ドイツを拠点とする新進気鋭のAI企業、Black Forest Labs(BFL)が、従来のテキスト指示による画像生成(Text-to-Image)の枠を大きく超えた、画像生成および編集を可能にする新しいAIモデル群「FLUX.1 Kontext」を発表した。このモデルは、既存の画像コンテキストを深く理解し、テキストと画像の両方をプロンプトとして活用することで、驚くほど自然で高精度な画像編集と新規生成を可能にする「インコンテキスト(in-context)」処理を実現する。
Black Forest Labsとは? – XのGrokも支えた実力派AIラボの素顔
Black Forest Labsという名前を初めて耳にする方もいるかもしれない。しかし、このドイツに拠点を置くスタートアップは、すでにAI業界で確かな実績を築きつつある注目企業だ。同社はStability AIの出身者らによって設立され、Elon Musk氏率いるX(旧Twitter)のAIチャットボット「Grok」の画像生成機能も手がけている。
さらに、Andreessen Horowitz(a16z)、Oculus共同創業者のBrendan Iribe氏、Y CombinatorのGarry Tan氏といった著名な投資家からも支援を受けており、2024年末には10億ドルの評価額で1億ドルの資金調達交渉中とも報じられた。このような背景からも、Black Forest Labsが持つ技術力と将来性に対する期待の高さが伺えるだろう。
FLUX.1 Kontext登場の衝撃 – 「インコンテキスト編集」が切り拓く新境地
では、今回発表されたFLUX.1 Kontextは、具体的に何が新しいのだろうか? Black Forest Labsは、「YOUR IMAGES. YOUR WORDS. YOUR WORLD.(あなたの画像。あなたの言葉。あなたの世界。)」というキャッチフレーズを掲げ、その革新性をアピールしている。
従来の多くの画像生成AIは、主にテキストプロンプトに基づいてゼロから画像を生成することに長けていた。既存画像を編集する機能(img2imgやinpaintingなど)も存在したが、例えばinpaintingでは編集箇所と周囲の境界が不自然になったり、img2imgでは元画像のディテールが失われたり、意図しない部分まで変更されてしまうといった課題があった。
FLUX.1 Kontextは、これらの課題に対する一つの答えとして「インコンテキスト画像生成・編集」というアプローチを提示する。これは、テキストだけでなく参照画像(リファレンスイメージ)もプロンプトとして入力でき、AIがその画像の内容や文脈(コンテキスト)を深く理解した上で、テキスト指示に従って極めて自然な編集や要素の追加、変更を行うというものだ。
これは「指示ベースの編集」であり、ユーザーが「何を変更したいか」を具体的に指示するだけで、AIがその部分だけを的確に修正し、他の部分は保持するという、より直感的で外科手術のような精密な編集が可能になったとことを意味する。まさに、ユーザーが思い描く世界を、より忠実に、より簡単にビジュアル化できる時代の到来を予感させる。
FLUX.1 Kontextファミリー徹底解剖 – 用途で選べる3つのモデル
FLUX.1 Kontextは、単一のモデルではなく、用途やニーズに合わせて最適化されたモデル群(スイート)として提供される。現時点では主に「pro」と「max」の2つのAPI提供モデルと、研究者向けの「dev」モデル(現在はプライベートベータ)が存在する。
FLUX.1 Kontext [pro] – 高速かつ反復的な編集のパイオニア
Black Forest Labsが「高速で反復的な画像編集のパイオニア」と位置付けるのが、この[pro]モデルだ。単一のモデルでありながら、以下の主要機能をシームレスに提供する。
- ローカル編集: 画像内の特定領域を狙い通りに編集。
- 生成的インコンテキスト編集: 画像全体のシーンや雰囲気を、文脈を保ちながら大胆に変換。
- 古典的なテキストtoイメージ生成: 高品質な新規画像生成。
特筆すべきは、複数回にわたる編集(マルチターン編集)においても、キャラクターのアイデンティティ、スタイル、際立った特徴などを異なるシーンや視点間で一貫して維持できる点だ。これにより、段階的に画像を洗練させていくクリエイティブプロセスが、かつてないほどスムーズになる。Runwareによる実演では、FLUX.1 Fill[dev]との比較が掲載されているが、指示された部分以外が全く変更されていない点が強調されている。しかも、従来モデルと比較して最大8倍という高速な推論速度を実現しているというから驚きだ(例:GPT-Imageと比較)。
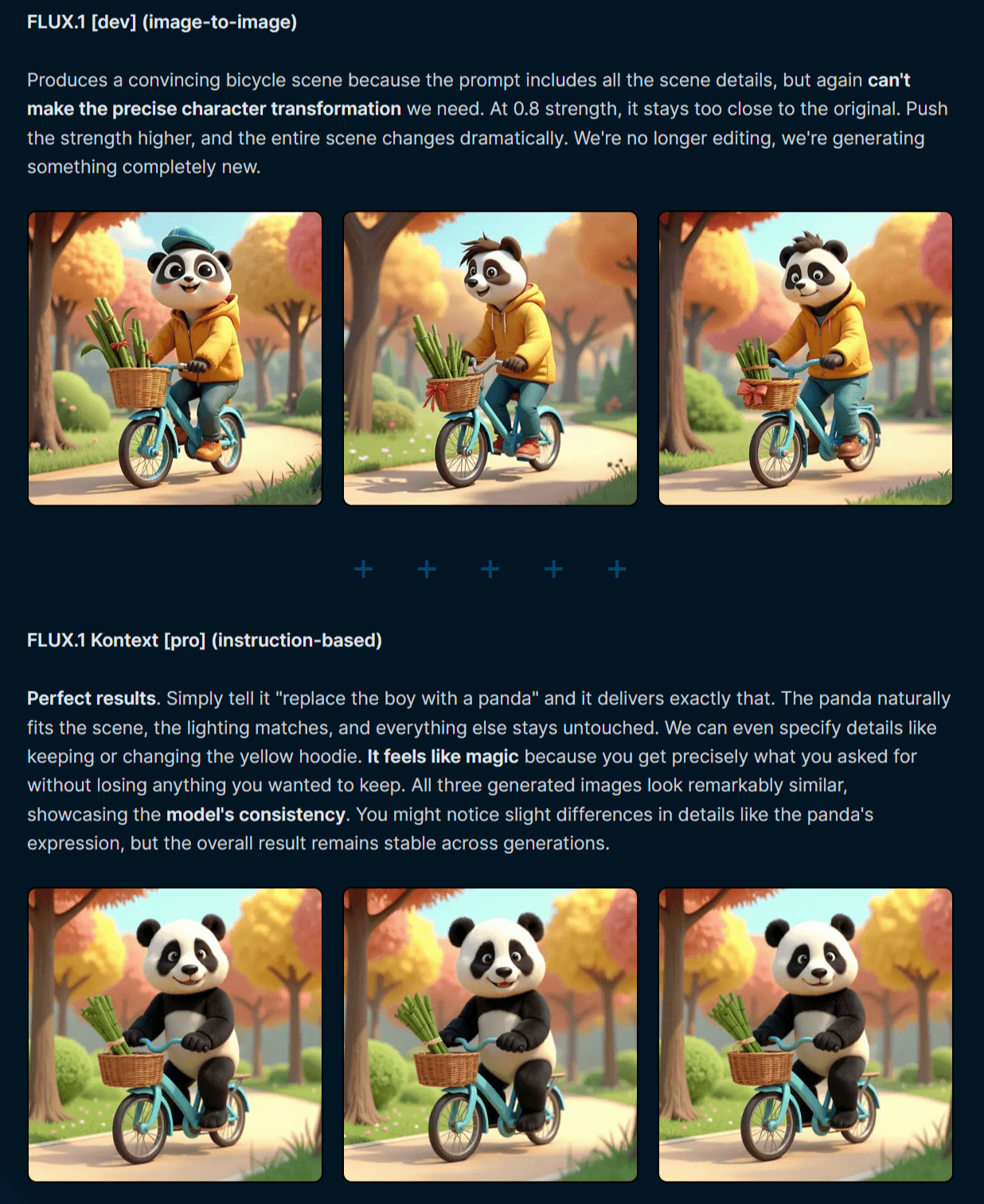
FLUX.1 Kontext [max] – 最高性能をハイスピードで追求する実験的モデル
[max]モデルは、さらなる高みを追求するユーザー向けの実験的な位置づけだ。Black Forest Labsによれば、プロンプトへの忠実度(prompt adherence)やタイポグラフィ(文字表現)の生成品質、そして編集時の一貫性が大幅に向上しているという。それでいて、速度面での妥協はないとのこと。より高度で繊 quinzeな表現を求めるプロフェッショナルにとって、強力な選択肢となるだろう。
FLUX.1 Kontext [dev] – オープンな研究とカスタマイズを促進する開発者版
Black Forest Labsは、「オープンな研究と重みの共有は、安全な技術革新の基礎である」との信念のもと、[dev]モデルを開発した。これは、120億パラメータ(12B)の軽量な拡散トランスフォーマーモデルであり、カスタマイズや研究用途、安全性テストを目的としている。
現在はプライベートベータ版として提供されており、興味のある研究者はBlack Forest Labsにコンタクトを取ることができる。将来的にはパブリックリリースが予定されており、HuggingFaceなどのプラットフォームを通じて配布される見込みだ。このオープンウェイト版の存在は、AIコミュニティによる技術検証や新たな応用研究を加速させ、エコシステム全体の発展に寄与するものと期待される。
これらのモデルは、KreaAI、Freepik、Lightricks、OpenArt、LeonardoAIといったクリエイティブプラットフォームや、FAL、Replicate、Runware、DataCrunch、TogetherAI、ComfyOrgといったインフラパートナーを通じてAPIアクセスが可能となっている。
Kontextが実現する驚異の編集能力 – 主要機能とユースケース詳解
FLUX.1 Kontextが持つ具体的な能力は、まさに「魔法のようだ」と表現するユーザーもいるほどだ。ここでは、その主要な機能と、それらがどのようなユースケースで輝きを放つのかを深掘りしていこう。
キャラクターの一貫性 (Character Consistency) – 異なる世界線でも「あなた」は「あなた」のまま
これはKontextの最も強力な特徴の一つと言えるだろう。一度生成または参照したキャラクター(人物や動物など)の顔の特徴、髪型、表情といったアイデンティティを、全く異なるシーンや環境、服装、ポーズに変更しても、驚くほど高い精度で維持する。
例えば、Runwareが公開した例では、Albert Einsteinの肖像写真を元に、「サイバーパンク風のジャケットを着てネオン街を歩く姿」や「宇宙服を着て火星に立つ姿」など、多様なシチュエーションを生成しているが、顔の特徴は一貫してEinsteinそのものだ。これは、ストーリーテリングやコンテンツマーケティングにおいて、同一キャラクターを様々な状況で登場させたい場合に絶大な威力を発揮する。従来、複数の写真撮影や複雑な画像合成作業が必要だったことが、簡単なテキスト指示だけで実現できてしまうのだ。




ローカル編集 / 精密なオブジェクト修正 – 狙った箇所だけをピンポイントに変更
画像内の一部分だけを選択的に、かつ周囲に影響を与えることなく修正する能力も卓越している。Black Forest Labs自身のデモでは、女性の顔についている物体を「remove the thing from her face(彼女の顔からその物体を取り除いて)」という指示だけで自然に消し去っている。

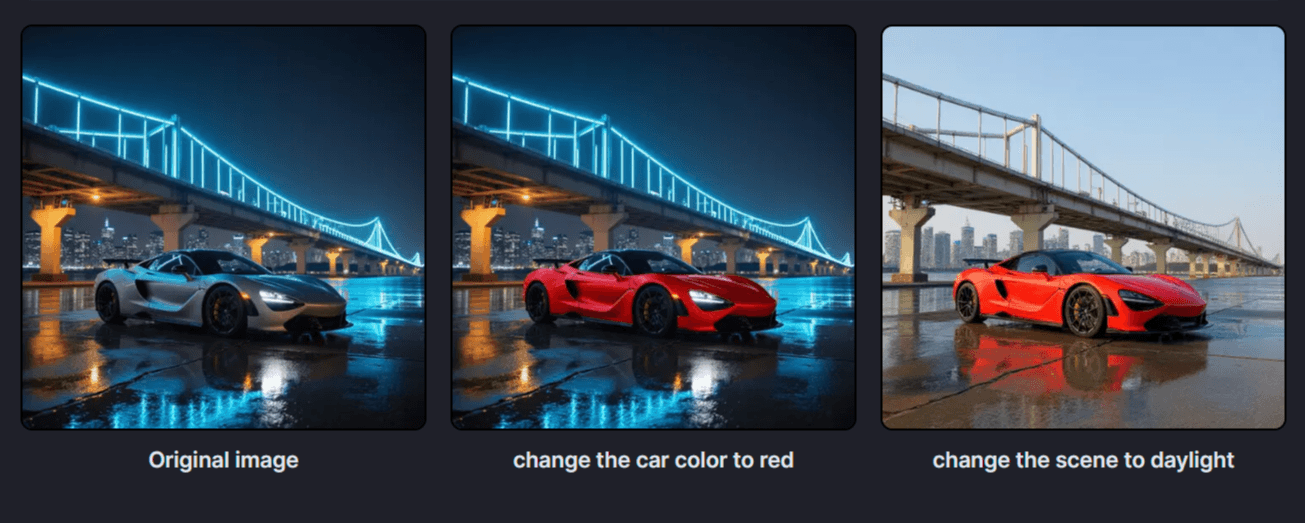
Runwareの例では、夜景に停まるシルバーのスポーツカーの色を「change the car color to red(車の色を赤に変えて)」という指示で、車体色だけを鮮やかな赤に変更し、背景や光の反射などは元の状態を維持している。このような局所的で意味論的な編集(localized semantic editing)は、プロダクト写真の色バリエーション作成や、写真内の不要な写り込みの除去などに非常に有効だ。
スタイル参照・変換 (Style Reference/Transfer) – 元の構図はそのままに、世界観だけをガラリと変える
参照画像のスタイル(例:特定の画家の画風、アニメ調、LEGOブロック風など)を抽出し、それを別の画像やテキスト指示による新規生成画像に適用する能力も高い。Replicateのブログでは、フクロウの写真を「Convert to quick pencil sketch(鉛筆スケッチに変換)」や「Convert to colorful gouache painting(カラフルなガッシュ画に変換)」といった指示で、元のフクロウの構図や特徴を保ちつつ、見事に異なるアートスタイルに変換している。
Runwareでは、女性の写真を元に、LEGOブロック風、ゴッホ風、アニメ風、ピクサー3D風など、多種多様なスタイルに変換する作例を提示しており、その表現力の幅広さを示している。この機能は、既存のビジュアルアセットを様々なメディアやキャンペーンの雰囲気に合わせて再利用する際に、時間とコストを大幅に削減できるだろう。


インタラクティブな速度 (Interactive Speed) – 思考を止めない、ストレスフリーな編集体験
クリエイティブな作業において、ツールの応答速度は思考の流れを左右する重要な要素だ。FLUX.1 Kontextは、画像生成および編集時のレイテンシ(遅延)を最小限に抑えるよう設計されており、Black Forest Labsによれば、主要な競合モデルと比較して最大8倍高速に動作するという。Runwareが示した比較グラフでも、Kontextモデル群が他の有力モデルよりも高速であることが示唆されている。このインタラクティブな速度は、試行錯誤を繰り返しながらアイデアを練り上げていくデザインプロセスにおいて、大きなアドバンテージとなる。
反復編集 (Iterative Editing) – 理想のイメージへ、一歩ずつ着実に
FLUX.1 Kontextのもう一つの強力な点は、編集を段階的に積み重ねていけることだ。最初の指示で大まかな変更を加え、次に細部を修正し、さらに別の要素を追加する、といった具合に、まるで会話をするようにAIと対話しながら画像を完成に近づけていくことができる。しかも、その過程で画像の品質やキャラクターの一貫性が損なわれにくい。
Runwareが紹介したフルーツスタンドの例は非常に分かりやすい。最初の画像から「バナナをマンゴーに置き換える」→「木箱に『FRUIT』の文字を追加する」→「木箱を緑色に塗る」→「全ての果物に面白いギョロ目をつける」といった指示を順番に与えることで、段階的に複雑でユーモラスな画像へと変化させている。このような反復的なワークフローは、一度の完璧なプロンプトを考えるよりも、より柔軟で直感的なクリエイションを可能にする。
高度なテキスト編集 (Superior Text Editing) – 画像内の文字も、まるでワープロのように自由自在
画像内に含まれるテキストの編集能力も、FLUX.1 Kontextの特筆すべき点だ。多くの場合、AIモデルはテキストを単なる視覚要素として扱いがちで、フォントスタイルが変わってしまったり、意図しない形になったりすることがあった。しかしKontextは、テキストの意味を理解し、元のタイポグラフィ、エフェクト、位置などを維持しながら、指示された文字列に正確に置換・編集する。
Replicateのブログでは、映画『あの頃ペニー・レインと』のポスター画像に描かれたサングラスのレンズ内の文字を「Change the text in the sunglasses to be ‘FLUX’ and ‘Kontrast’」という指示で見事に変更している。Runwareも、ジュースのパッケージやGPUの製品画像、レトロなサーカスポスターの文字を、元のデザイン性を損なうことなく置き換える例を多数紹介している。この機能は、広告クリエイティブの多言語展開(ローカライズ)、マーケティング資料のアップデート、パーソナライズされたグラフィック作成など、商業的な用途でも非常に有用だ。
パフォーマンスと他モデルとの比較 – Kontextの実力は本物か?
Black Forest Labsは、FLUX.1 Kontextモデルの性能を検証するために、KontextBenchという独自のベンチマークを構築し、広範な評価を実施したと報告している。その結果、FLUX.1 Kontext [pro]は、テキスト編集やキャラクター保存性といったインコンテキスト画像生成タスクにおいてトップクラスの性能を示し、かつ推論速度においても競合モデルを凌駕したとしている。テキストtoイメージ生成の品質評価においても、美的感覚、プロンプト追従性、タイポグラフィ、写実性の各項目で競争力のある結果を示したという。
Runwareのブログ記事では、FLUX.1 KontextをByteDanceのBAGEL、OpenAIのGPT-4o(Image-1)、GoogleのGemini(Flash)、HiDream E1、Stepfun Step1X-Editといった他の主要な指示ベース画像編集モデルと比較した表が掲載されている。これによると、FLUX.1 Kontext [pro]および[max]は、速度と品質のバランスに優れ、特にキャラクター一貫性やテキスト保存性で「Excellent」と高く評価されている。価格面でも、例えばGPT-4o(Image-1)が1画像あたり約0.045ドル(約7円)であるのに対し、Kontext [pro]は約0.04ドル(約6円)、Kontext [max]は約0.08ドル(約12円)と、競争力のある設定になっているようだ(※価格は変動する可能性あり)。Replicateも、KontextはOpenAIのモデルよりも安価で、かつ「黄色かぶり(yellow tint)」のような問題もないと評価している。
ただし、これらの比較は特定の条件下でのものであり、モデルの特性や得意不得意はタスクによって異なる可能性がある点には留意が必要だ。
FLUX.1 Kontextを実際に試すには? – Playgroundと各種API
Black Forest Labsは、開発者やチームがFLUXモデル群を気軽に試せるように「FLUX Playground」を提供している(playground.bfl.ai)。新規ユーザーは200クレジットを付与されるが、これはFLUX.1 Kontext [pro]でおよそ12枚の画像を生成できる量に相当する。このPlaygroundを利用すれば、本格的なAPI統合の前に、ユースケースの検証、関係者へのデモンストレーション、あるいは純粋な実験を手軽に行うことができる。
より本格的な利用やアプリケーションへの組み込みを考えるなら、各種APIプロバイダー経由でのアクセスが主となる。前述の通り、Replicate、Runware、FALなどのパートナー企業がAPIを提供している。
ComfyUIユーザーにとっては朗報だ。ComfyUIによれば、FLUX.1 KontextはComfyUI内でAPIノードとして利用可能になっている。ComfyUIを最新版にアップデートし、ワークフローのテンプレートブラウザから「Image API」カテゴリを選択すれば、関連テンプレートが見つかるはずだ。ノードは非常にシンプルで、「Flux.1 Kontext [pro] Image」または「Flux.1 Kontext [max] Image」ノードに、編集したい画像を読み込む「Load Image」ノードと、プロンプト、アスペクト比などを設定し、結果を「Save Image」ノードで保存するという流れになる。
Replicateも、自社プラットフォーム上でKontextモデルを実行するためのJavaScriptクライアントのコード例を公開しており、数行のコードで簡単にAPI連携が可能であることを示している。
Kontextを最大限に使いこなすためのヒント
FLUX.1 Kontextの真価を引き出すには、効果的なプロンプトの記述が不可欠だ。幸い、Black Forest Labs自身やパートナー企業、そしてComfyUI Wikiなどが、実践的なヒントを数多く公開している。ここでは、それらを統合し、読者がすぐに役立てられるよう整理して紹介する。
基本原則 – 具体的に、シンプルに、意図的に保持
Kontextへの指示は、人間に対する指示と同じように、具体的で明確であるほど良い結果を生む。
- 具体的であれ: 曖昧な言葉(例:「もっと良くして」)ではなく、正確な色名、詳細な説明、明確な行動動詞を使う。
- シンプルに始めよ: 最初から複雑な指示を一度に行うのではなく、基本的な変更から試し、成功した結果の上に次の変更を積み重ねる。Kontextは反復編集が得意だ。
- 意図的に保持せよ: 変更したくない要素は、プロンプト内で明確に「維持する」ことを指示する。「while maintaining the same facial features(同じ顔の特徴を維持しながら)」や「keep the original composition(元の構図を維持して)」といったフレーズが有効だ。
- 主語を直接指定せよ: 「彼女は」「それは」といった代名詞ではなく、「短い黒髪の女性は」「赤い車は」のように、対象を具体的に記述する。
- プロンプトの長さ: ComfyUI Wikiによれば、プロンプトは最大512トークンという制限がある点に注意。
効果的な指示動詞の選択
Runwareは、Kontextがよく応答する指示動詞の例を挙げている。
- 修正・変更: “Change”, “Make”, “Transform”, “Convert” (例: “Change the sky to sunset”)
- 追加: “Add”, “Include”, “Put” (例: “Add sunglasses to the person”)
- 削除: “Remove”, “Delete”, “Take away” (例: “Remove the person in the background”)
- 置換: “Replace”, “Swap”, “Substitute” (例: “Replace ‘OPEN’ with ‘CLOSED'”)
- 配置: “Move”, “Place”, “Position” (例: “Move the person to the left side”)
オブジェクト修正のコツ
変更したい箇所だけを具体的に指示し、シーン全体を詳細に説明する必要はない。これにより、編集がシンプルかつ直感的になる。
スタイル変換のコツ
- 具体的なスタイル名を指定: 「Bauhaus art style」「1960s pop art poster style」など。
- 特徴を記述: 「Visible brushstrokes, thick paint texture(目に見える筆致、厚い絵の具の質感)」など。
- 保持する要素を明示: 「While maintaining the original composition and placement(元の構図と配置を維持しながら)」
キャラクター一貫性のコツ
ComfyUI Wikiの「キャラクター一貫性の3ステップメソッド」が参考になる。
- 参照の確立: 「The woman with short black hair(短い黒髪の女性)」のように、対象のアイデンティティを明確に定義する。
- 変更の指定: 「Now in a tropical beach setting(今は熱帯のビーチの背景で)」のように、変更内容を具体的に指示する。
- 保持マーク: 「While maintaining the same facial features and expression(同じ顔の特徴と表情を維持しながら)」のように、保持したい特徴を指定する。
テキスト編集のコツ
- 引用符で対象テキストを囲む: 「Replace ‘SALE’ with ‘SOLD’」のように、変更したいテキストを正確に引用符で囲む。これにより、Kontextはテキスト置換の意図を正確に理解する。
- スタイル保持を明示: フォントスタイル、色、効果などを維持したい場合は、「while maintaining the same font style and color(同じフォントスタイルと色を維持しながら)」といった指示を追加する。
- テキスト長: 可能であれば、元のテキストと新しいテキストの長さを近づけると、レイアウトの崩れを防ぎやすい。
構図制御のコツ
背景を変更する際などに、被写体の位置やスケールが変わってしまうのを防ぐには、「Change the background to a beach while keeping the person in the exact same position, scale, and pose(背景をビーチに変更し、人物は全く同じ位置、スケール、ポーズを維持する)」のように、保持したい構図要素を具体的に指示する。
トラブルシューティングとチェックリスト
ComfyUI Wikiには、一般的な問題(キャラクターのアイデンティティ変化、構図のズレ、スタイル詳細の損失など)とその解決策、さらにはプロンプトを使用する前のチェックリスト(修正内容の明確化、変更しない要素の記述、トークン制限の確認など)が掲載されており、非常に参考になる。
完璧ではないが、進化への期待は大きい
いかに革新的な技術といえども、最初から完璧ということはない。Black Forest Labsは、FLUX.1 Kontextの現在の限界についても率直に情報を公開している。
- 過度な反復編集による視覚的アーティファクト: あまりにも多くの編集を重ねると、画像の品質が低下し、不自然なノイズなどが発生することがある。
- 指示追従の失敗: まれに、プロンプトの特定の要件を無視したり、指示通りに動作しなかったりする場合がある。
- 世界知識の限界: モデルが持つ一般的な知識には限りがあり、文脈的に正確なコンテンツを生成する能力に影響を与えることがある。
- 蒸留プロセスによるアーティファクト: モデルの軽量化などのための蒸留プロセスが、出力の忠実度に影響を与える視覚的アーティファクトを導入する可能性がある。
これらの課題は、今後のモデル改良によって克服されていくことが期待される。Black Forest Labsは、「私たちの使命は、メディア生成のための最も先進的なモデルとインフラを構築することです」と述べ、「私たちはまだ始まったばかりです(We’re just getting started.)」と、その進化への強い意志を示している。
FLUX.1 Kontextが切り拓く、AIクリエイションの新たな地平
FLUX.1 Kontextの登場は、単なる新しい画像編集ツールのリリース以上の意味を持つ。これは、Runwareが的確に表現したように、「画像編集がようやく人々が実際に考える方法で機能する瞬間」の到来を告げるものかもしれない。
従来のAI画像編集・生成が、しばしば「AIにどう伝えれば意図通りに描いてくれるか」という“AIのご機嫌伺い”のような側面を伴っていたのに対し、Kontextは、より人間同士のコミュニケーションに近い、「ここをこうしてほしい」という直接的な指示で、AIが意図を汲み取り、的確に応えてくれるという新しい関係性を提示している。
この進化は、プロのクリエイターだけでなく、日常的にビジュアルコンテンツを扱うマーケター、教育者、あるいは個人的な趣味で画像編集を楽しむ一般ユーザーに至るまで、あらゆる層に恩恵をもたらすだろう。アイデアを形にするまでの時間と手間が劇的に削減され、より多くの人々が、より自由に、より創造的なビジュアル表現を追求できるようになる。
もちろん、AI技術の進化には、著作権や倫理的な課題も伴う。しかし、Black Forest Labsが「オープンな研究と重みの共有」を重視し、devモデルを提供する姿勢は、これらの課題に対する建設的なアプローチの一つと言えるかもしれない。
Sources