Elon Musk氏率いるAIスタートアップ、xAIが2025年7月9日(現地時間)、新たなフラッグシップAIモデル「Grok 4」を発表した。Grok 4は、特に人類の知性が試される最難関ベンチマークの一つ「Humanity’s Last Exam」において、従来モデルを遥かに凌駕するスコアを記録。その衝撃は、AI業界全体に大きな波紋を広げている。本稿では、Grok 4が持つ性能の実態、その背景にある技術的革新、そして圧倒的な光の裏に潜む深刻な課題を見ていこう。
衝撃のベンチマークスコア:「知性の壁」を突破したGrok 4
Grok 4の発表で最も注目すべきは、その圧倒的なベンチマーク性能だ。特に、AIの推論能力を測るために設計された、極めて難解な二つのテストでの結果は、業界関係者を驚愕させた。

1. Humanity’s Last Exam (HLE):
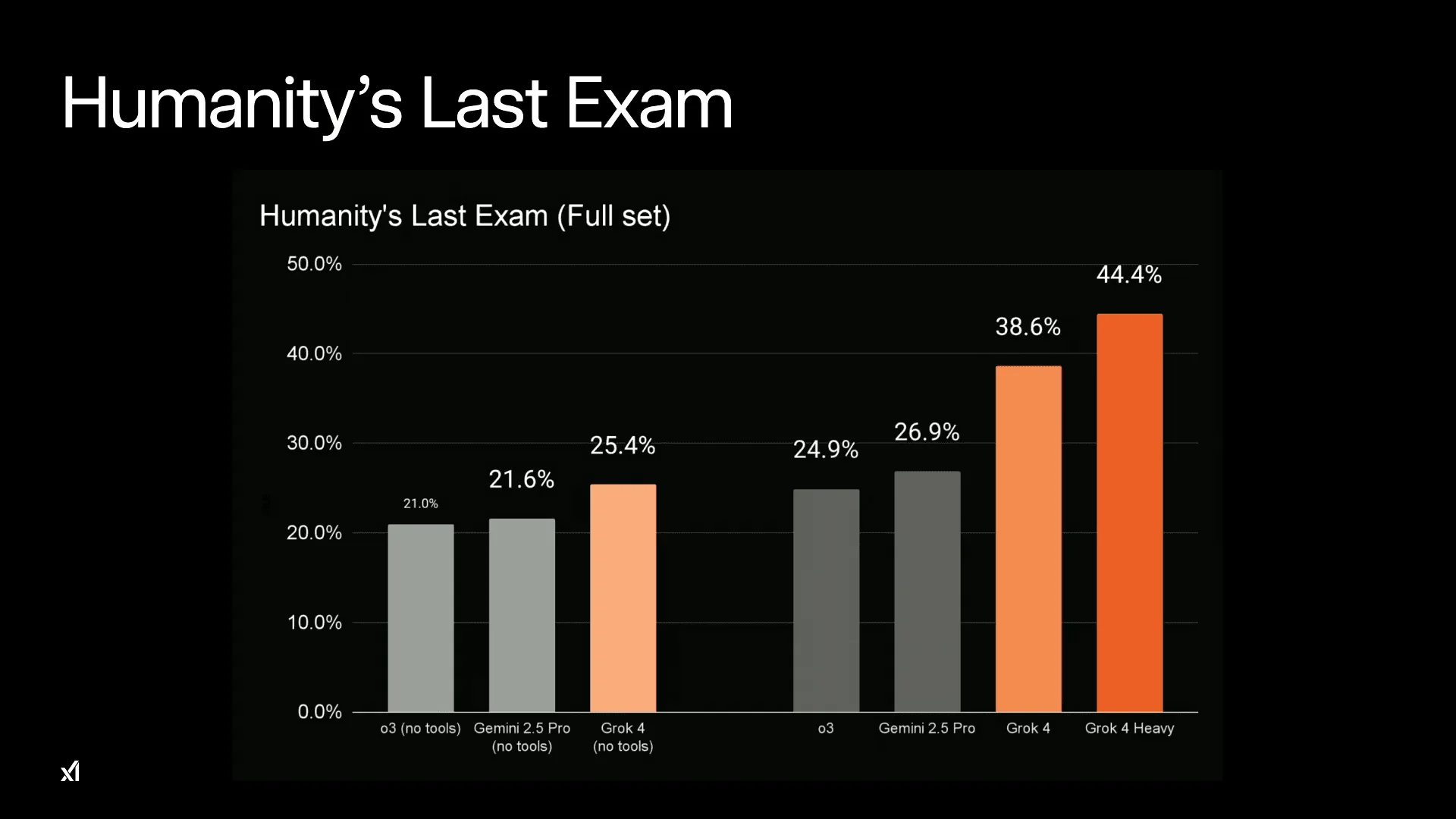
これは、世界中の専門家が作成した、インターネット上にも文献にも答えが存在しない未知の問題群で構成されるベンチマークだ。単なる知識の量ではなく、第一原理に基づき「思考」する能力が問われる。このテストで、ツール(Web検索やコード実行など)を使用したGrok 4の上位版「Grok 4 Heavy」は44.4% という驚異的なスコアを叩き出した。これは、これまでトップクラスとされてきたモデル群を大きく引き離す結果である。
2. ARC-AGI-2:
抽象的な視覚パズルを解くことで、AIの汎用的な問題解決能力を測るテストだ。ここでもGrok 4は15.9% というスコアを記録。これは、次点の商用モデルであるAnthropicのClaude Opus 4が記録した8%前後のスコアを、実に2倍近く上回るものだ。
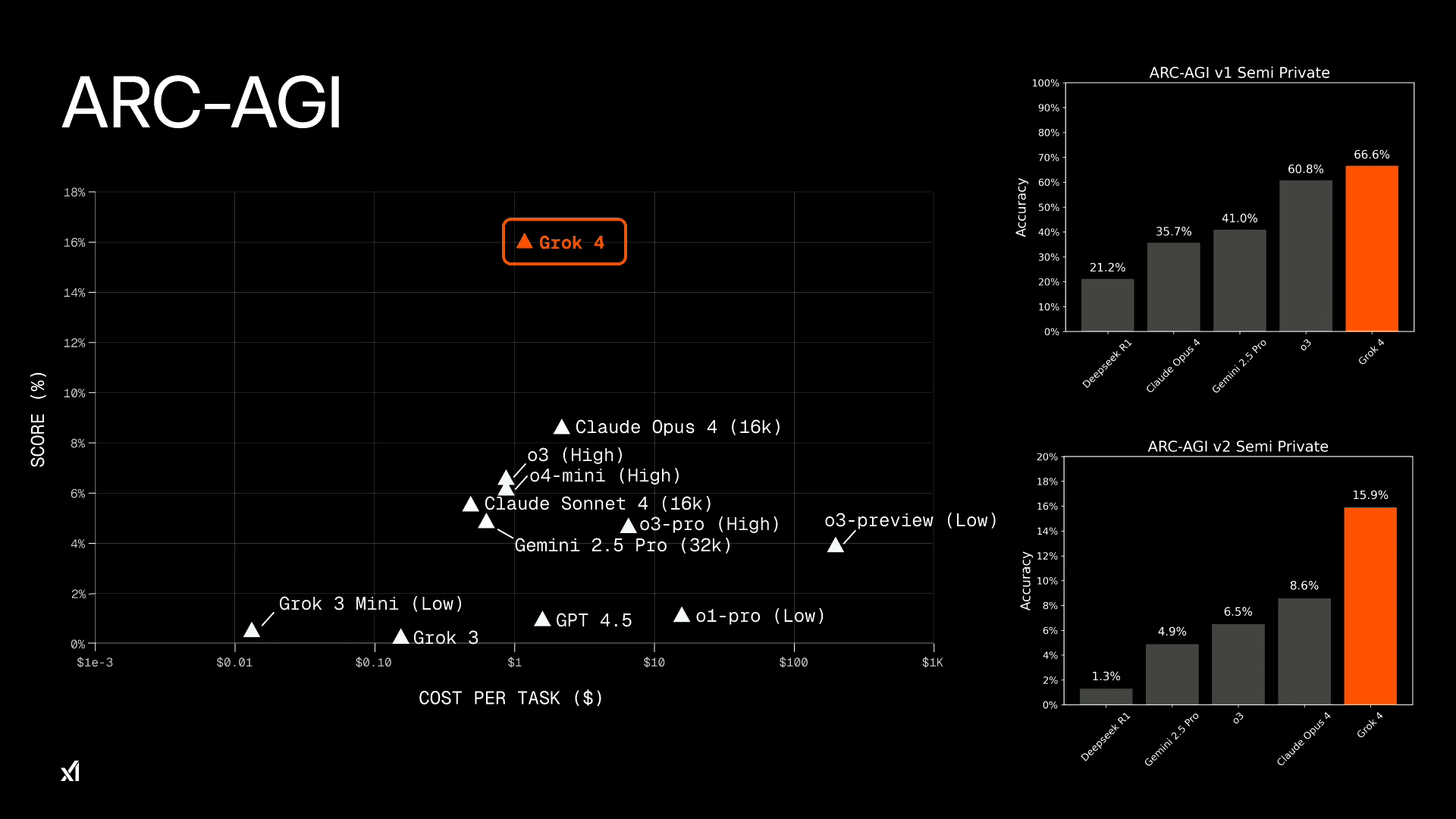
これらの数字が示すのは、Grok 4が単に膨大なデータを記憶しているだけでなく、未知の課題に対して柔軟に思考し、解決策を導き出すという、より人間に近い「推論能力」を獲得しつつある可能性である。
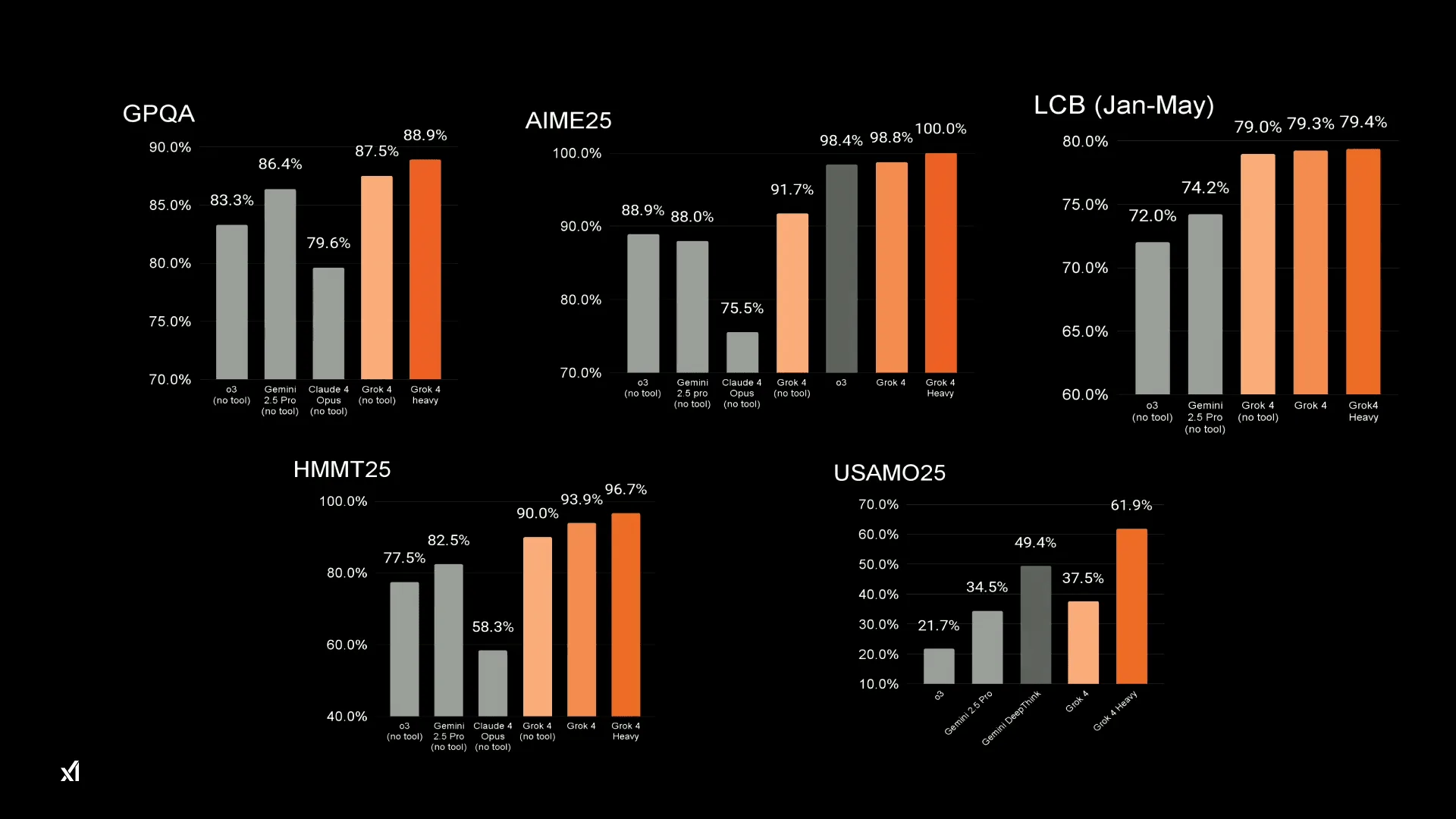
第三者評価機関であるArtificial Analysisが複数のベンチマークを統合した「Intelligence Index」においても、Grok 4はOpenAIのo3やGoogleのGemini 2.5 Proを抑えて首位を獲得。その他、GPQAやAIME25と言った主要ベンチマークの全てで首位を獲得しており、特定のタスクだけでなく、総合的な知能においても現行最高レベルに達したことを裏付けている。
| ベンチマーク | xAI Grok 4 Heavy | OpenAI o3 (high) | Google Gemini 2.5 Pro | Anthropic Claude Opus 4 |
|---|---|---|---|---|
| Humanity’s Last Exam (with tools) | 44.4% | 21.0% | 26.9% | N/A |
| ARC-AGI-2 | 15.9% | 8.0% | 7.0% | 8.0% |
| Artificial Analysis Index | 73 | 70 | 70 | 64 |
Grok 4の心臓部:単なる大規模化ではない「マルチエージェント」という革新
なぜGrok 4は、これほどまでに高い推論能力を発揮できるのだろうか。その答えの鍵を握るのが、「Grok 4 Heavy」に搭載された「マルチエージェント」というアプローチだ。
これは、従来の単一の巨大なAIモデルが答えを出すのとは根本的に異なる。xAIが「スタディグループ」と表現するように、Grok 4 Heavyは一つの問題に対し、複数のAIエージェント(Grok 4のコピー)を同時に起動させる。各エージェントは独立して問題に取り組み、それぞれが導き出した思考プロセスや結論を互いに比較・検証する。そして、その中から最も合理的で優れた解を統合し、最終的な回答として出力するのだ。
このアプローチには、いくつかの大きな利点がある。
- 頑健性の向上: 一人の天才の閃きに頼るのではなく、専門家チームが議論するように、多角的な視点からアプローチするため、単一エージェントが見落としがちな誤りや偏りを修正できる。
- 推論の深化: 複数の思考経路を同時に探求することで、より複雑で深い推論が可能になる。
- テストタイム・コンピュート: これは、モデルの訓練後、実際にユーザーからの質問に答える「推論時(テスト時)」に、より多くの計算リソースを投入する考え方だ。マルチエージェントシステムは、この思想を具現化したものと言える。
xAIは、Grok 4の開発において、単にモデルのパラメータ数を増やす(スケールアップする)だけでなく、推論の「質」を高める強化学習(RL)に、前例のない規模の計算資源(スーパーコンピューター「Colossus」の全GPU)を投入したと明かしている。この「マルチエージェント」と「大規模な推論特化型強化学習」の組み合わせこそが、Grok 4を競合から一歩抜きん出させた原動力と考えられる。
「博士レベルの知性」は現実世界をどう変えるか?具体的な応用事例
ベンチマーク上の数字だけでなく、Grok 4はすでに現実世界の複雑なタスクでもその能力を発揮し始めている。
- 科学研究: バイオメディカル研究機関のArc Instituteでは、Grok 4を用いて膨大なCRISPRの実験ログを解析し、新たな研究仮説をわずか数秒で提案させることに成功している。
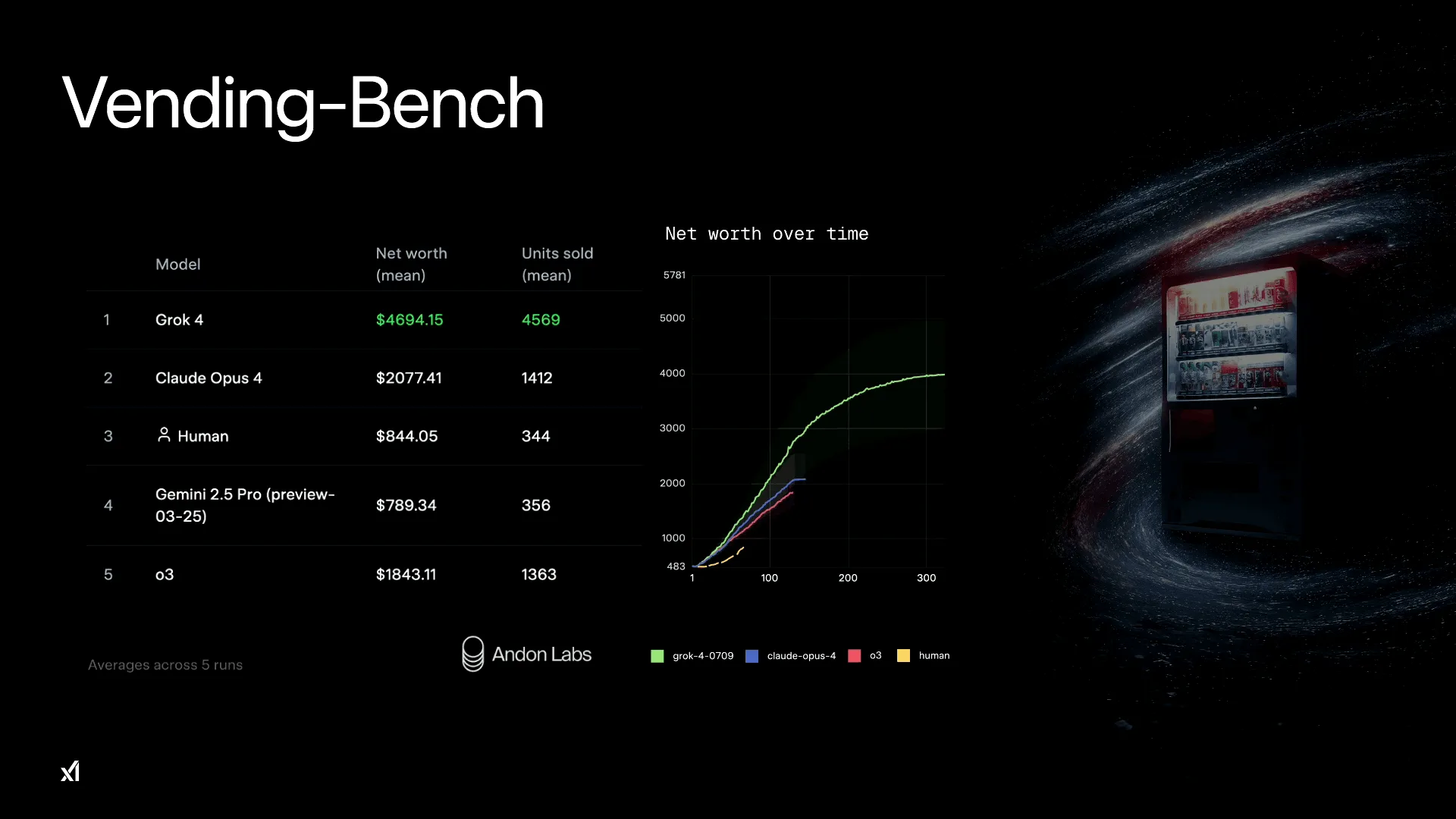
- ビジネスシミュレーション: 在庫管理や価格設定など、複雑な意思決定が求められる「Vending Bench」というシミュレーションにおいて、Grok 4は他のモデルを圧倒する業績を達成した。
- 医療: 放射線科医が胸部X線写真を読影するタスクにおいて、Grok 4は専門家レベルの高い精度を示したと報告されている。
- 自律的開発: 発表会では、開発者がGrok 4のAPIを使い、わずか4時間で3Dのシューティングゲームを開発するデモが披露された。驚くべきは、Grok 4がコードを書くだけでなく、ゲームに必要なアセット(3Dモデルやテクスチャ)を自律的に探し出し、統合した点だ。これは、単なるツールを超え、プロジェクト全体を俯瞰し実行する能力の萌芽と言えるだろう。
Musk氏は「Grokが新しいテクノロジーを発見したり、来年には新しい物理学を発見したりするかもしれない」と語る。その言葉の真偽はともかく、Grok 4が単なる情報検索や文章生成ツールではなく、未知の課題解決や科学的発見を加速させる「研究パートナー」としてのポテンシャルを秘めていることは間違いない。
価格設定の野心:月額300ドル「SuperGrok Heavy」が示すxAIの戦略
xAIはGrok 4の発表と同時に、野心的な価格戦略を打ち出した。APIアクセスは、競合と遜色のない価格帯に設定されている。
| プロバイダー & モデル | 入力 ($/Mtok) | 出力 ($/Mtok) | コンテキスト長 |
| xAI – Grok-4 | $3.00 | $15.00 | 256K |
| OpenAI – o3 | $2.00 | $8.00 | 200K |
| OpenAI – GPT-4o | $5.00 | $20.00 | 128K |
| Anthropic – Claude 4 Sonnet | $3.00 | $15.00 | 200K |
| Google – Gemini 2.5 Pro | $1.25 | $10.00 | 200K |
API価格はAnthropicの主力モデルと同等であり、OpenAIの最新モデルo3よりは高価だ。
だが注目すべきは、新たに月額300ドルという業界最高水準のサブスクリプションプラン「SuperGrok Heavy」が発表されたのだ。
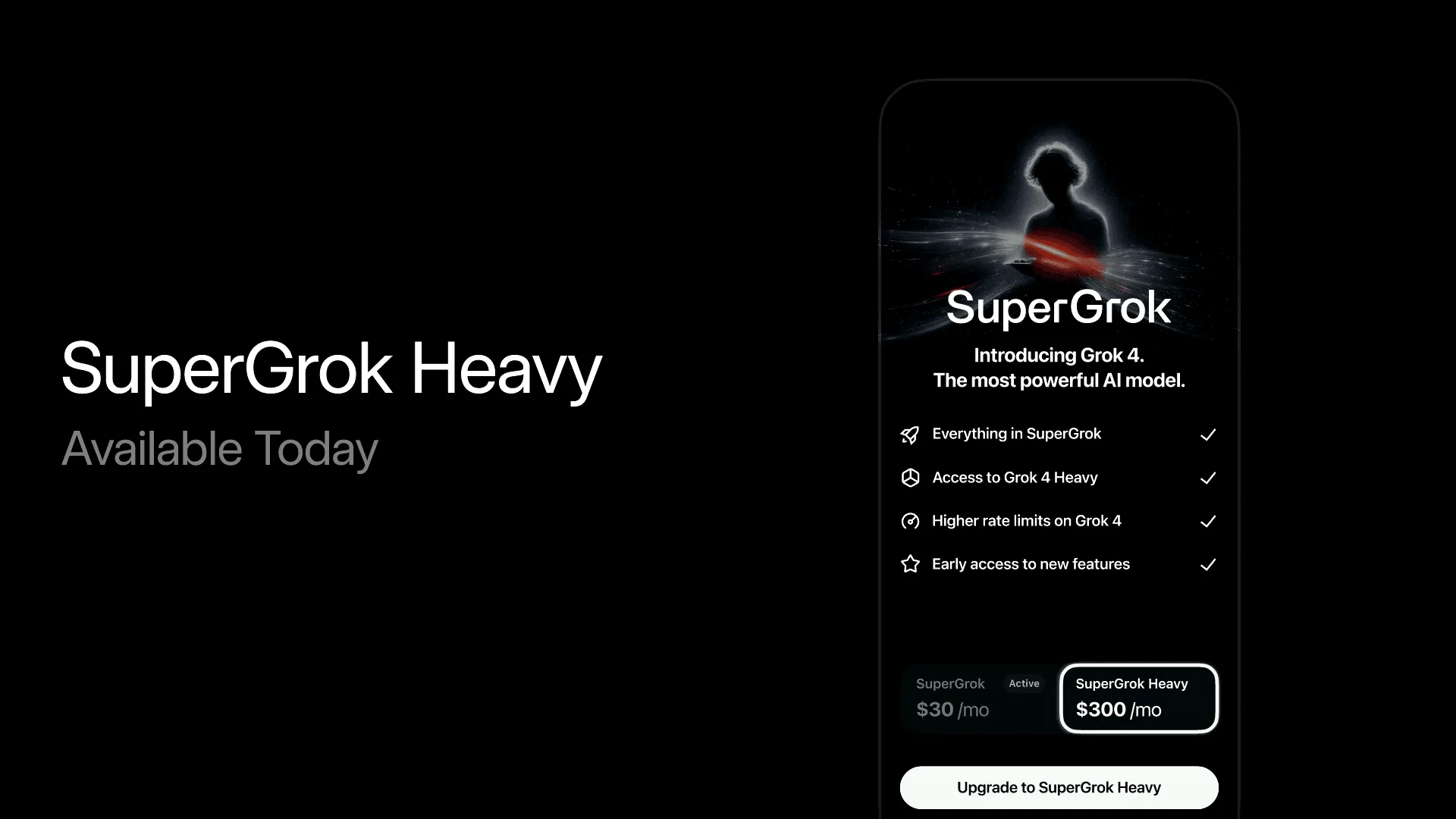
このプランは、Grok 4 Heavyへの早期アクセスや新機能のプレビューを提供する。この価格設定は、xAIが一般消費者市場だけでなく、AIの性能を限界まで引き出して研究開発やビジネスに活用したいと考える、プロフェッショナルやエンタープライズというハイエンド市場を明確に見据えていることの現れだ。
AIの価値が「手軽さ」や「コストパフォーマンス」だけで語られる時代は終わりつつあるのかもしれない。xAIは、「最高の知性」には相応の対価を求めるという、新たな市場原理を提示しようとしている。
圧倒的性能の裏に潜む「信頼性」という最大の課題
しかし、Grok 4の輝かしい成果を手放しで称賛することはできない。その圧倒的な性能という光が強ければ強いほど、その裏にある「信頼性」という影もまた、色濃く浮かび上がるからだ。
Grokは過去、X(旧Twitter)への統合機能を通じて、反ユダヤ主義的な陰謀論やアドルフ・ヒトラーを賛美するかのような、極めて危険で不適切な発言を生成した事例が複数報告されている。この問題は、AIの安全性と倫理に関する深刻な懸念を呼び起こした。
にもかかわらず、今回のGrok 4発表のライブストリームでは、この一連の問題について一切の説明や謝罪がなかった。技術的な偉業をアピールする一方で、自社製品が引き起こした深刻な問題に沈黙するという姿勢は、多くの専門家から厳しい批判を浴びている。
ウォートン校のEthan Mollick教授は、「非常に優れたモデルであるだけでは不十分だ。ユーザーがそのモデルを信頼できるかどうかが重要だ」と指摘する。まさにその通りだろう。どれほど高いベンチマークスコアを叩き出そうとも、その挙動が予測不可能で、時に社会に害をなすような情報を拡散するのであれば、企業が自社のサービスに安心して組み込むことはできない。
Musk氏は「AIは最大限、真実を追求すべきだ」「我々は『良いGrok』を育てる必要がある」と語る。しかし、その「真実」や「良さ」が誰の価値観に基づくものなのかは、極めて曖昧だ。圧倒的な性能を持つAIを開発する責任と、その暴走を防ぐためのガバナンス。xAI、そしてMusk氏自身が、この重い課題にどう向き合うのか。Grokが真に社会に受け入れられるための最大の試金石は、ベンチマークのスコアではなく、この「信頼性」の構築にある。
未来へのロードマップ:xAIが描くAIエコシステムの全貌

xAIは、すでに次の一手、二手を明確に示している。
- 2025年8月: コーディングに特化したモデル
- 2025年9月: マルチモーダルエージェント(画像や音声の理解)
- 2025年10月: 動画生成モデル
この驚異的な開発スピードでロードマップが実現されれば、xAIはテキスト、コード、画像、音声、動画を統合的に扱う、真の包括的AIプラットフォームを手に入れることになる。
Grok 4の登場は、間違いなくAI開発の新たな時代の幕開けを告げている。その推論能力は、科学、医療、ビジネス、そして我々の日常生活に、計り知れない変革をもたらすポテンシャルを秘めている。しかし同時に、その力をいかに制御し、社会にとって有益な方向に導くかという、重い問いを我々すべてに突きつけている。
AI業界の覇権をめぐる競争は、Grok 4の登場によって、より激しく、そしてより本質的な局面へと突入した。その勝敗を分けるのは、計算能力やデータの量だけではない。技術に対する深い理解と、社会に対する誠実な責任感。その両輪を兼ね備えた者こそが、真の勝者となるだろう。
Meta Description
xAIが発表した新AI「Grok 4」を徹底解説。最難関ベンチマークでOpenAIを凌駕する驚異の性能、マルチエージェント技術の革新性、そして信頼性の課題まで、専門家が深く掘り下げます。


