
現在の人工知能(AI)コンピューティングの生態系において、NVIDIAのGPU(グラフィックス・プロセッシング・ユニット)と、SK hynixを筆頭とするHBM(高帯域幅メモリ)の組み合わせは、事実上の業界標準として君臨している。この強固な同盟は、生成AIブームという未曾有の技術的波涛を捉え、世界の半導体市場の勢力図を完全に塗り替えた。だが、AIモデルの規模が指数関数的に肥大化する中、この第一幕の支配体制は早くも技術的な限界、「メモリの壁」という深刻な構造的課題に直面している。
最先端の超巨大AIモデルが直面している真のボトルネックは、もはやプロセッサの論理演算速度そのものではない。演算素子と記憶素子間を繋ぐ「データの高速道路」の渋滞にある。AIが自律的に計画を立案し、複雑な推論タスクを実行する過程において、消費される電力と時間の80%以上が、単なるデータの移動に浪費されているという衝撃的な事実が、業界内で広く認識され始めている。この構造的欠陥を克服しない限り、AI技術の持続可能な発展は望めない。
こうした危機感を背景に、世界の半導体業界は早くもHBM陣営の次を見据えた「第2幕」の戦争へと突入している。コンピューティングのパラダイムそのものを根底から覆す可能性を秘めた、5つの革新的な次世代メモリアーキテクチャの全貌を見てみよう。
コンピューティングアーキテクチャの根本的変革を牽引する5つのアプローチ

PIM(Processing in Memory):受動的な記憶庫から「思考するメモリ」への進化
現代のノイマン型アーキテクチャにおける最大の弱点は、プロセッサ(工場)とメモリ(倉庫)が物理的に分離されている点にある。データがこの両者間を絶えず往復することで、致命的な遅延(レイテンシ)と膨大な排熱、電力消費が生じている。PIM技術は、この役割分担を破壊する。
具体的には、メモリチップの内部に直接、論理演算回路を組み込む。AI処理の中核を成す行列演算の大部分をメモリ自身が内部で完結させ、その最終的な結果のみをGPUへと送り返す。この自律的な演算基盤の導入により、既存のアーキテクチャと比較してエネルギー効率が数十倍に跳ね上がると専門家は指摘している。すでにSK hynixは、このPIM技術を実装した次世代アクセラレータ「AiM(Accelerator in Memory)」を実際のシステムに導入し始めており、演算効率の劇的な改善を実証している。これは単なるメモリの高速化ではなく、コンピューティングの主体がプロセッサからメモリへと移行する兆しである。
CXL(Compute Express Link):データセンター全体を単一の巨大な頭脳へ

第二の革新は、物理的な搭載容量の制約を打破するCXLベースのメモリ技術である。現在のAIサーバー開発において最も頭を悩ませているのが、GPU1基に対して直接接続できるHBMの容量に物理的な限界があることだ。パラメータ数が兆の単位に達する次世代の大規模言語モデル(LLM)の学習には、数千台のサーバーを強引に数珠繋ぎにせざるを得ず、これが天文学的なインフラコストの元凶となっている。
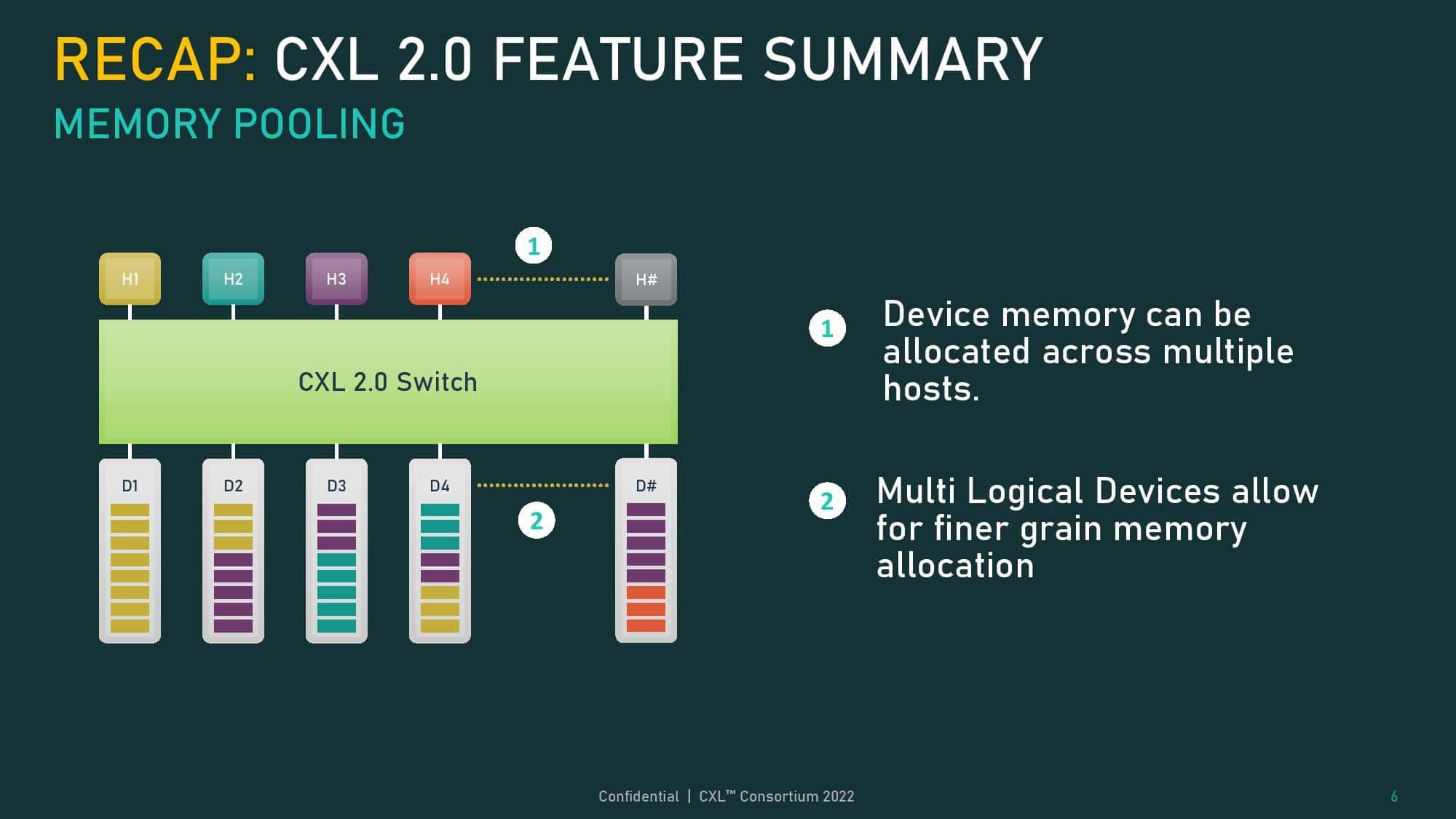
CXLは、この壁を「メモリのプール化」というアプローチで突破する。サーバー間の境界を取り払い、ネットワークを介してそれぞれのメモリを一つの巨大な共有資源(プール)として扱うことを可能にする。これが完全に実用化されれば、巨大なデータセンター全体があたかも単一のスーパーコンピュータであるかのように振る舞う。サーバー個別の容量制限という概念が消滅し、超巨大AIの学習コストを根本的に引き下げる基盤となる。この領域では、Samsung Electronicsが業界初のCXL 2.0 DRAMを開発し、さらにデータセンターの構造自体を変革するCXL 3.0の商用化に向けて莫大な投資を行っている。
MRAM(磁気抵抗メモリ):不揮発性と超低消費電力の融合
次世代非揮発性メモリの最有力候補として開発が進むMRAMは、データを電荷の有無ではなく、電子の磁気的なスピン状態(磁気抵抗効果)を利用して記録する。最大の特徴は、電源を完全に切断してもデータが失われない不揮発性を持ちながら、動作速度は現在のDRAMに匹敵するという点にある。
さらに、その電力消費は極めて微小に抑えられている。この特性は、常に電力を供給し続けなければならない既存の揮発性メモリの弱点を完全に克服するものであり、特に電力供給に厳しい制限があるスマートフォンへの実装(On-Device AI)や、継続的なデータ保持と即応性が生死を分ける自動運転車(Edge AI)の環境下において圧倒的な優位性を持つ。AIアクセラレータ内部のキャッシュメモリをMRAMへと置き換えることで、電力の大半を貪り食う現在のAIチップの体質を抜本的に改善できると期待されている。
ReRAM(抵抗変化型メモリ):人間の脳神経網を模倣するアナログアプローチ
「高集積化の究極形」と称されるReRAMは、特殊な絶縁体への電圧印加による電気抵抗値の変化を利用してデータを記憶する。その物理構造が極めて単純であるため、メモリセルを垂直方向に高密度に積層する(3D化)のに極めて適している。
しかし、真に特筆すべきは、ReRAMがメモリアレイ内部において「アナログ方式」での演算処理を行える点にある。これは、シナプスとニューロンで構成される人間の脳神経網のメカニズムに非常に近い。デジタル回路での厳密な計算(0と1のスイッチング)を必要とせず、物理的な法則(キルヒホッフの法則など)に則って演算を一瞬で完了させるため、ニューラルネットワークの複雑な処理を驚異的な低エネルギーで実行可能にする。次世代超低消費電力AIアクセラレータの中核技術として、現在世界中の研究機関で最も活発に研究が進められている領域である。
SoIC(System on Integrated Chips):NVIDIAとTSMCが描く究極の3D積層
一方、既存の半導体覇権を握るNVIDIAと、その製造を担うTSMCの強力なタッグも、ただ手をこまねいているわけではない。彼らが次世代の絶対的な切り札として開発を進めているのが、SoIC技術だ。
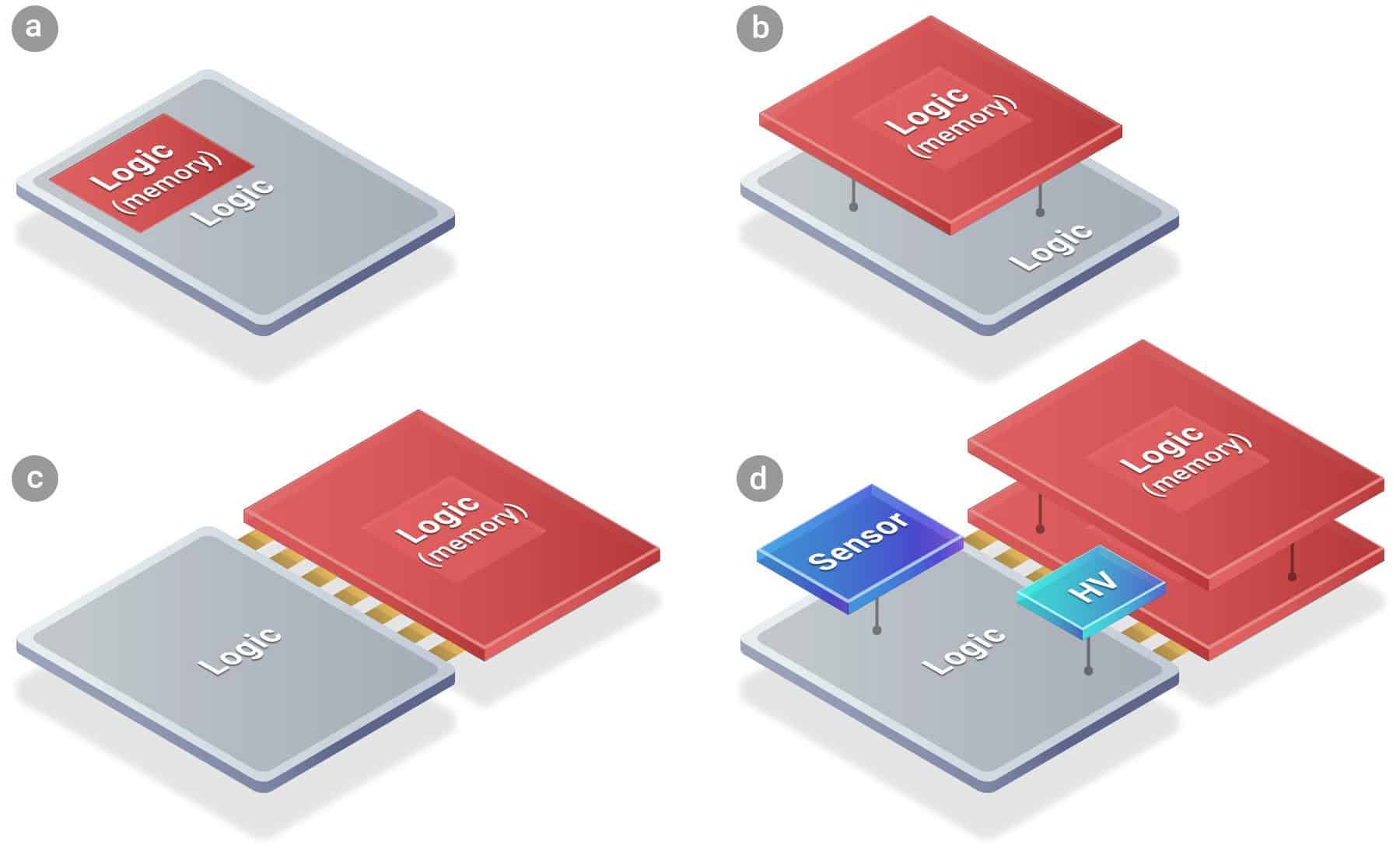
現在のプロセッサとHBMの接続は、インターポーザーと呼ばれる基板上に両者を「水平方向」に並べて配置する2.5Dパッケージングが主流である。これに対しSoICは、演算素子とメモリをチップレベルで「垂直方向」に直接積み重ね、完全に一つの物理的なチップとして統合してしまう3D積層技術を指す。このアプローチにより、データが移動する物理的な距離は従来の数百分の1にまで短縮される。並行して、積層に伴う致命的な熱問題を解決するための高度な冷却機構や貫通電極(TSV)の最適化も図られている。AIアクセラレータとメモリの境界線が完全に消滅するこの構造は、向こう数年間にわたり業界のエコシステムを再度縛り付けるための、NVIDIA陣営の最終防衛線とも言える。
韓国チップメーカー陣営による「ルールメイキング」の逆襲
これら5大革新技術への移行期は、半導体業界のプレイヤーたちにとって、単なる技術力の競争にとどまらない。次世代のデファクトスタンダード(事実上の標準)を誰が握るかという、血みどろのルールメイキング戦争である。
ここで注目すべきは、SamsungやSK hynixといった韓国のメモリメーカーの立ち位置の変化だ。彼らはもはや、プロセッサメーカーの要求仕様に従って部品を納入するだけの従順な「ファストフォロワー」ではない。自らが開発したPIMアーキテクチャやCXL規格をグローバル標準へと押し上げるため、業界コンソーシアムの主導権を積極的に取りに行っている。MRAMやReRAMの基盤特許や初期プロトタイプにおいても両社は圧倒的な存在感を示しており、HBM市場で見せつけた支配力をテコにして、メモリ主導の新しい業界秩序の構築を目論んでいる。
AIコンピューティングの地殻変動:GPU中心主義からの脱却
もはや明確なのは、現在の「GPUが王として君臨し、メモリは単なる巨大な召使いとして控える」という中央集権的なアーキテクチャは、間もなく終焉を迎えるということだ。
データの移動こそが最大のコスト要因となった現在、HBMによる帯域幅の力押しによる拡張は、いずれ物理的・経済的な限界点に達する。代わりに台頭するのは、データをメモリから切り離さず、保管場所で直接演算を行う分散処理的なアプローチである。これらの次世代技術が本格的な商業化フェーズへと移行した瞬間、無敵を誇ったNVIDIAのGPU帝国でさえ、そのソフトウェア・エコシステム(CUDA)の優位性だけで市場を独占し続けることは難しくなる。次なる十年の覇権は、シリコンウェハーをどれだけ微細に彫り込むかではなく、「いかにデータを動かさずに知能を生み出すか」という全く新しい評価軸を制した者が握ることになる。
Sources


