
人気法廷バトルゲーム『逆転裁判』が、最新AIモデルの推論能力を測る意外なベンチマークとして使用され、話題を呼んでいる。カリフォルニア大学サンディエゴ校のHao AI Labが行ったこのテストでは、OpenAIやGoogleなどの最先端AIもゲームクリアには至らず、人間の持つ複雑な思考能力の再現がいまだ困難であることが示された。
『逆転裁判』がAIテストの新基準となった理由
なぜ、数あるゲームの中から『逆転裁判』が選ばれたのだろうか。Hao AI Labによると、このゲームは単なる記憶力やパターン認識能力だけでは攻略できない、AIにとって多角的な挑戦を提供するからである。
これまで、Hao AI Labは、『キャンディクラッシュ』、『2048』、『倉庫番』、『テトリス』、『スーパーマリオ』など様々なゲームでAI言語モデルのベンチマークを行ってきた。しかし、これまでテストされたすべてのタイトルの中で、『逆転裁判』は推論に関して最も要求の厳しいメカニクスを持つゲームである可能性が高いのだ。
具体的には、以下の能力が試される。
- 長文脈推論: プレイヤーは、過去の会話や集めた証拠品といった広範な情報(長いコンテキスト)の中から、証人の発言に含まれる矛盾点を見つけ出す必要がある。これは、断片的な情報をつなぎ合わせ、全体像を把握する高度な推論能力を要求する。
- 視覚理解: ゲーム中では、証拠品として提示される画像や図面が重要な役割を果たす。AIは、テキスト情報だけでなく、画像の内容を正確に理解し、どの画像が偽証を覆す決定的な証拠となるかを見抜かなければならない。
- 戦略的意思決定: 裁判パートでは、証人を「ゆさぶる」べきか、決定的な「証拠品」を「つきつける」べきか、あるいは情報を引き出すために待つべきか、状況に応じた最適な行動を選択する必要がある。これは、短期的な反応だけでなく、裁判全体の流れを読んだ戦略的な判断力が求められる。
研究チームは、「ゲームデザインは、AIに単なるテキストや視覚タスクを超えた、文脈を理解し行動に変換することを要求する」と説明している。 さらに、『逆転裁判』のようなゲームは、単に正解を記憶する「過学習」を起こしにくいという利点もある。成功するためには、文脈に応じた行動空間での真の推論能力が必要とされるからだ。 これは、特定のタスク(数学やコーディングなど)に最適化されたモデルが、新しい未知の問題に対してうまく機能しないことがある「過学習」の問題を回避する上で重要となる。
このテストは、OpenAIの共同創業者であるIlya Sutskever氏が、AIの次単語予測能力を「探偵小説を理解するようなもの」と例えたことに一部触発されたものでもある。
テスト結果詳報:AIたちの苦闘と性能差
今回、Hao AI Labは4つの主要なAIモデルをテスト対象とした。
- OpenAI o1
- Google Gemini 2.5 Pro
- Anthropic Claude 3.7 Sonnet (extended thinking mode)
- Meta Llama-4 Maverick
結果から言うと、いずれのAIモデルも『逆転裁判』の全5エピソードをクリアすることはできなかった。
Meta社のLlama-4 Maverickは最初のエピソードで早々に敗退。Anthropic社のClaude 3.7 Sonnetもエピソード2の途中でゲームオーバーとなった。
健闘したのはOpenAIのo1とGoogleのGemini 2.5 Proで、両モデルとも4番目のエピソードまで進むことができた。 しかし、最終的なクリアには至らなかった。 研究者によると、最も難しいケースにおいてはo1がGemini 2.5 Proを上回るパフォーマンスを見せ、「最高の弁護士はo1だった」と評価されている。
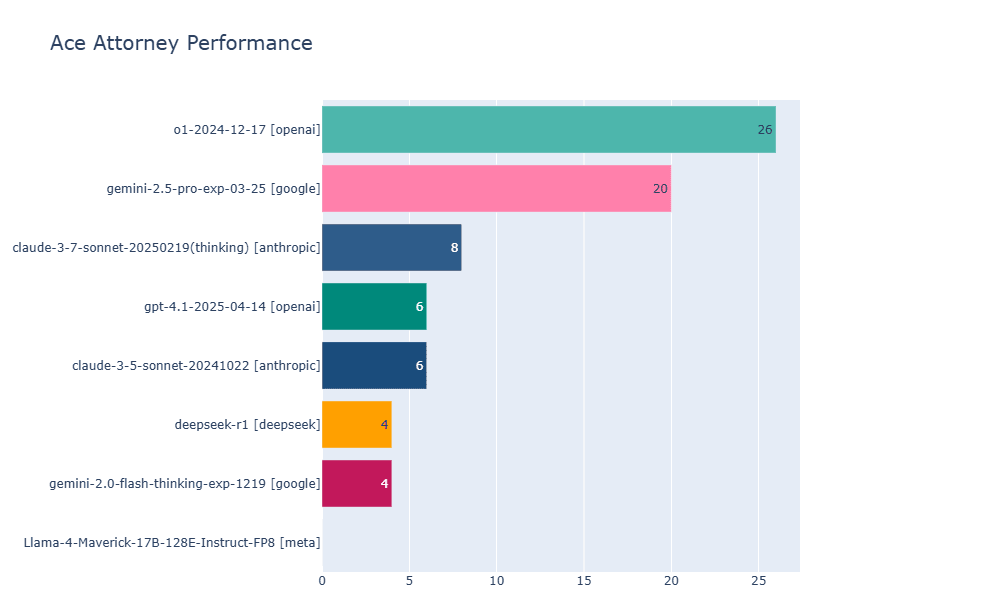
一方で、コストパフォーマンスの面ではGemini 2.5 Proが顕著な優位性を示した。Hao AI Labの報告によると、Gemini 2.5 Proはo1と比較して6倍から15倍も安価であったという。 例えば、特に長時間を要したエピソード2のあるシナリオでは、o1のコストが45.75ドルを超えたのに対し、Gemini 2.5 Proはわずか7.89ドルでタスクを完了した。 これは、推論に特化していないGPT-4.1(100万入力トークンあたり2ドル)と比較しても、Gemini 2.5 Pro(同1.25ドル)の方が安価であることを示している(ただし、画像処理の要件により実際のコストは若干高くなる可能性がある)。
この結果は、現在の最先端AIであっても、『逆転裁判』が要求するような多層的な推論、状況判断、証拠と証言の関連付けといった複雑なタスクを人間のようにこなすことは難しいことを示唆している。
開発者・杉森正和氏の驚きと考察
このユニークなAIテストに対して、『逆転裁判』シリーズ初期の楽曲制作を手掛け、作中で「狩魔豪」の声も担当したゲーム開発者の杉森雅和氏が、自身のX(旧Twitter)アカウントで反応を示した。
杉森氏は、「何と言うか、25年前に死ぬ思いしながら作ったゲームがこういう使い方されるようになるとは思わなかったよwしかも海外でw」と、驚きを隠せない様子を投稿した。
さらに、AIモデルが特にゲームの最初のエピソードで苦戦しているという結果に対し、興味深いコメントを寄せている。
「1章でAIが詰まるの面白い。特に1章の難易度はめっちゃ巧さん(ディレクターの巧舟氏)と三上さん(エグゼクティブプロデューサーの三上真司氏)が拘られた部分。人間には簡単なはずなんよw その推論力ってやつが人間の強みなのか。」
杉森氏は続けて、当時の開発における難易度調整の意図を明かした。
「巧さんと三上さんが逆転裁判1の1章の難易度を特に拘られた理由は、
『それまで世界に無いゲームだったから』です。広く受け入れられる難易度、さりとて簡単すぎてバカにされていると感じない難易度、答えを閃いた瞬間気持ち良い難易度、みたいのを目指されていました」
AIと人間の推論能力の現在地と展望
今回の研究結果から、最新のAIモデルでも人間のような直感的な推論能力には及ばないことが示された。特に「逆転裁判」の第1話は初心者向けに設計されたものであり、人間のプレイヤーには比較的簡単なはずのゲームでAIが躓いたことは、AIの推論能力の現状を如実に映し出している。
一方で、杉森氏は技術の進化におけるビデオゲームの役割については全体的にポジティブな姿勢を示しつつも、「同時に、私たち人間はAIに負けないと思います。個々のタスクを実行する際には負けるかもしれませんが、人間の役割は考えること、というか、演出することです」とコメントしている。
「逆転裁判」を使ったこの革新的なベンチマークは、AIモデルが単純なパターン認識を超えて、複雑な状況で推論し、戦略的に行動する能力をどれだけ身につけているかを評価する新たな方法を提示している。人間のような「ひらめき」や「満足感」を得るAIはまだ存在しないが、5年後の2030年にはAIモデルがこのゲームをクリアできるようになるかどうか、その進化を見守ることは興味深いだろう。
Source
- Huggin Face: Game Arena: Gaming Agent


