
Googleは、同社のオープンモデルファミリー「Gemma」の最新版として、スマートフォンやタブレット、ラップトップなどのデバイス上で直接動作することを主眼に置いた「Gemma 3n」のプレビュー版を発表した。この新しいAIモデルは、驚異的な効率性を実現する革新的なアーキテクチャを採用し、リアルタイムかつプライベートなマルチモーダルAI体験をモバイル環境にもたらすことを目指している。これは、GoogleのオンデバイスAI戦略における重要な一歩であり、将来的に「Gemini Nano」の能力を拡張する基盤技術となる可能性を秘めている。
Gemma 3nとは何か? – モバイルファーストAIの新たな地平
Gemmaファミリーは、Googleが提供する最先端のオープンモデル群であり、開発者がAIアプリケーションを容易に構築・展開できるよう支援することを目的としている。先行する「Gemma 3」や、コンシューマー向けGPUでの実行に最適化された「Gemma 3 QAT」がクラウドやデスクトップ環境での高性能な処理能力に焦点を当てていたのに対し、今回発表された「Gemma 3n」は、明確に「モバイルファースト」を掲げている点が最大の特徴だ。
今日のAIはクラウドベースでの処理が主流だが、オンデバイスAIには、ユーザーのプライバシー保護、インターネット接続なしでのオフライン動作、そして遅延の少ないリアルタイム応答性といった大きな利点がある。Gemma 3nは、まさにこれらのメリットを追求するために設計されたモデルと言えるだろう。
GoogleはこのGemma 3nの実現のために、Qualcomm Technologies、MediaTek、Samsung System LSIといったモバイルハードウェアのリーディングカンパニーと緊密に連携し、次世代のオンデバイスAIを支えるための新しい最先端アーキテクチャを共同で設計したという。これは、単なるソフトウェアの進化に留まらず、ハードウェアとの協調によってエコシステム全体でオンデバイスAIを推進しようというGoogleの強い意志の表れではないだろうか。
なぜ「超効率」なのか? Gemma 3nを支える革新的技術
Gemma 3nがモバイルデバイスというリソースの限られた環境で高性能を発揮できる背景には、いくつかの革新的な技術の採用がある。特に注目すべきは、「Per-Layer Embeddings (PLE)」と「MatFormerアーキテクチャ」だ。
Per-Layer Embeddings (PLE) – メモリ消費を劇的に削減する魔法
Gemma 3nは、Google DeepMindが開発した「Per-Layer Embeddings (PLE)」という技術を活用することで、RAMの使用量を大幅に削減することに成功した。通常、AIモデルのパラメータ数(モデルの規模や複雑さを示す指標)が増えれば増えるほど、必要とされるメモリ量も増大する。しかしPLEを用いることで、例えばGemma 3nの50億(5B)および80億(8B)パラメータモデルは、それぞれわずか2GBと3GBのダイナミックメモリフットプリントで動作可能になるという。これは、実質的に20億(2B)や40億(4B)パラメータのモデルと同等のメモリ効率であり、驚異的な効率性だ。
具体的には、PLEパラメータはモデルの各層の性能を向上させるために使用されるが、これらをモデルのメインメモリ空間外(例えば高速なローカルストレージ)にキャッシュしておき、各層の推論実行時に動的に読み込んで利用する。これにより、モデル全体のメモリ消費を抑えつつ、高い性能を維持できる仕組みだ。
MatFormerアーキテクチャ – 必要に応じて賢く変身するモデル
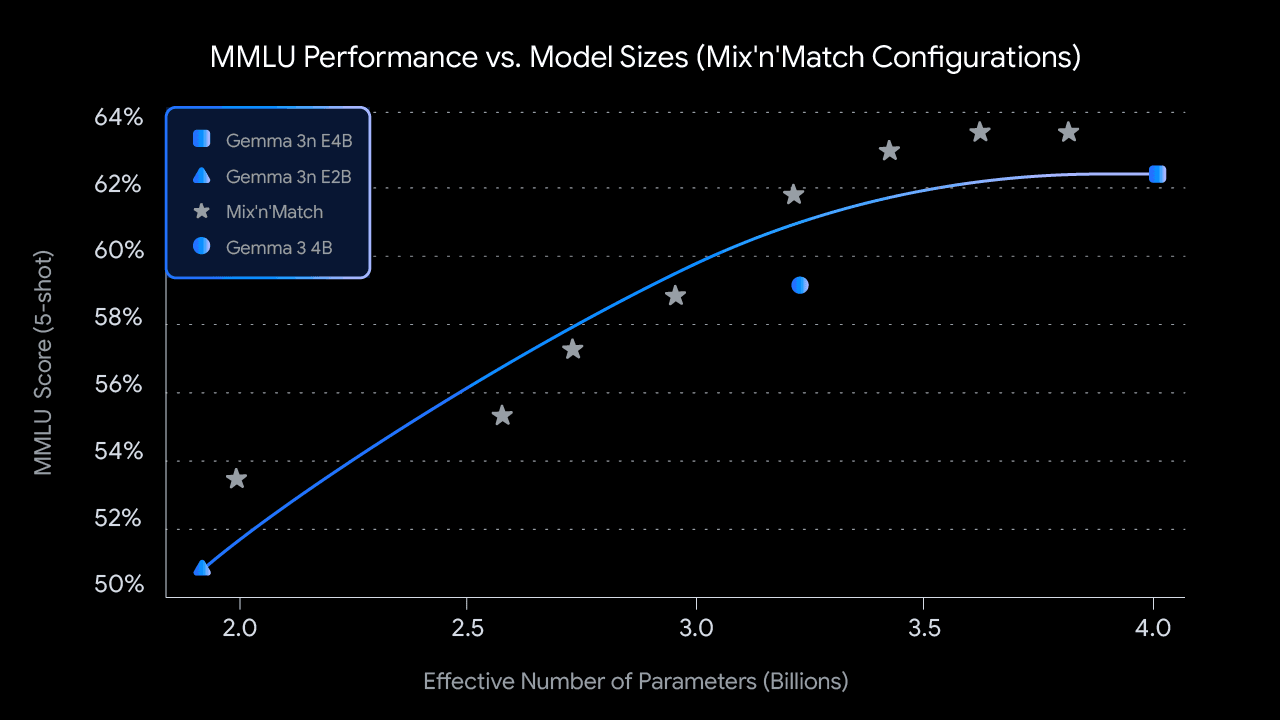
もう一つの鍵となる技術が、「MatFormer(Matryoshka Transformer)」アーキテクチャだ。これは、ロシアの入れ子人形「マトリョーシカ」のように、大きなモデルの内部に、より小さな高性能なサブモデルがネストされて含まれている構造を指す。
このアーキテクチャにより、Gemma 3nはタスクの複雑性やデバイスの状況に応じて、活性化するパラメータの範囲を動的に調整できる。例えば、Gemma 3nの4B(実効パラメータ数)モデルは、内部に2B(実効パラメータ数)のサブモデルを内包しており、より軽量な処理が求められる場合には、このサブモデルのみを利用して応答することで、計算コスト、応答時間、さらには消費電力まで削減できる。
さらに、「mix’n’match」機能により、開発者は4Bモデルから特定のニーズに合わせて、2Bと4Bの中間的なサイズのサブモデルを動的に生成することも可能になるという。これにより、アプリケーションの特性や品質と遅延のトレードオフを考慮し、最適なモデルを柔軟に選択・構築できるようになる。この研究の詳細については、近日公開予定のテクニカルレポートで明らかにされるとのことだ。
KVC共有と高度な活性化量子化、そして条件付きパラメータ読み込み
これらの主要技術に加え、Gemma 3nは「KVC共有(Key-Value Cache sharing)」や「高度な活性化量子化」といった技術も活用し、さらなる効率化を追求している。
また、「条件付きパラメータ読み込み」という機能も搭載。これは、例えば視覚処理や音声処理に関連するパラメータを、必要に応じてロードしたり、あるいはメモリ負荷を軽減するためにロードをスキップしたりできる機能だ。これにより、タスクに応じてモデルのメモリフットプリントをさらに最適化し、より広範なデバイスでの実行可能性を高める。
これらの技術の組み合わせにより、Gemma 3nは、先行するGemma 3の4Bモデルと比較して、応答開始速度が約1.5倍高速化し、かつ品質も向上、メモリフットプリントも大幅に削減するという、目覚ましい成果を達成している。
Gemma 3nで何ができる? – 拡がるマルチモーダルと多言語対応
Gemma 3nは、その効率性だけでなく、機能面でも大きな進化を遂げている。特にマルチモーダル能力の強化と多言語対応の向上が際立っている。
マルチモーダル能力の飛躍的進化 – 音声、画像、動画も理解
Gemma 3nは、テキストや画像に加え、新たに「音声」の処理能力を獲得し、さらに「動画理解」能力も大幅に強化される。これにより、以下のような高度な機能がオンデバイスで実現可能になる。
- 高品質な自動音声認識(ASR): 音声をリアルタイムでテキストに書き起こす。
- 音声翻訳: 話し言葉を翻訳されたテキストとして出力する。
- 複数モダリティのインターリーブ入力: 例えば、画像を見せながら音声で質問するといった、より自然で複雑なマルチモーダルインタラクションを理解できる。
これらの機能は、リアルタイム翻訳アプリ、次世代の音声アシスタント、アクセシビリティ支援ツールなど、様々なアプリケーションに革新をもたらすだろう。なお、音声関連機能の一般向け実装は近日公開予定とのことだ。
多言語対応の強化 – グローバルな利用シーンへ
グローバルなコミュニケーションの重要性が増す現代において、AIの多言語対応能力は不可欠だ。Gemma 3nは、特に日本語、ドイツ語、韓国語、スペイン語、フランス語といった主要言語での性能が向上している。Googleによると、多言語ベンチマークであるWMT24++ (ChrF)において50.1%という高いスコアを達成しており、その実力が伺える。
Gemini Nanoとの連携 – GoogleオンデバイスAIエコシステムの未来図
Gemma 3nの発表で特に注目すべきは、このモデルのアーキテクチャが、GoogleのオンデバイスAIの中核を担う「Gemini Nano」の次世代版の基盤となる点だ。Gemini Nanoは、Android OSやChromeブラウザといった、世界中で数十億のユーザーを抱えるプラットフォームに搭載される予定の軽量モデルである。
つまり、開発者がGemma 3nのプレビュー版を通じて触れることのできる革新的な技術(PLE、MatFormerなど)は、将来的には膨大な数のスマートフォンやPCで標準的に利用可能なAI機能として展開される可能性があるということだ。これは、Googleが描くオンデバイスAIエコシステムの壮大な構想の一端であり、開発者にとっては、自らのアプリケーションに最先端のAIを組み込む大きなチャンスとなるだろう。Googleのアプリやオンデバイスエコシステム全体に、よりパーソナルで、よりインテリジェントな体験がもたらされる未来が期待される。
開発者はどう使える? – プレビュー版アクセス方法と期待される応用例
Googleは、開発者がGemma 3nの可能性をいち早く探求できるよう、プレビュー版へのアクセスを提供開始している。
- Google AI Studio: ブラウザ上で直接Gemma 3nを試用できる。特別なセットアップは不要で、テキスト入力機能をすぐに体験可能だ。
- Google AI Edge: Gemma 3nをローカル環境に統合し、オンデバイスでの開発を目指す開発者向けのツールとライブラリを提供する。現時点では、テキストと画像の理解・生成機能から利用開始できる。
Gemma 3nを活用することで、以下のような新しいタイプの「オンザゴー(移動中や外出先での)」アプリケーションの開発が期待される。
- ユーザーの周囲の視覚的・聴覚的な情報(リアルタイムの映像や音声)を理解し、即座に応答する、ライブでインタラクティブな体験の構築。
- 音声、画像、動画、テキストといった複数の情報を組み合わせ、それらを全てデバイス上でプライベートに処理することで、より深い文脈理解とそれに基づくテキスト生成。
- リアルタイムの音声文字起こし、翻訳、リッチな音声対話など、高度な音声中心アプリケーションの開発。
Googleが公開した以下のデモ動画では、Gemma 3nが実現するであろう未来の体験の一端が示唆されている。
責任あるAI開発へのコミットメントとライセンスに関する議論
Googleは、Gemma 3nを含む全てのGemmaモデルにおいて、責任あるAI開発へのコミットメントを強調している。厳格な安全性評価、データガバナンス、そしてGoogleの安全ポリシーに沿ったファインチューニングが行われているという。AI技術が急速に進化する中で、オープンモデルに伴うリスクを慎重に評価し、継続的にそのプラクティスを改善していく姿勢を示している。
ただし、完全なオープンソースというわけではなく、Gemmaファミリーのライセンス条件は独自の非標準的なものであり、商用利用においてリスクを伴う可能性もある。Gemmaモデル群は既に数千万回以上ダウンロードされるなど、開発者コミュニティからの関心は非常に高いものの、利用者はライセンスの詳細を十分に確認する必要があるだろう。
Gemma 3nが切り拓くAIの新たな可能性
Google Gemma 3nの登場は、オンデバイスAI、モバイルAIの分野における大きな前進と言えるだろう。PLEやMatFormerといった革新的な技術により、これまでリソースの制約から困難であった高度なAI処理が、私たちの手の中にあるスマートフォンやラップトップで現実のものとなりつつある。
これは、AIの民主化をさらに加速させ、より多くの開発者が、よりパーソナルで、プライバシーに配慮したインテリジェントなアプリケーションを創造する道を開くものだ。特に、次世代Gemini Nanoへの布石となるこの技術が、AndroidやChromeといった巨大プラットフォームに展開されれば、その影響は計り知れない。
もちろん、音声や動画関連機能の一般提供はこれからであり、ライセンスに関する議論など、注視すべき点も残されている。しかし、Gemma 3nが示した方向性は、AIがより身近で、より生活に溶け込んだ存在になる未来を強く予感させる。Googleの本気度が伝わってくるこの一手は、テクノロジー業界全体に新たな刺激を与え、開発者コミュニティによるさらなるイノベーションを促進することになるのではないだろうか。
Source