
目まぐるしいスピードで進化を続けるAI技術。特に大規模言語モデル(LLM)やマルチモーダルAIは、その能力の高さから様々な分野での活用が期待されている。しかし、その一方で、乱立するAIモデルの性能をいかに公正かつ効率的に評価するかは、開発者や研究者にとって大きな悩みの種であった。この混沌とした状況に一石を投じるべく、GoogleはオープンソースのAI評価フレームワーク「LMEval」を発表した。果たしてこのLMEvalは、AI評価のデファクトスタンダードとなり得るのだろうか?
AIモデル評価の「戦国時代」に終止符?Googleが示した解決策「LMEval」
日々新たなAIモデルが登場し、それぞれが「最高性能」を謳う。しかし、開発者や組織が自らの目的に最適なモデルを選定しようにも、プロバイダーごとに異なるAPI、評価手法、データセットの扱いに翻弄され、横並びでの正確な比較は困難を極めていた。時間とコストを浪費する非効率な評価プロセスは、イノベーションの足枷となりかねない状況だったと言えるだろう。
このような課題を解決するためにGoogleが開発し、オープンソースとして公開したのが「LMEval(Large Model Evaluator)」である。その目的は明確だ。多様なプロバイダーから提供されるAIモデルの性能を、統一された枠組みのもとで、正確かつ効率的に、そして再現性高く評価できるようにすること。これにより、開発者はモデル選定の意思決定を迅速化し、より本質的な開発作業に集中できるようになることが期待される。
LMEvalの核心に迫る:開発現場を変える主要機能とは
LMEvalの特徴は、その考え抜かれた設計と機能群にある。ここでは主要な特徴を深掘りしていこう。
1. プロバイダーの垣根を越える「マルチプロバイダー互換性」
LMEvalの最大の強みの一つが、特定のAIプロバイダーに依存しない設計だ。これを実現しているのが、内部で活用されている「LiteLLM」フレームワークである。LiteLLMが各プロバイダーのAPI差異を吸収することで、LMEvalユーザーは一度ベンチマークを定義すれば、Google、OpenAI、Anthropic、Ollama、Hugging Faceといった主要プロバイダーのモデルに対し、最小限のコード変更で同じ評価を実行できる。これは、まさに開発者が待ち望んでいた機能と言えるのではないだろうか。
2. 賢く、速く、無駄なく評価「インクリメンタル&効率的評価」
新しいモデルや評価項目が追加されるたびに、全てのベンチマークを再実行するのは非効率的だ。LMEvalは、この問題を「インクリメンタル評価」という賢いアプローチで解決する。変更があった部分、つまり新しいモデルやプロンプト、質問に対してのみ評価を実行するため、時間と計算リソースを大幅に節約できる。さらに、マルチスレッドエンジンにより評価プロセス全体の高速化も図られており、迅速なイテレーションを可能にする。
3. テキストの先へ「マルチモーダル&マルチメトリック対応」
現代のAIモデルはテキスト処理だけに留まらない。LMEvalは、テキストはもちろん、画像やコードといった多様なモダリティ(情報の種類)を含むベンチマークに対応できるよう設計されている。Googleによれば、新たなモダリティの追加も容易だという。
評価指標も、単純な正誤(ブーリアン)や多肢選択問題から、より複雑な自由形式の文章生成まで、幅広い形式をサポート。特筆すべきは、「安全性/パンティング検知」機能だ。これは、モデルが問題のあるコンテンツ生成を回避するために意図的に曖昧な回答や応答拒否(パンティング)をする戦略を検知するもので、AIの安全性評価において重要な役割を果たすだろう。
4. 結果を安全かつ効率的に管理「スケーラブル&セキュアストレージ」
評価結果という貴重なデータは、安全かつ効率的に管理されなければならない。LMEvalは、ベンチマーク結果の保存に自己暗号化SQLiteデータベースを採用。これにより、データはローカルで安全に保護され、意図しないクローリングやインデックス化を防ぎつつ、LMEvalを通じて容易にアクセスできる。
LMEvalの実力は?評価の実行と「LMEvalboard」による可視化
LMEvalの導入と利用は直感的になるよう設計されている。GitHubリポジトリ(https://github.com/google/lmeval)には、Pythonでのインストールコマンド (pip install lmeval) や、開発者向けのセットアップ手順、さらにはGeminiモデルの異なるバージョンを比較評価するサンプルノートブックなどが提供されており、ユーザーはこれらを参考にすぐに評価を開始できる。Googleが公開した資料では、このサンプルコードが簡潔にLMEvalの強力な機能の一端を示している。
そして、評価結果を単なる数値の羅列で終わらせないために、LMEvalは「LMEvalboard」という強力な相棒を提供する。これは、評価結果をインタラクティブに可視化・分析するためのダッシュボードツールだ。LMEvalboardを使えば、以下のような分析が容易になる。
- 全体パフォーマンスの把握: ベンチマーク全体での全モデルの精度を迅速に比較。
- 単一モデルの詳細分析: 特定モデルの性能特性を、カテゴリ別のレーダーチャートなどで深く掘り下げ、失敗例を具体的に確認。
- 直接比較: 2つのモデルを直接対決させ、カテゴリごとの性能差や、回答が分かれた具体的な質問を視覚的に比較検討。
デモンストレーション動画では、LMEvalboardが特定のタスクでモデルがどこで間違えたかをドリルダウンして表示する様子が紹介されており、単なるスコア比較以上の深い洞察を得られる可能性を示している。
オープンソースが拓くAI評価の未来:Giskardとの連携も
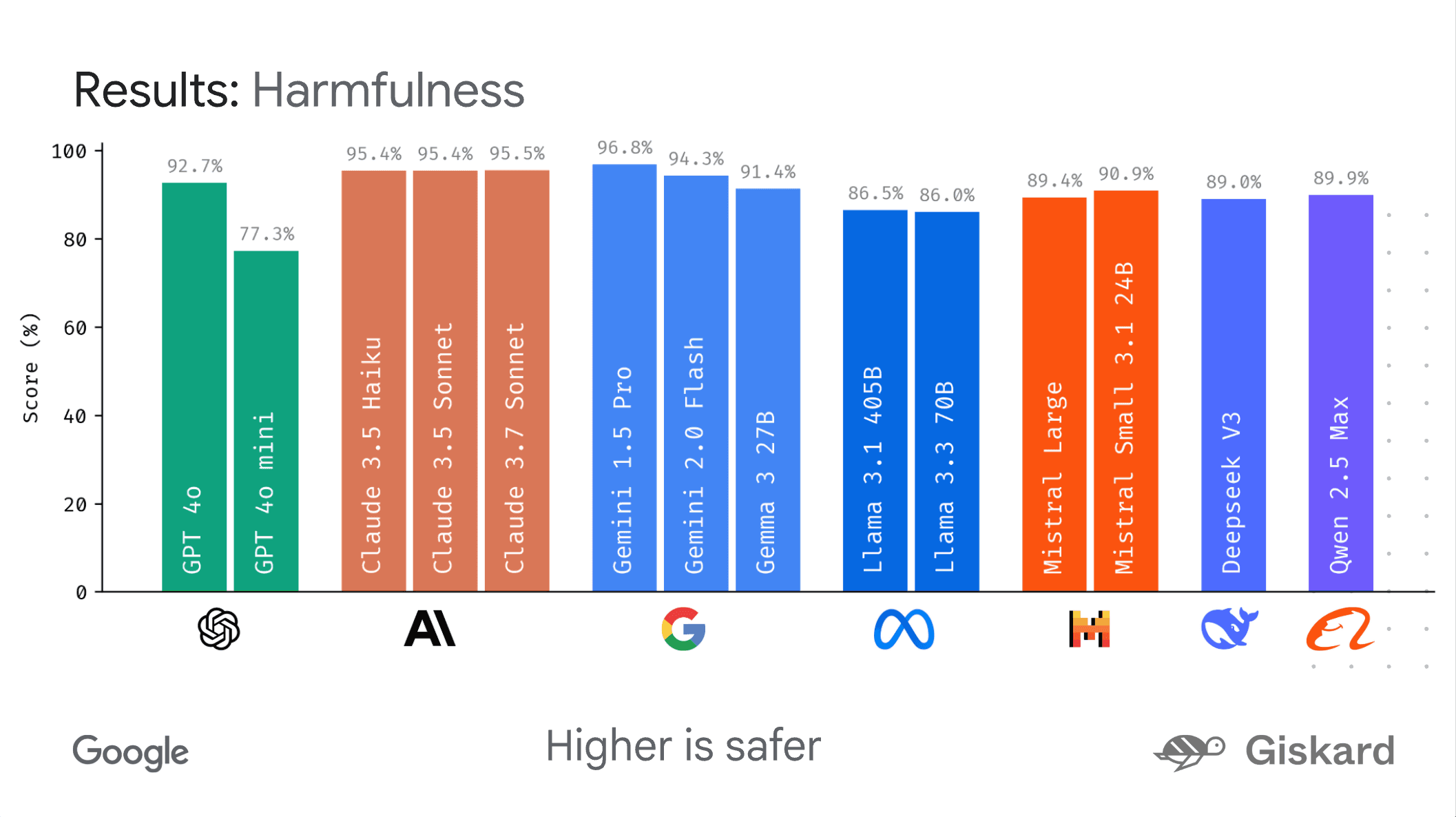
LMEvalの発表は、Googleの単独行動ではない。同社は、AIモデルの安全性と信頼性向上を目指す仏企業Giskardと協力関係にあることを明らかにしている。Giskardは、LMEvalを同社の「Phareベンチマーク」に活用し、主要AIモデルのセキュリティと安全性を独立して評価しているという。実際に、GiskardがLMEvalを用いて実施したPhareベンチマークの結果を示すグラフは、各モデルが有害コンテンツをどの程度回避できるかという安全性スコアを分かりやすく提示しており、LMEvalの実用性とオープンな評価の重要性を物語っている。
LMEvalをオープンソースとして公開したことは、AI評価の透明性と信頼性を高め、より健全なAIエコシステムの発展を促す上で大きな意味を持つ。コミュニティによる貢献やフィードバックを通じて、LMEval自身がさらに進化していくことも期待されるだろう。
LMEvalはAI開発の羅針盤となるか
LMEvalの登場は、複雑化するAIモデル評価の世界に、標準化と効率化という明確な方向性を示すものだ。マルチプロバイダー対応、インクリメンタル評価、マルチモーダルサポート、そして強力な可視化ツールLMEvalboardといった機能は、AI開発者や研究者が長年抱えていた課題の多くを解決する可能性を秘めている。
オープンソースとして公開されたことで、LMEvalはコミュニティと共に成長し、AI評価の新たな羅針盤となるポテンシャルを秘めていると言えるだろう。AI技術が社会により深く浸透していく中で、その性能を公正かつ透明性の高い方法で評価することの重要性は増すばかりだ。LMEvalがその一翼を担い、より安全で信頼できるAIの未来を切り拓くことを期待したい。興味を持った開発者は、ぜひGitHubリポジトリを訪れ、その可能性を自ら確かめてみてはいかがだろうか。
Sources
- Google Open Source: Announcing LMEval: An Open Source Framework for Cross-Model Evaluation
- GitHub


