークナイザーを採用している。同じ文章を入力しても、従来のトークナイザーに比べて1.0倍から最大1.35倍のトークン数として処理される可能性があるという。導入価格はこのトークン数増加分を織り込み、実質的なコストがほぼ中立になるよう設計されているとみられるが、処理量の多いワークロードでは、見かけの単価が下がっていても実質的な値上げになりかねない。1リクエストあたりのコストではなく、実際の請求額で評価する必要がある。
導入価格・標準価格・トークナイザー変更という3つの要素を順に並べると見えてくるのは、Anthropicが額面上の安さだけでなく、実運用コストの設計にまで踏み込んでいるという姿勢だ。安さを謳う一方で、ヘビーユーザーには相応の負担を求める。この二段構えの価格戦略こそが、Sonnet 5の「6割安」という見出しの裏側にある実態だ。
安全性評価とサイバー規制の文脈
価格と性能の話だけでは、Sonnet 5の立ち位置は語り尽くせない。米政府はAnthropicの最上位モデル群であるMythos 5・Fable 5について、サイバーセキュリティ上の懸念から提供を制限している。この文脈の中で、Sonnet 5がどう位置づけられているかは重要な論点だ。
Anthropicとシステムカードによれば、Sonnet 5はサイバー関連タスクで意図的に訓練されていない。自動検知・ブロックといったサイバー安全策はOpus 4.7・Opus 4.8と同水準で有効化されているが、Fable 5に課されたガードレールよりは緩い設計だという。The Decoderはこの設計について、Sonnet 5が意図的にサイバー能力を抑制することで、米政府が懸念する領域への抵触を避けようとしているとの分析を示している。
この姿勢を裏づけるのが、Mozillaと共同実施したFirefox 147脆弱性のexploit開発評価だ(脆弱性自体はFirefox 148で修正済み)。Sonnet 5・Sonnet 4.6とも完全なexploit開発の成功率は0%だった。部分的な成功率ではSonnet 5が13.2%とSonnet 4.6の8.8%よりやや高いものの、完全成功には至っていない。対照的に、Opus 4.8は完全exploit成功率68.8%、Mythos 5に至っては88.4%を記録している。同じAnthropic製モデルでありながら、Sonnet 5とOpus 4.8の間にこれほどの差が生じている事実は、モデルごとに意図的にリスクの線引きを変えているAnthropicの設計思想を示している。
安全性評価の全体像としては、Sonnet 4.6と比べてhallucination(事実と異なる出力)やsycophancy(過度な迎合)の傾向が低下し、プロンプトインジェクションへの耐性も向上した。自動行動監査における誤動作率もSonnet 4.6より低く抑えられている。ただし、Opus 4.8やMythos Previewと比べると誤動作率はやや高い水準にとどまっている。Sonnet 5は、価格帯に見合った範囲で安全性を確保したモデルと位置づけられる。
なぜ今なのか、IPO戦略との関係
Sonnet 5の発表タイミングを理解するには、Anthropicの資金調達の推移を押さえておく必要がある。同社は2026年2月にSeries Gで300億ドルを調達し、評価額3800億ドル、年換算収益140億ドルに達した。そのわずか3カ月後の2026年5月末には、Series Hで650億ドルを調達し、評価額は9650億ドル、収益ランレートは470億ドルにまで跳ね上がっている。そして2026年6月初旬、Anthropicは機密裏にIPO目論見書(S-1)をSECに提出したと報じられた。Sonnet 5の発表は、この提出から3週間あまり後というタイミングで行われている。
評価額や収益ランレートの急成長そのものは華々しいが、米証券アナリストの間で注目されているのはむしろ地味な指標、すなわち粗利益率だという。CNBCの取材に対し、PitchBookのアナリストHarrison Rolfes氏は「評価額や収益ではなく粗利益率こそが、市場がこの3年間織り込んできたナラティブを検証する、あるいは崩壊させる数字になる」と述べている。外部アナリストの試算によれば、Anthropicの現状の粗利益率は推論コストの超過により約40%まで圧縮されており、2028年までに77%への改善を目標としているという。一部のアナリストは、基礎的な推論部分に限った粗利益率はすでに70%を超えているとの見方も示している。
D.A. DavidsonのアナリストGil Luria氏はより慎重な見方を示す。「Anthropicはフロンティアモデルでリードしているように見えるが、現在の利用の多くは試用や実験段階にとどまっており、持続しない可能性がある」と指摘した。Sonnet 5が打ち出した「6割安なのに性能で見劣りしない」という価格設計は、まさにこうした懐疑論に対する回答だと読める。試用段階の利用を本格的な継続利用に転換させるには、価格の安さと実務での完結力という両輪が欠かせない。IPOで粗利益率を開示する局面を控え、Anthropicは量産価格帯のモデルで稼ぐ力を証明する必要に迫られている。
企業の反応と競合構図
実際の利用企業からは、Sonnet 5のエージェント能力に対する評価の声が上がっている。Zapierのシニアエンジニア、Daniel Shepard氏は「Salesforceのアカウント階層更新とエンタープライズ顧客への発表メール送信という2段階の仕事を渡したところ、エンドツーエンドで完了した。以前は途中で止まっていた」と語る。Lovableの共同創業者Fabian Hedin氏は「安全でないリクエストをきれいに一貫して拒否する」と安全性面を評価し、Cursorの共同創業者Sualeh Asif氏は「Sonnet 5ではエージェントが計画通りに進み、規約に従い、効率的なコストでクリーンな複数ステップの変更を出荷する」と述べている。
企業向けの動きとしては、2026年6月29日にカリフォルニア州のNewsom知事がClaudeを州機関向けに50%割引で提供するパートナーシップを発表したことも報じられている。
競合各社の動きも見逃せない。OpenAIは2026年6月、GPT-5.6シリーズ(Sol・Terra・Luna)をプレビュー発表した。Solの価格は入力5ドル・出力30ドル(100万トークンあたり)で、サブエージェントを並列稼働させる「Sol Ultra」高負荷モードはTerminal-Bench 2.1で91.9%を記録し、他社の公開スコアと比べても最高水準だという。ただし提供は約20組織限定のプレビューにとどまり、一般提供は数週間後とされている。Googleは2026年5月19日のGoogle I/Oで、Gemini 3.5 Flashを発表した。価格は入力1.5ドル・出力9ドルとさらに安く、Terminal-Bench 2.1で76.2%、従来のGemini 3.1 Proに比べ約4倍の速度を主張している。
資金面では、OpenAIが1220億ドルを調達し評価額8520億ドルでIPO準備を進めているほか、xAIと合併したSpaceXは評価額1兆7700億ドルで株価135ドルにてすでに上場している。
Sonnet 5、GPT-5.6 Sol、Gemini 3.5 Flashという3つのモデル群を並べると、フロンティアAI各社が単純な性能競争から、エージェントとしての実務完結力と価格の両立という、より複雑な競争軸へ移行していることが見えてくる。Opus比6割安という価格は単なる値引きではなく、IPOを目前に控えたAnthropicが「安いから妥協」ではなく「実用十分」を武器に量産フェーズへ踏み出した号砲と捉えるべきだろう。次に注目すべきは、この価格戦略がIPOで開示される粗利益率の数字にどう反映されるかだ。