
Googleが、GmailやYouTube、Google Cloudといった同社の広範なサービスを支える基幹ストレージシステム「Colossus」における、最新のデータ管理戦略を明らかにした。依然として大部分のデータ保管にハードディスクドライブ(HDD)を活用しつつ、独自開発の自動階層化システム「L4」によってソリッドステートドライブ(SSD)を効果的に組み合わせ、コストとパフォーマンスの最適化を図っているという。
Colossus: Googleを支えるエクサバイト級ストレージ基盤
Colossusは、GoogleがYouTube、Gmail、BigQuery、Cloud Storageなど、ほぼすべてのサービスの基盤として使用しているユニバーサルストレージプラットフォームであり、その起源は「Google File System(GFS)」に遡る。Google Cloud Blogによれば、ColossusはGFSを進化させ、ファイルシステムの使いやすさとオブジェクトストレージのスケーラビリティを両立させた「append-only(追記専用)」ストレージシステムとして設計されている。
その最大の特徴は、圧倒的な規模と性能にある。データセンター内のクラスターごとに単一のColossusファイルシステムが構築され、「多くのColossusファイルシステムが数エクサバイト(Exabyte, EB)のストレージ容量を持ち、中にはそれぞれ10エクサバイトを超えるファイルシステムも2つ存在する」という。1エクサバイトは10億ギガバイトに相当する膨大な量であり、これにより、最も要求の厳しいアプリケーションであっても、計算リソースの近くでディスク容量が不足する事態を防いでいる。
性能面でもColossusは驚異的だ。Googleによると、最大規模のファイルシステムでは、「読み取りスループットは常時50TB/s、書き込みスループットは25TB/sを超える」という。これは、「フルレングスの8K映画を毎秒100本以上送信できる」ほどの速度である。また、小さなデータの読み書きも頻繁に行われており、最もビジーな単一クラスターでは、「読み取りと書き込みを合わせて毎秒6億以上のIOPS(Input/Output Operations Per Second、1秒あたりのI/O処理回数)を処理する」としている。
Colossusのメタデータ管理は、「キュレーター(curators)」と「カストディアン(custodians)」と呼ばれるコンポーネントが担う。キュレーターはファイル作成や削除といった対話的な制御操作を扱い、カストディアンはデータの永続性、可用性、ディスクスペースのバランシングを維持する。クライアントはまずキュレーターと対話し、その後「Dサーバー(D servers)」と呼ばれるHDDやSSDを搭載したストレージサーバーに直接データを格納する仕組みだ。
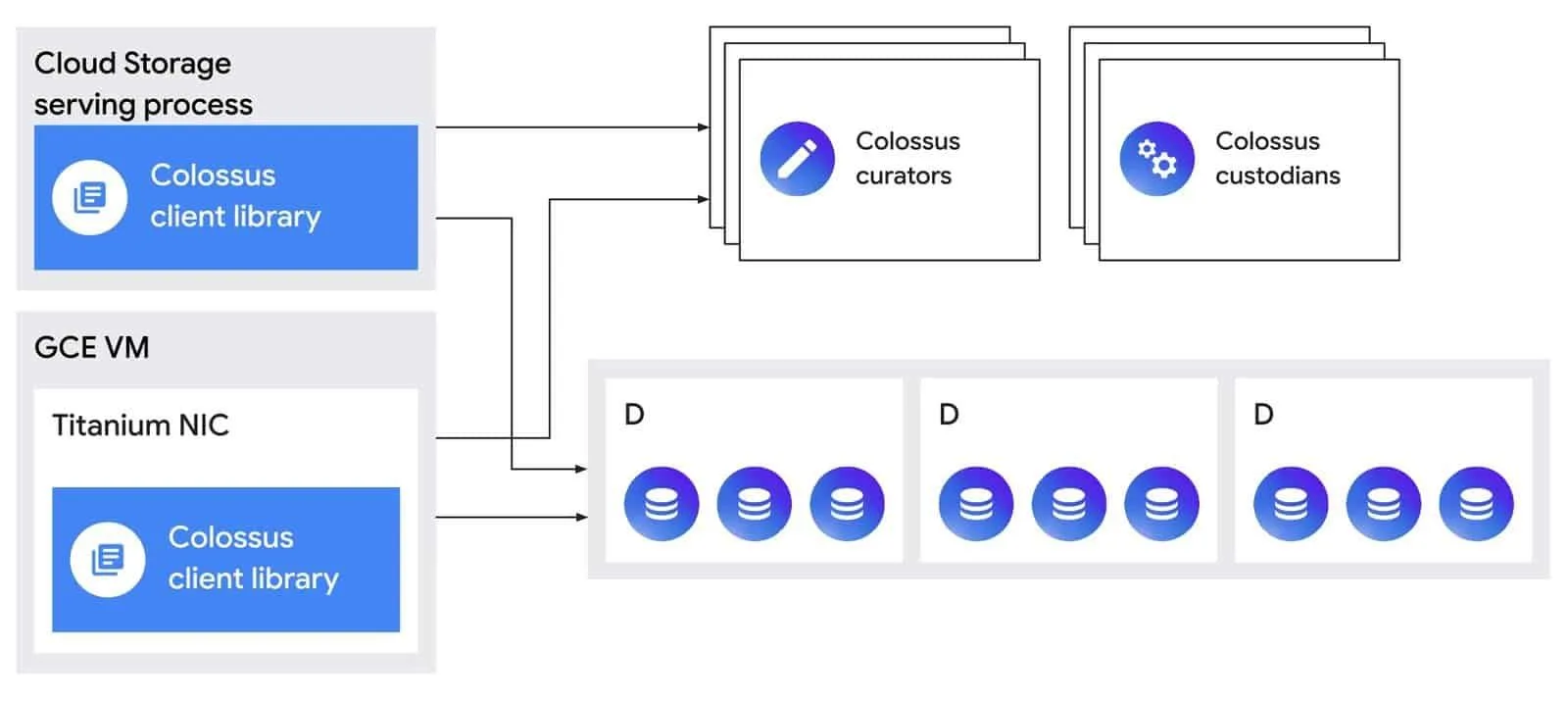
HDDとSSDのジレンマ:コストと性能の最適解を求めて
これほどの性能と規模を誇るColossusだが、そのストレージ構成の大部分は、依然として安価なHDDに依存している。
近年、SSDの価格は下がり、データセンターにおける存在感を増している。SSDはHDDに比べてアクセス速度が格段に速く、低遅延であるため、パフォーマンス向上に不可欠だ。しかし、Google Cloud Blogは「SSDのみのストレージは、SSDとHDDを組み合わせたストレージフリートと比較して、依然として 大きなコストプレミアムがある」と指摘する。
ここに、Googleが直面する課題がある。「最も多くのI/O(入出力)が発生するデータ、あるいは最も低いレイテンシ(遅延)を必要とするデータ」を、いかにして高価なSSD上に配置し、「データの大部分をHDD上に保持する」か。つまり、コストを抑えながら最大限のパフォーマンスを引き出すための、最適なデータ配置戦略が求められているのだ。
鍵を握る自動階層化技術「L4」
この課題に対するGoogleの回答が、独自開発の自動階層化システム「L4」である。L4は、データへのアクセスパターンを分析し、どのデータをSSDに配置するのが最適かを動的に判断する役割を担う。Google Cloud Blogによると、L4は主に「リードキャッシュ」と「ライトバックキャッシュ」という2つの機能を通じて、データ配置を自動化している。
L4リードキャッシュ:頻繁に読まれるデータを高速化
L4がリードキャッシュとして機能する場合、アクセス頻度の高いデータをHDDからSSD上のキャッシュ領域にコピーする。アプリケーションがデータを読み込もうとすると、まず「L4インデックスサーバー」に問い合わせる。インデックスサーバーは、要求されたデータがSSDキャッシュ内に存在するかどうか(キャッシュヒット)をクライアントに通知する。
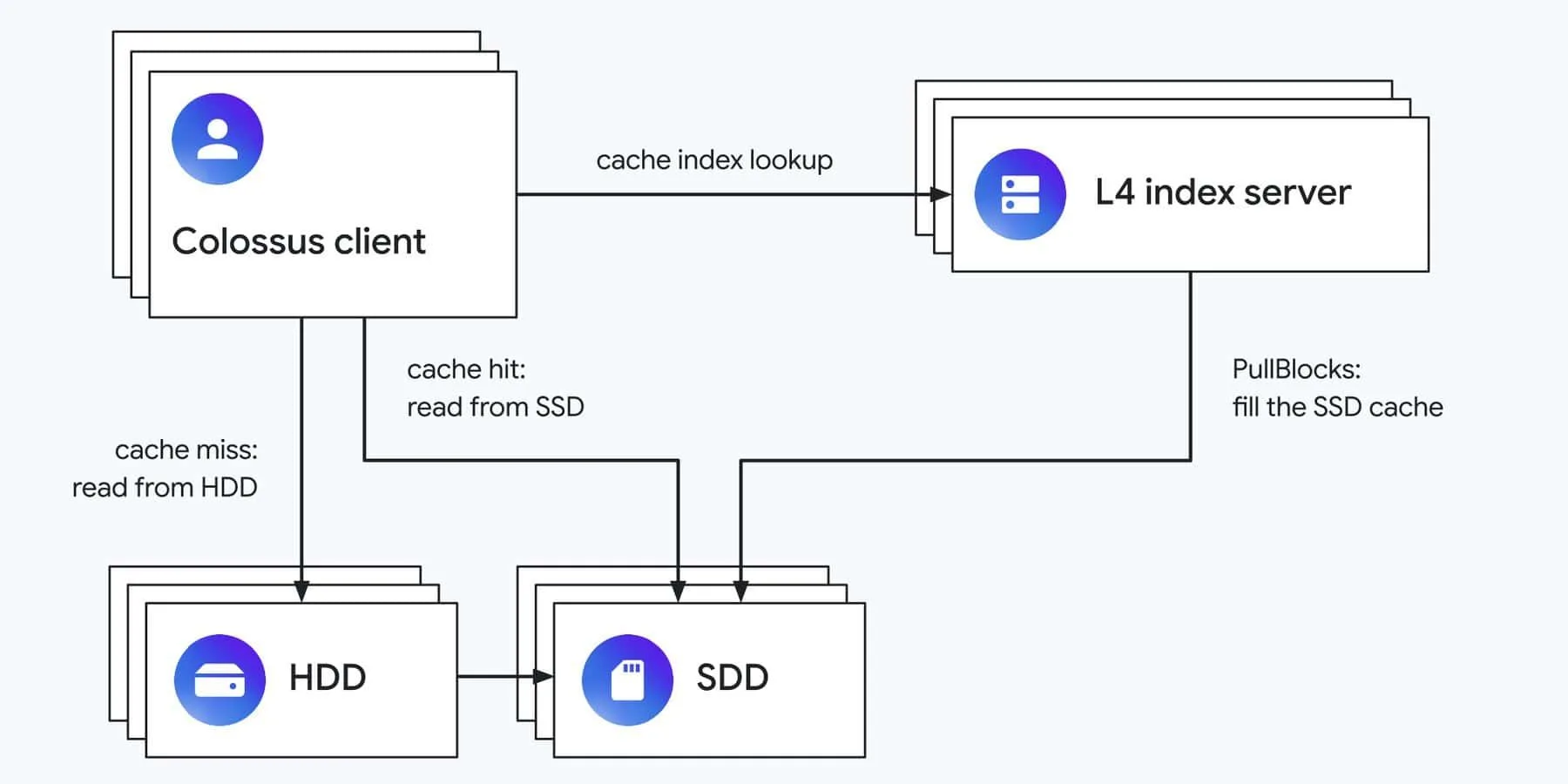
キャッシュヒットの場合、クライアントは高速なSSDからデータを読み込む。一方、キャッシュミス(データがキャッシュにない)の場合、クライアントはHDDからデータを読み取る。この際、L4は「アクセスされたデータをSSDキャッシュに挿入する」判断を下すことがある。キャッシュがいっぱいになると、L4は一部の古いアイテムを削除し、新しいデータを格納するためのスペースを確保する。
どのデータをキャッシュに入れるか、どのタイミングで入れるかについては、「機械学習(ML)を活用したアルゴリズム」が用いられる。Googleによれば、このアルゴリズムはワークロードごとに、「データが書き込まれた時」「最初に読み取られた後」「短期間に2回読み取られた後」といった異なるポリシーの中から最適なものを選択する。このリードキャッシュ技術は、「同じデータを頻繁に読み取るアプリケーションでうまく機能し、IOPSとスループットを劇的に改善した」という。
しかし、このリードキャッシュには「大きな弱点」がある。それは、「新しいデータは依然としてHDDに書き込まれる」点だ。
L4ライトバックキャッシュ:書き込みと短命データへの対応
リードキャッシュの弱点を補い、さらに効率化を進めるのがL4のライトバックキャッシュ機能だ。これは、特定の種類のデータ、特に「書き込まれてすぐに読み取られ、削除されるデータ(大規模バッチ処理ジョブの中間結果など)」や、「データベースのトランザクションログなど、小さな追記が頻繁に行われるファイル」を、最初からSSDに書き込むことを目的としている。これらのワークロードはHDDには不向きであり、「直接SSDに書き込み、HDDを完全にスキップすることが望ましい」とGoogleは述べている。
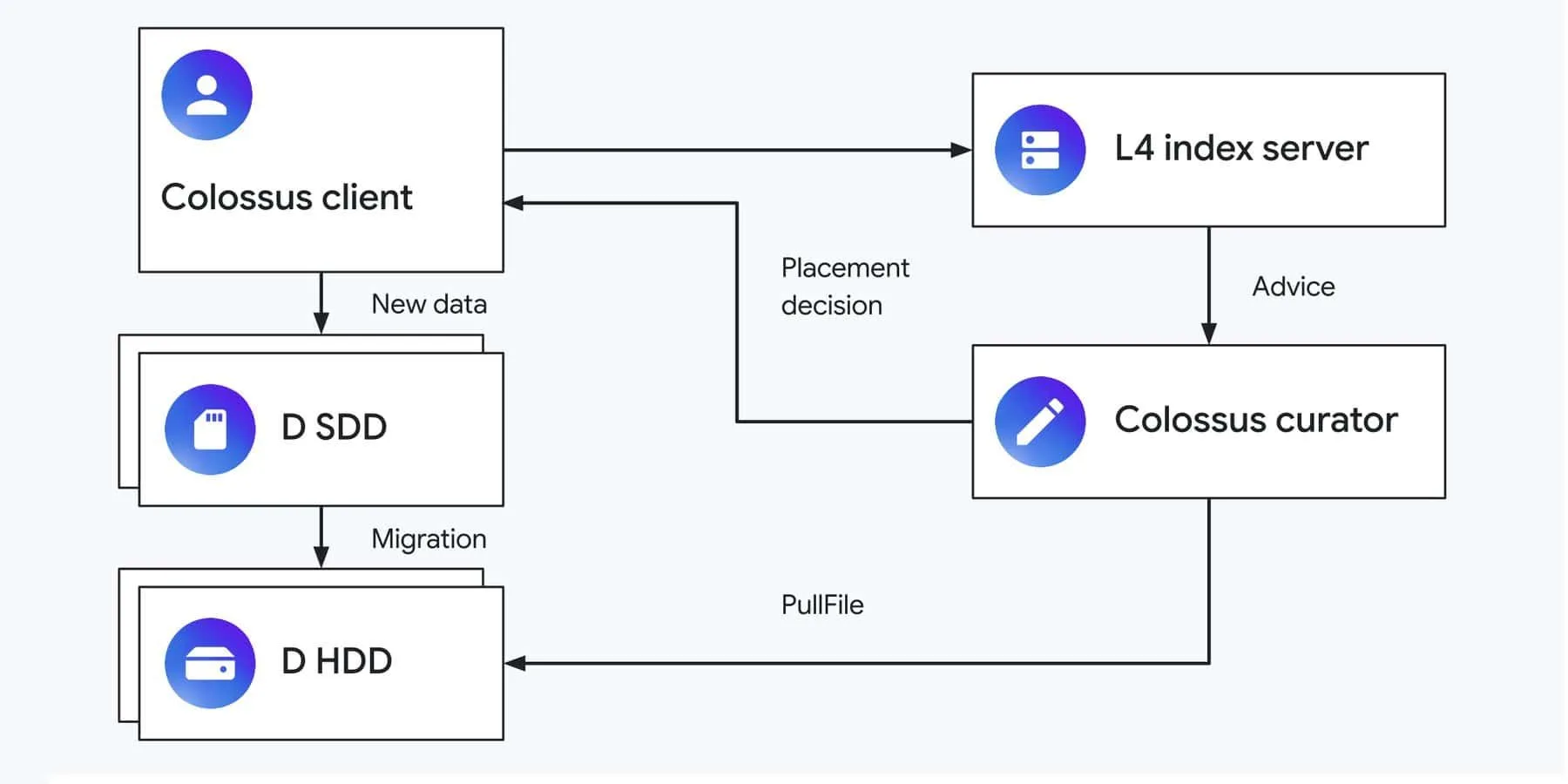
ライトバックキャッシュでは、ファイルが作成される時点で、どのストレージ(SSDかHDDか)に、どのくらいの期間配置すべきかをL4が判断し、Colossusのキュレーターに指示を出す。ファイル作成時には将来のアクセスパターンは不明なため、L4はアプリケーションから渡される「ファイルタイプ」や「データベースカラムに関するメタデータ」といった「特徴量(features)」を利用する。
これらの特徴量に基づき、L4はファイルを「カテゴリ」に分類し、各カテゴリのI/Oパターンを時系列で観察する。そして、「1時間SSDに配置」「2時間SSDに配置」「SSDに配置しない」といった様々な配置ポリシーについて、「オンラインシミュレーション」を実行する。このシミュレーション結果に基づき、L4は各カテゴリに最適なポリシーを選択する。
シミュレーションがファイルアクセスパターンを正確に予測した場合、「データのごく一部をSSDに配置し、それが(新規作成ファイルに多い)読み取りの大部分を吸収し、その後データをより安価なストレージ(HDD)に移行させることで、全体的なコストを最小限に抑える」ことが可能になる。最良のケースでは、「ファイルがHDDに移行される前に削除され、HDDのI/Oを完全に回避できる」という。
さらに、このオンラインシミュレーションは、「もしSSDの容量がもっと多い、あるいは少ない場合に、L4がどのような配置を選択するか」も予測できる。これにより、「異なる量のSSDで、どれだけのI/OをHDDからオフロードできるか」を予測でき、これらの情報は「新しいSSDハードウェアの購入判断や、効率を最大化するためにアプリケーション間でSSD容量をシフトする方法を計画者に知らせる」上で役立っている。
L4の限界と今後の展望
L4システムは、Googleの巨大なストレージインフラにおけるHDDとSSDのバランスをとる上で重要な役割を果たしているが、万能ではない。The Registerは、L4リードキャッシュが「書き込まれてすぐに読み取られ、削除されるデータ」や「小さな追記が多いファイル」のような特定のワークロードに対しては、期待されるほどリソース削減効果が高くない可能性がある点を指摘している。L4ライトバックキャッシュはこれらの課題に対処するために導入されたものと考えられるが、その有効性の度合いについては、さらなる情報公開が待たれる。
Googleは、ColossusとL4の技術を、同社のクラウドサービスにも応用している。Google Cloud Blogでは、Hyperdisk ML、Spannerの階層型ストレージ、Cloud StorageのSSDキャッシュ、BigQueryの高速ストレージなどが、Colossusの恩恵を受けている例として挙げられている。
Googleは、「エンドユーザーがHDD、SSD、Colossusのあらゆる詳細について専門家である必要なく、ストレージの効率とパフォーマンスを最大化すること」を目指しており、「これまでに構築したシステムに誇りを持っていると同時に、規模、洗練度、パフォーマンスの向上に引き続き取り組んでいく」と述べている。
ストレージハードウェアベンダー各社もSSDとHDDの最適なブレンド方法を競っているが、Googleのようなエクサバイト規模での運用はまた別の次元の課題を伴う。Googleは、2025年4月に開催される「Google Cloud Next ’25」カンファレンスで、ストレージシステムに関するさらなる情報を公開する予定であり、「What’s new with Google Cloud’s Storage」や「AI Hypercomputer: Mastering your Storage Infrastructure」といったセッションで詳細が語られる見込みだ。巨大テック企業がどのようにして膨大なデータを効率的に管理しているのか、その進化から目が離せない。
Sources


