
AI検索エンジンPerplexityが、Webサイトのクロール拒否設定を意図的に回避するため、身元を隠す「ステルス戦術」を用いていると、ネットワーク大手Cloudflareが告発した。これは30年以上続くインターネットの信頼の根幹を揺るがす行為であり、生成AIの倫理が再び厳しく問われることになりそうだ。
暴かれた「ステルスクローラー」の巧妙な手口
Cloudflareが2025年8月4日に公開したブログ記事は、AI企業の倫理観が、どこか世間のそれとかけ離れているのではと考えさせられる内容だ。 同社によれば、複数の顧客から「robots.txtファイルやファイアウォールでPerplexityのクローラーをブロックしているにもかかわらず、コンテンツがアクセスされ続けている」という苦情が寄せられたことが調査のきっかけだったという。
robots.txtとは、Webサイト運営者が検索エンジンなどのクローラー(自動巡回プログラム)に対し、どのページを収集してよいかを伝えるための、Webの黎明期から存在する「紳士協定」である。
Cloudflareが検証のために実施したテストは、その手口の巧妙さを浮き彫りにした。まず彼らは外部からアクセスできない新規ドメインを用意し、robots.txtですべてのクローラーを拒否する設定を施した。 にもかかわらず、Perplexityにそのドメインに関する質問を投げかけると、制限されているはずのコンテンツに基づいた詳細な回答が生成されたのだ。
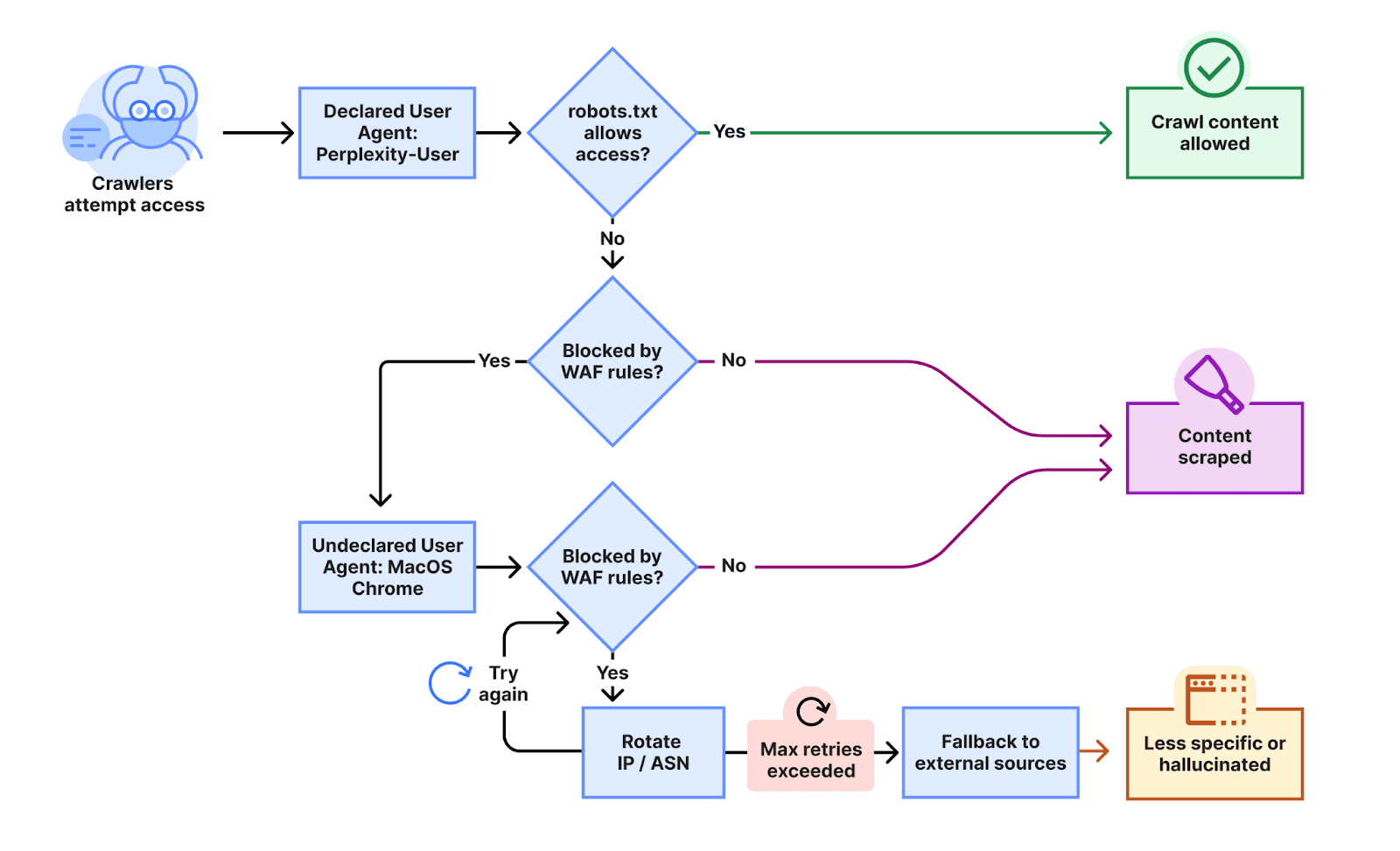
Cloudflareの分析によると、Perplexityは二段構えの戦術を用いていた。
第1段階:公認クローラーでのアクセス
まず、PerplexityBotやPerplexity-Userといった公式に宣言されたクローラーでアクセスを試みる。 この段階でサイト側がブロックしていることを検知すると、次の段階へ移行する。
第2段階:ステルスクローラーの投入
ここからが問題の核心だ。Perplexityは、正体を隠した「ステルスクローラー」を投入する。 このクローラーは、以下のような複数の技術を駆使してブロックを回避していた。
- ユーザーエージェントの偽装: 自身をボットではなく、macOS上で動作する一般的な「Google Chromeブラウザ」であるかのように偽装する。
- IPアドレスのローテーション: Perplexityが公式に公開しているIPアドレス帯域外のものを複数使用し、ブロックを避けるためにそれらを次々と切り替える。
- ASN(自律システム番号)の変更: さらに追跡を困難にするため、IPアドレスの管理母体であるASNまでも変更していたという。
Cloudflareによれば、このステルス活動は数万のドメインにわたり、1日あたり数百万リクエストという膨大な規模で観測された。 まさに、Webサイト運営者の意思を組織的に踏みにじる行為と言っていいだろう。
インターネットの「紳士協定」を揺るがす行為
この問題の根は深い。robots.txtは、1994年に提唱されて以来、法的拘束力はないものの、Webの健全な発展を支えてきた重要な規範だ。 Googleをはじめとする主要な検索エンジンは、このプロトコルを尊重することで、Webサイト運営者との信頼関係を築いてきた。
しかし、生成AIの登場がこのバランスを崩し始めている。AIモデルの学習や、PerplexityのようなAI検索が用いるRAG(検索拡張生成)技術は、膨大な最新データを必要とする。ボット対策企業TollBitの報告によれば、robots.txtを無視するボットの割合は2025年第1四半期に3.3%から12.9%へと急増。 特にRAG目的のスクレイピングは、学習目的のそれを上回る勢いで増加しているという。
この「寄生的な関係」は、コンテンツ制作者にサーバーコストを負担させながら、見返りであるはずのサイトへのトラフィックをもたらさない。 TollBitの調査では、サイトへのアクセス1回あたりのスクレイピング回数は、Perplexityが369回、Anthropicに至っては8692回にものぼるという衝撃的なデータも示されている。
Perplexityの反論と拭えぬ過去の疑惑
一連の告発に対し、Perplexityの広報担当者はTechCrunchやThe Vergeの取材に応じ、Cloudflareの報告を「セールスピッチ」「宣伝行為」と一蹴。 さらに、「ブログで指摘されたボットは我々のものではない」とまで主張している。
しかし、Perplexityがこうした疑惑の目を向けられるのは初めてではない。昨年には、ForbesやWiredといったメディアが、自社の記事が盗用された疑いがあると強く批判。 Wiredは、不審なIPアドレスからのトラフィックがrobots.txtを無視していることを指摘していた。 また、RedditのCEO Steve Huffman氏も、Perplexityを含む複数のAI企業が「インターネット上の全コンテンツを自由に使えるものと考えている」と名指しで批判している。
過去の経緯を鑑みれば、今回のCloudflareの告発に信憑性を見出す向きは少なくないだろう。
AIとコンテンツの未来を巡る攻防の序章
筆者はこの問題を単なる一企業の不正行為として片付けるべきではないと考える。これは、生成AIという新しいテクノロジーと、既存のインターネットのエコシステムとの間に生じた、構造的な摩擦の象徴だ。
注目すべきは、Cloudflareの対応である。同社はPerplexityを「認証済みボット」のリストから除外しただけでなく、このステルスクローリングをブロックするルールを全顧客に提供開始した。 これは、インフラ事業者というプラットフォームが、AIによる無秩序なデータ収集に対して、明確な「否」を突きつけ始めたことを意味する。
対照的に、CloudflareはOpenAIのクローラーを「ベストプラクティスに従っている」と評価している。 これは、AI企業の中でもデータ収集に対する倫理観に大きな隔たりがあることを示唆している。
今回の事件は、Webの未来を左右する大きな問いを我々に投げかけている。このまま無法地帯が続けば、質の高いコンテンツはペイウォールの内側に閉じこもり、オープンなWebはAIが生成した真偽不明の「合成スロップ」で埋め尽くされる未来も、決して絵空事ではないのではないか?
技術による防衛(Cloudflareの対策など)と、業界標準や法整備といったルールの確立。その両輪が揃わなければ、我々が知る豊かで多様なインターネットは、その姿を大きく変えてしまうだろう。AIとコンテンツホルダーの共存共栄に向けた、長く困難な交渉の幕が、今まさに上がったのではないだろうか。
Sources

