
Googleが、スマートフォン上でAIモデルをインターネット接続なしにローカル実行できる実験的なAndroidアプリ「Google AI Edge Gallery」を、GitHub上で静かに公開した。これにより、ユーザーはGoogleの最新AIモデル「Gemma 3n」をはじめとする複数のオープンソースAIモデルを自身のデバイスで直接試すことが可能になる。プライバシー保護やオフラインでの利便性向上といったオンデバイスAIのメリットを、一般ユーザーが体験できる道が開かれたと言えるだろう。
Google AI Edge Galleryとは?~手のひらにローカルAIの新体験
Google AI Edge Galleryは、Google AI Edgeチームが開発し、GitHub上で公開した実験的アルファ版のAndroidアプリケーションだ(iOS版も近日公開予定)。その最大の特長は、クラウドサーバーにデータを送信することなく、スマートフォン上で直接、大規模言語モデル(LLM)などのAIモデルを動作させられる点にある。
主な機能:
- オフラインAI実行: 一度モデルをダウンロードすれば、インターネット接続なしでAI機能を利用可能。
- 多様なAIモデル: Google製の「Gemma 3n」やAlibabaの「Qwen 2.5」など、Hugging Face経由で提供される複数のオープンソースモデルを選択・ダウンロードできる。
- 多彩なタスク:
- AIチャット: AIモデルと対話形式でコミュニケーション。
- Ask Image: 画像をアップロードし、その内容について質問したり説明を求めたりできる。
- Prompt Lab: テキストの要約、リライト、コード生成など、特定のタスクを指示して実行。
- モデル管理: ユーザー自身がローカルに保存されたモデルを管理。
- Bring Your Own Model (BYOM): 開発者は自身で用意したLiteRT .task 形式のモデルをインポートして試すことも可能。
- パフォーマンスインサイト: モデル実行時のTTFT(Time to First Token:最初のトークン生成までの時間)、デコード速度、レイテンシなどのパフォーマンス指標をリアルタイムで確認できる。
このアプリは、Googleが「LLM Inference APIの実用的な実装と、オンデバイス生成AIの可能性を理解するためのリソース」と位置づけているように、開発者コミュニティからのフィードバックを得ながら、オンデバイスAI技術の可能性を探るための重要な一歩と言えるだろう。
なぜ今、オンデバイスAIなのか?~クラウド依存からの脱却とその意義
これまでAIといえば、強力な計算能力を持つクラウドサーバー上で処理されるのが一般的だった。しかし、オンデバイスAIにはクラウドAIにはない独自のメリットがあり、その重要性が高まっている。
オンデバイスAIの主なメリット:
- プライバシー保護: ユーザーデータがデバイス外部に送信されないため、プライバシー漏洩のリスクを大幅に低減できる。これは特に個人情報や機密情報を扱う場合に大きな安心材料となる。
- オフラインアクセス: インターネット環境がない場所でもAI機能を利用できる。通信状況に左右されない安定した動作は、飛行機内や電波の届きにくい場所での利用、あるいは災害時などにも有効だ。
- 低遅延: クラウドとの通信ラグがないため、応答速度が速い。リアルタイム性が求められるインタラクションや、スムーズなユーザー体験に貢献する。
- コスト削減(サーバー側): ユーザーが増えても、クラウド側の計算リソースへの負荷集中を避けられるため、サービス提供者側のインフラコスト削減にも繋がる可能性がある。
一方で、スマートフォンの処理能力やメモリには限界があるため、クラウドAIで利用できるような超巨大モデルをそのまま動かすのは難しい。また、常に最新情報にアクセスできるわけではないという制約もある。
Google AI Edge Galleryのようなアプリは、Googleが開発した「LiteRT (Lite Runtime)」と呼ばれる軽量ランタイムや、MediaPipeのLLM Inference APIといった技術基盤の上に成り立っている。これらは、限られたリソースのデバイス上でAIモデルを効率的に実行するために最適化された技術であり、オンデバイスAIの普及を後押しする鍵となるだろう。
主役は「Gemma 3n」~スマホ最適化されたGoogle製オープンソースモデル
Google AI Edge Galleryで利用できるモデルの中でも特に注目されるのが、Google DeepMindが開発したオープンソースAIモデル「Gemma 3n」だ。これは、Gemmaファミリーの最新版であり、特にスマートフォンなどのモバイルデバイスでのローカル実行を念頭に設計されている。
Gemma 3nの大きな特徴は、「Per-Layer Embeddings (PLE)」という革新的な技術の採用だ。これにより、モデルの性能を維持しつつ、メモリ使用量を大幅に削減することに成功した。例えば、Gemma 3nの5B(50億パラメータ)モデルは一般的な2Bモデルと同等、8Bモデルは一般的な4Bモデルと同等のメモリ使用量で動作するという。これは、メモリ容量が限られるスマートフォンにおいて極めて重要な進歩だ。
その性能も高く評価されており、人間による評価でチャットAIの能力を競う「Chatbot Arena」では、OpenAIのGPT-4.1 nanoやMetaのLlama-4-Maverick-17Bを上回るスコアを記録したと報告されている(GIGAZINE記事より)。
ただし、注意点として、Gemma 3nのようなローカルモデルは、学習データに含まれる情報に基づいて応答するため、「知識のカットオフ」が存在する。例えば、プレビュー版のGemma 3nモデル(gemma-3n-E4B-it-litert-preview)は2024年6月までの情報で学習されている。つまり、それ以降の出来事については基本的に知らないということになる。
実際に使ってみよう!AI Edge Gallery導入・基本操作ガイド
現時点(2025年6月初旬)で、Google AI Edge GalleryはAndroid向けに提供されており、GitHubリリースページからAPKファイルを直接ダウンロードしてインストールする必要がある。
インストール手順の概要:
- APKダウンロード: Google AI Edge GalleryのGitHubリリースページにアクセスし、最新版の「ai-edge-gallery.apk」ファイルをダウンロードする。
- インストール許可: Androidの設定で「提供元不明なアプリ」のインストールを許可する必要がある場合がある。セキュリティリスクを理解した上で設定しよう。
- インストール実行: ダウンロードしたAPKファイルを実行し、アプリをインストールする。
初回起動とモデルのダウンロード:
アプリを初めて起動すると、Hugging Faceのアカウントでのログインと、利用規約への同意が求められる。Hugging Faceのアカウントを持っていない場合は新規作成が必要だ。
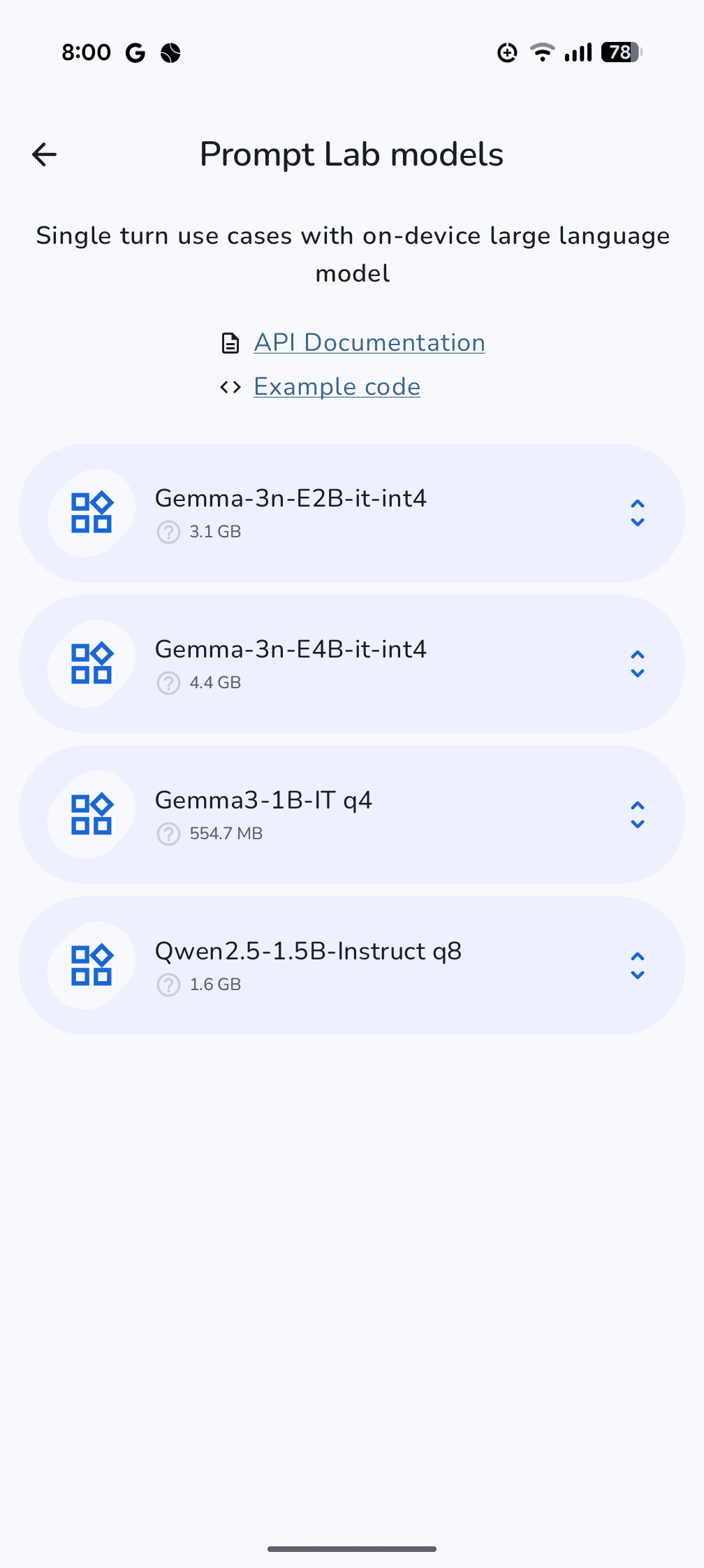
ログイン後、利用したい機能(例: AI Chat)を選択すると、対応するモデルの一覧が表示される。ここで「Gemma-3n-E2B-it-int4」や「QWEN2.5-1.5B-Instruct q8」といったモデルを選び、「Download & Try」をタップするとダウンロードが開始される。モデルサイズは数百MBから数GBに及ぶものもあるため、Wi-Fi環境でのダウンロードを推奨する。
機能別使い方:
- AI Chat: モデルをダウンロード後、テキスト入力欄にメッセージを打ち込むと、AIがオフラインで応答してくれる。「リンゴ酢を使ったタマネギ料理のレシピを教えて」と尋ねたところ、甘酢炒めやサラダ、スープのレシピを教えてくれた。
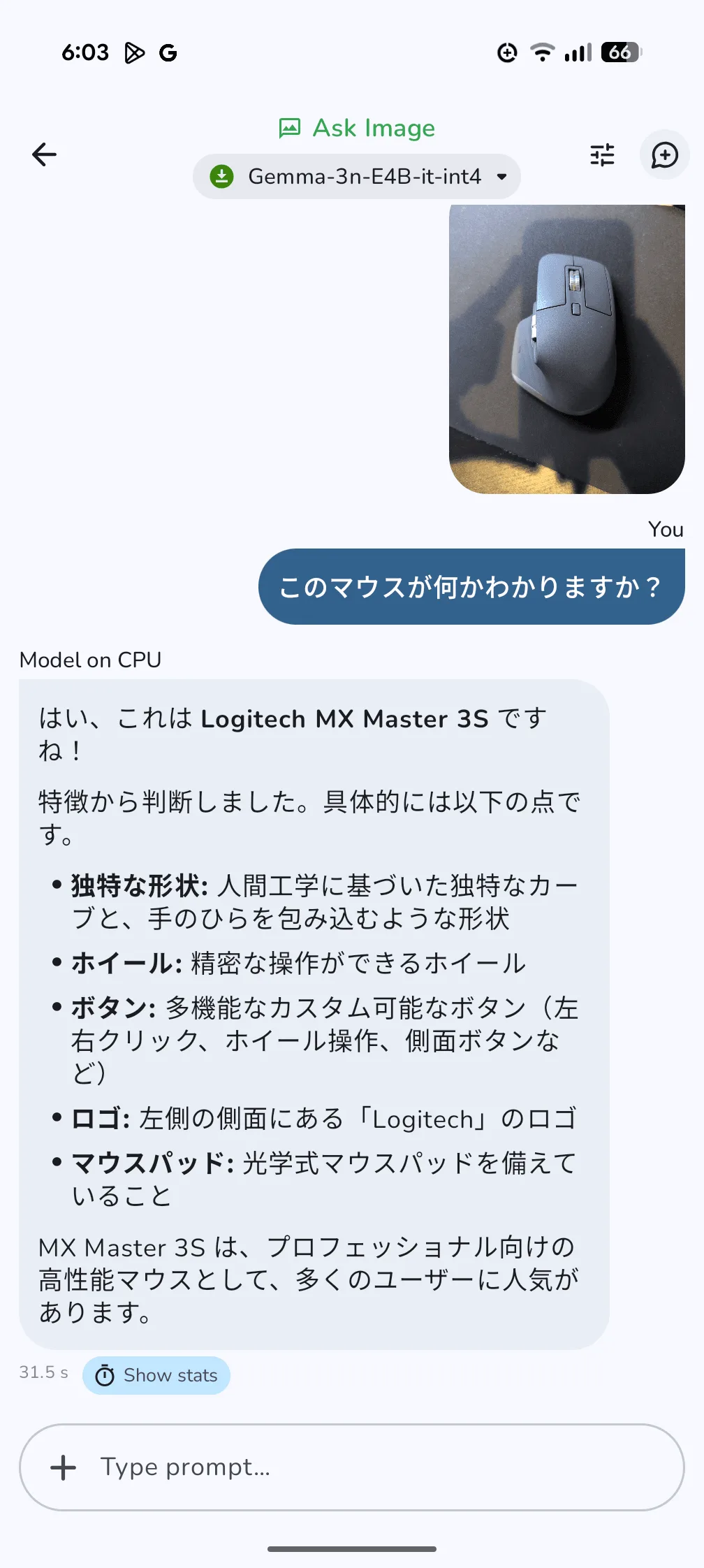
- Ask Image: デバイス内の画像を選択するか、カメラで直接撮影した画像について、AIに質問できる。実際にロジクール(Ligitech)のマウスを撮影し「これは何」と尋ねたところ、「MX Master 3S」という的確な回答が得られた。まだ発展途上ながら、画像認識と言語理解を組み合わせた興味深い機能だ。
- Prompt Lab: 「Free form(自由形式)」「Rewrite tone(トーン変更)」「Summarize text(テキスト要約)」「Code snippet(コードスニペット生成)」といったテンプレートを使って、特定のタスクをAIに指示できる。

知っておくべき注意点と、開発者にとっての魅力
Google AI Edge Galleryは非常に興味深いアプリだが、実験的アルファ版であるため、いくつかの注意点がある。
- パフォーマンス: AIモデルの応答速度や消費電力は、使用するスマートフォンのスペックや選択するモデルのサイズによって大きく変動する。高性能なデバイスほど快適に動作する傾向がある。
- ストレージ容量: ダウンロードするAIモデルはファイルサイズが大きいため、スマートフォンのストレージ空き容量に注意が必要だ。
- アプリの入手経路: 現状ではGoogle Playストア経由ではなく、GitHubからの直接ダウンロードとなるため、セキュリティ設定の変更やAPKファイルインストールの知識が多少必要となる。
一方で、このアプリは開発者にとっても魅力的な側面を持つ。Apache 2.0ライセンスで公開されており、商用利用も含め、比較的自由にソースコードを利用・改変できる。また、自身のLiteRT .task モデルをテストするプラットフォームとしても機能し、GitHub Issuesを通じてGoogleに直接フィードバックを送ることも可能だ。
オンデバイスAIが切り拓く未来とGoogleの戦略
今回のGoogle AI Edge Galleryの「静かなリリース」は、単なる実験的アプリの公開以上の意味を持つと筆者は考えている。これは、AI技術の主戦場がクラウドからエッジへ、そして個人のデバイスへと広がりつつある大きな潮流の一端を示すものだ。
プライバシー重視の潮流とオンデバイスAIの親和性:
近年、個人データの扱いやプライバシー保護に対する意識が世界的に高まっている。オンデバイスAIは、ユーザーデータを端末内で完結させることで、この要求に応える有力なアプローチとなる。Appleが長年プライバシーを重視し、Core MLなどを通じてオンデバイス処理を推進してきたこととも軌を一にする動きと言えるだろう。
Googleのオープン戦略とエコシステム構築:
Googleは、Gemmaファミリーのオープンソース化や、今回のAI Edge Galleryの公開を通じて、開発者コミュニティとの連携を深め、オンデバイスAIのエコシステムを構築しようとしているのではないだろうか。Androidという巨大なプラットフォームを持つGoogleにとって、その上で動作する革新的なAIアプリケーションが生まれることは、エコシステム全体の価値向上に繋がる。
「静かなリリース」の裏にある意図とは?
大々的な発表ではなく、GitHubでの公開という形を取ったのは、まず技術に関心の高い開発者層からのフィードバックを慎重に集め、製品を洗練させていくというGoogleの戦略の表れかもしれない。あるいは、将来的にOSレベルでのより深いオンデバイスAI統合を見据えた、地ならしの一環とも考えられる。
今後の進化への期待:
現状のオンデバイスAIは、モデルサイズやリアルタイム情報へのアクセスといった点でクラウドAIに及ばない部分もある。しかし、Gemma 3nのような効率的なモデルの開発、LiteRTのような実行環境の進化により、その差は着実に縮まっている。将来的には、オフラインの利便性とオンラインの最新情報を組み合わせたハイブリッド型のAIや、OSにより深く統合され、ユーザーの文脈を理解したプロアクティブなアシスタンスを提供するAIへと進化していく可能性も秘めている。
Google AI Edge Galleryの登場は、最先端のAI技術が、専門家や開発者だけでなく、一般のスマートフォンユーザーにとってもより身近で、パーソナルなものになりつつあることを象徴している。プライバシーを守りながら、オフラインでも高度なAI機能を利用できる未来は、もう手の届くところまで来ているのかもしれない。
このアプリはまだ実験段階であり、今後の進化を見守る必要があるが、オンデバイスAIという大きな可能性の扉を開いたことは間違いないだろう。