
GoogleのQuantum AIチームが、量子コンピューティングにおいて新たなマイルストーンを打ち立てた。68量子ビットの超伝導量子プロセッサを用い、古典コンピュータでは到達不可能な領域で、データを「学習」し、新たなデータを「生成」する能力、すなわち「生成的量子優位性(generative quantum advantage)」を世界で初めて実験的に証明したのだ。これは単なる計算速度の向上に留まらず、「創造」の領域に量子コンピュータが踏み込んだことを意味し、科学から産業まで、あらゆる分野の未来図を塗り替える可能性を秘めた成果と言えるだろう。
量子コンピュータの新たな地平:「計算」から「学習と創造」へ
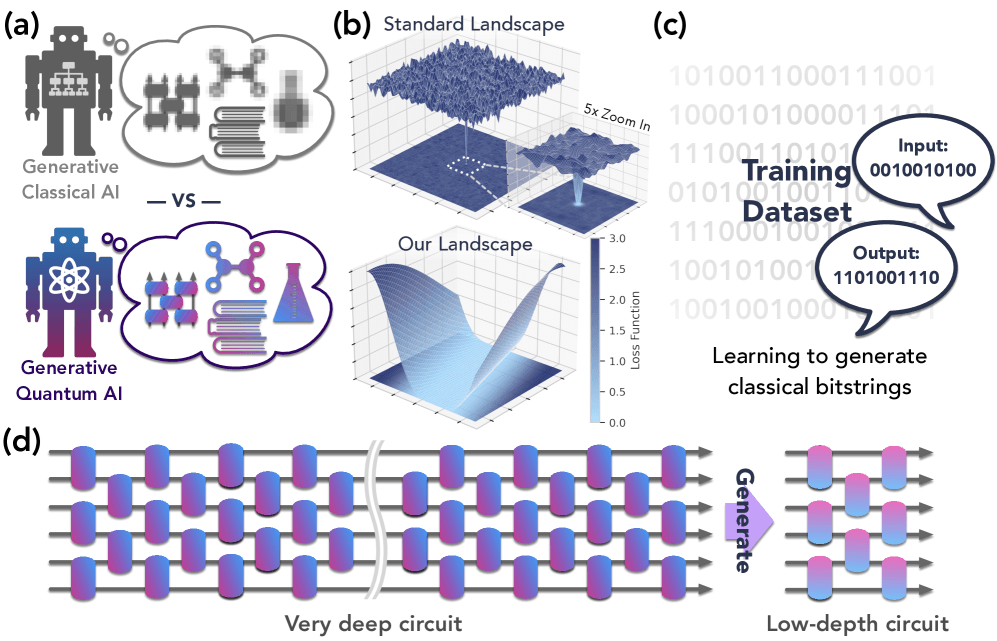
これまで「量子優位性(quantum advantage)」あるいは「量子超越性(quantum supremacy)」という言葉は、特定の計算問題を、世界最速のスーパーコンピュータですら現実的な時間では解けない速度で量子コンピュータが解き明かす、という文脈で語られてきた。2019年にGoogleが発表した「ランダム回路サンプリング」における成果は、量子コンピュータが古典コンピュータとは異なる原理で動作する、その潜在能力の片鱗を見せつけた記念碑的な成果だった。
しかし、この成果には一つの限界があった。それは、生成される出力がランダムな乱数列に近く、それ自体に直接的な「意味」や「有用性」を見出すのが困難だった点だ。たとえるなら、極めて複雑なサイコロを振ることはできても、そのサイコロを使って特定のゲームに勝つ戦略を「学習」することはできなかったのである。このため、これまでの量子優位性の実証は、量子コンピュータの能力を示す「デモンストレーション」の域を出ない、という見方も存在した。
今回、Hsin-Yuan Huang氏、Michael Broughton氏、Hartmut Neven氏、Ryan Babbush氏、Jarrod McClean氏らを中心とするGoogle Quantum AIの研究チームが、プレプリントサーバーarXivで公開した論文は、この状況を大きく変える物だ。 彼らは、量子コンピュータが単に複雑なパターンを「出力」するだけでなく、データからその背後にある複雑な確率分布を「学習」し、その学習に基づいて新たな、かつ古典的には生成不可能なサンプルを「創造」できることを実験的に示したのである。
これは、「計算機」としての量子コンピュータから、「学習機械」ひいては「創造機械」としての量子コンピュータへと、そのあり方が大きく変わる、まさに革命的な出来事だ。
「生成的量子優位性」とは何か?量子版ChatGPTへの道筋
「生成的(Generative)」という言葉に、多くの人はChatGPTに代表される大規模言語モデル(LLM)や、画像生成AIを思い浮かべるだろう。これらの生成AIは、膨大なテキストや画像データを学習し、その中に潜むパターンや文法、構造を捉えることで、人間が書いたような自然な文章や、写実的な画像を新たに生成する。
今回の研究が示す「生成的量子優位性」は、このプロセスを量子力学の世界で実現するものと捉えることができる。古典コンピュータ上で動作する生成AIが、インターネット上の膨大な、しかし有限のデータセットから学習するのに対し、量子生成モデルは、量子力学が支配する、天文学的な広さを持つ可能性の空間から学習する。
研究チームが定義する「生成的量子優位性」とは、以下の二つの要素を兼ね備えた状態を指す。
- 効率的な学習能力: 古典データ、あるいは量子データから、その背後にある複雑な確率分布を効率的に学習できる。
- 古典的に困難な生成能力: 学習したモデルから新しいサンプルを生成(サンプリング)する際、そのプロセスが古典コンピュータでは効率的に実行不可能である。
つまり、学習は効率的に行えるが、一度学習したモデルから何かを創り出す段になると、量子コンピュータでなければ不可能、という状況だ。これは、古典的な生成AIがしばしば学習はできても高品質なサンプルの生成に苦労するのとは対照的である。量子ハードウェアの特性そのものを、生成プロセスにおけるボトルネックの解消に利用しているのだ。
この能力がもたらす可能性は計り知れない。例えば、古典コンピュータではシミュレーションが困難な新しい分子構造や材料の特性を学習し、これまで誰も思いつかなかったような新薬の候補や、革新的な機能を持つ新素材の設計図を「生成」する。あるいは、複雑な金融市場の動きを学習し、古典モデルでは予測不可能なリスクを検知する。まさに、人類の知性がこれまで到達できなかった問題領域への扉を開く鍵となる可能性を秘めている。
68量子ビットが拓いた実験的証拠:Googleの挑戦の核心
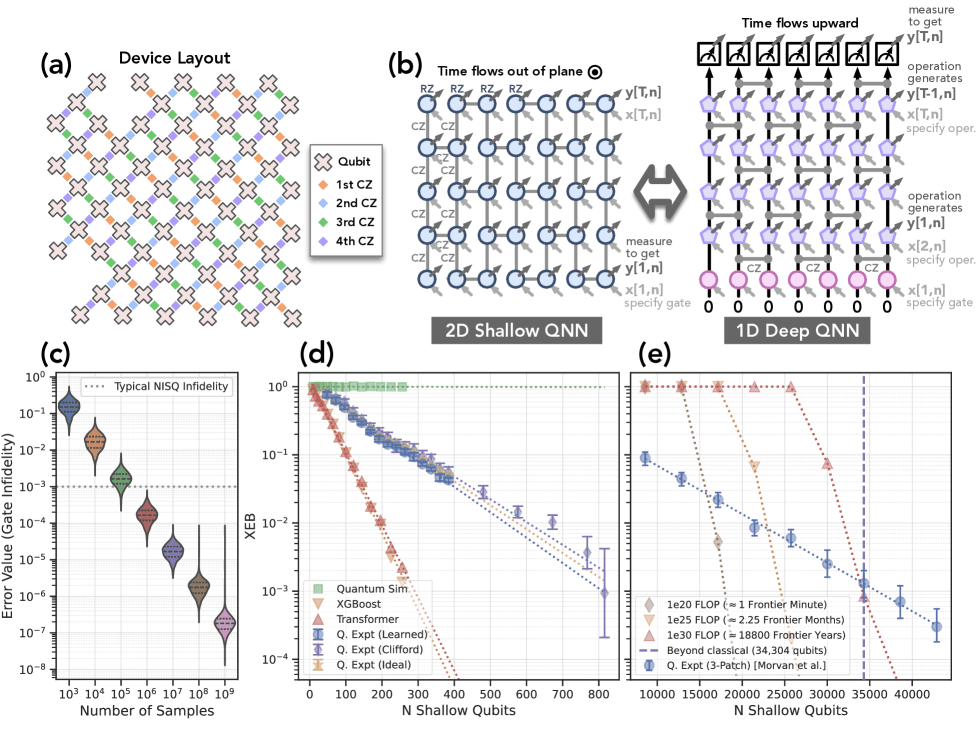
理論上の可能性だけではない。Googleチームは、自社開発の68量子ビット超伝導量子プロセッサを用いて、この生成的量子優位性を具体的に実証してみせた。実験は、主に以下の3つのタスクに焦点を当てて行われた。
1. 古典的に再現不可能なビット列の生成
最初のタスクは、古典的なコンピュータモデルではシステムサイズ(問題の規模)が大きくなるにつれて再現が不可能になる、極めて複雑な確率分布に従う「ビット列」(0と1の羅列)を生成することだった。
これは、古典AIと量子モデルに同じ学習データを与え、未知の入力に対してどれだけ正確な出力を生成できるかを競わせるものだ。結果は明白だった。小規模なシステムでは古典モデルも健闘するが、規模が大きくなるにつれてその性能は急速に低下。一方で、量子モデルはノイズの存在する現実のハードウェア上でも、古典モデルを大幅に上回る性能を維持し続けた。この研究では、68物理量子ビットを用いた実験結果から、最大で34,000を超える量子ビットに相当するシステムのシミュレーションまで性能を推定しており、古典コンピュータの能力を遥かに超える領域での優位性を示している。
2. 量子回路の圧縮
二つ目のタスクは、より実用的な応用に近い。研究チームは、量子モデルを訓練して、深く複雑な量子回路(計算コストが高い)を、それと等価な浅い回路(計算コストが低い)に「圧縮」させることに成功した。
これは、物理システムのシミュレーションにおいて絶大な効果を発揮する可能性がある。例えば、新薬開発のための分子シミュレーションや、新素材開発のための物性シミュレーションでは、膨大な計算を必要とする量子回路が用いられる。この回路をより浅く、つまりより効率的にできれば、シミュレーション速度は劇的に向上する。
興味深いのは、このような効率的な回路表現を見つけ出すこと自体が、古典コンピュータにとっては非常に困難な問題であるという点だ。論文では、ある回路がより単純な形で表現できると約束されていても、その表現を古典コンピュータで見つけ出すのは効率的ではないことが理論的に示されている。 つまり、量子コンピュータは、自らの計算を効率化するための「最適なアルゴリズム」そのものを学習し、生成できる可能性を示したのである。
3. 量子状態そのものの学習
三つ目のタスクは、システムの局所的な部分を測定したデータだけをもとに、システム全体の未知の量子状態を効率的に学習し、生成する能力を実証した。
これは、全体像が不明な複雑な量子システムを理解する上で極めて重要だ。例えば、量子センサーから得られる断片的なデータから、観測対象の全体像を再構築するような応用が考えられる。この実験は、限られた情報から全体を推測するという、高度な学習能力を量子モデルが備えていることを裏付けるものだ。
成功の鍵を握る革新的な技術
この歴史的な成果は、いくつかの巧妙な理論的・技術的ブレークスルーによって支えられている。
「縫合技術(Sewing Technique)」:分割して統治せよ
量子機械学習の分野では、システムの規模が大きくなると学習が全く進まなくなる「不毛な台地(Barren Plateaus)」や、最適解ではない解に囚われてしまう「局所的最適解の増殖」といった深刻な問題が知られている。これらは、巨大で複雑な問題を一度に解こうとすることに起因する。
Googleの研究チームは、この問題を回避するために「縫合技術(Sewing Technique)」と呼ばれる分割統治戦略を採用した。 これは、巨大な問題を一度に解くのではなく、管理可能な小さなブロックに分割し、それぞれを個別に学習させた後、それらを巧みに「縫い合わせる」ことで全体の解を再構成するというアプローチだ。
まるで巨大なジグソーパズルを解く際に、まず空や森といったブロックごとにピースを組み立て、最後にそれらを結合させるのに似ている。この手法により、学習プロセスにおける罠を劇的に減らし、効率的な学習が可能になったことが理論的にも実験的にも示された。
「瞬時に深い(IDQNNs)」モデル:浅い回路で深い世界を描く
実験では、「瞬時に深い量子ニューラルネットワーク(Instantaneously Deep Quantum Neural Networks, IDQNNs)」と呼ばれる新しいモデルファミリーが用いられた。
これは、物理的には浅い(定数深さの)量子回路でありながら、測定と古典的なフィードバックを巧みに利用することで、遥かに深い量子回路の振る舞いを効果的にシミュレートできるという驚くべき特性を持つ。 このモデルのおかげで、現在の技術レベルで実現可能なハードウェアを使いながら、古典シミュレーションが不可能な、遥かに大規模で複雑なシステムの生成タスクを実証することが可能になった。
量子と古典のハイブリッドモデル(VQGANs)
この研究の背景には、「変分量子生成的敵対ネットワーク(Variational Quantum Generative Adversarial Networks, VQGANs)」という、量子と古典のハイブリッドアプローチの活用がある。
これは、量子回路をサンプルを生成する「生成器(Generator)」、古典的なニューラルネットワークをそのサンプルが本物か偽物かを見分ける「識別器(Discriminator)」として用い、両者を競わせることで学習を進めるという枠組みだ。生成器はより本物らしいサンプルを作ろうと学習し、識別器はより正確に見分けようと学習する。この敵対的なプロセスを通じて、量子生成器は目標とする複雑なデータ分布を生成する能力を精錬していく。これは、現在の量子技術と成熟した古典AI技術の長所を組み合わせた、非常に現実的かつ強力な手法と言えるだろう。
3万4000量子ビット超への展望:スケーリングが示す未来
今回の実験は68量子ビットで行われたが、研究の真価はそのスケーラビリティにある。研究チームは、IDQNNsが持つ特殊な構造(浅い回路と深い回路の数学的な等価性)を利用し、既存のより大規模な量子優位性の実験結果と自分たちのモデルをマッピングした。
その結果、彼らの手法は、実効的に「浅い」量子ビットのシステムに相当する性能を実証し、さらに他の研究データを組み合わせることで、実に34,304量子ビット規模のシステムにまで性能を推定できることを示した。この規模は、現在および予見可能な未来のいかなる古典スーパーコンピュータでもシミュレーションが不可能な、まさに「未知の領域」である。
重要なのは、この「向こう側」の領域において、学習が依然として効率的であることを示した点だ。論文中の分析によれば、現在のノイズレベルの量子コンピュータであっても、わずか100万回のサンプリング(数秒の実行時間に相当)で、古典計算では18,000年以上かかると見積もられるタスクと同等の精度で学習が可能であると結論付けている。これは、生成的量子優位性が、遠い未来の夢物語ではなく、現在のハードウェアの延長線上で到達可能な、具体的な目標であることを力強く示している。
実用化への道のり
この画期的な成果をもってしても、量子生成モデルが我々の生活をすぐに変えるわけではない。実用化に向けては、まだいくつかの重要なハードルが残されている。
現実世界への応用という「最後のピース」
最大の課題は、この量子生成モデルが他に類を見ない価値を提供するような、「現実世界のデータ分布」を見つけ出すことだ。 今回の研究は、量子モデルが「訓練可能」であり、「古典的に困難なタスクを実行できる」ことを証明したが、その能力が真に活かされる具体的な問題―例えば、特定の分子構造のデータセットや金融データなど―はまだ特定されていない。いわば、非常に高性能な鍵を作る技術は手に入れたが、その鍵で開くべき宝箱がまだ見つかっていない状態だ。
ハードウェアとアルゴリズム、両輪の進化
もちろん、ハードウェアの継続的な進化も不可欠だ。量子ビットの数を増やし、計算エラー率をさらに低減させていく必要がある。同時に、今回提案されたIDQNNsや縫合技術のようなアルゴリズム側の革新も、量子コンピュータの真の力を引き出すためには欠かせない。研究者たちは、浮動小数点数のような、より実用的なデータ形式を扱えるモデルの開発や、量子センシング技術との融合などを今後の重要な研究方向として挙げている。
AIと量子コンピューティングが交差する未来
今回のGoogle Quantum AIによる研究は、量子コンピューティングが新たな時代に突入したことを明確に示した。それは、単に古典コンピュータの計算を高速化する「アクセラレータ」としての役割に留まらず、AIと融合し、これまで人類が扱えなかった種類の複雑さを「学習」し、新たな知を「創造」するパートナーとなりうる未来だ。
古典的な機械学習の歴史がそうであったように、最終的な勝利は理論的な保証よりも、現実のデータに対する実証的な成功によってもたらされるかもしれない。この研究は、そのための強固な理論的・実験的基盤を築き、量子コンピュータがAIの発展にどのように貢献できるかという長年の問いに、一つの力強い答えを提示した。我々は今、計算と知能の概念そのものが、量子力学の法則によって再定義されようとする瞬間に立ち会っているのかもしれない。
論文
参考文献
- Quantum Insider: Generative AI Meets Quantum Advantage in Google’s Latest Study


