
もしAIが、私たち人間や動物が当たり前のように持つ『世界の常識』を、まるで直感のように理解し、次に何が起こるかを予測し、自ら最適な行動を計画できたらどうだろうか? 膨大なデータを学習してもなお、現実世界の複雑な物理法則や因果関係の理解に課題を抱えていたAIのフロンティアに、Metaが新たな一歩を踏み出した。同社が発表した次世代世界モデル「V-JEPA 2」は、まさにAIの「思考」を再定義する画期的な技術であり、ロボットの行動から動画編集まで、私たちのデジタルと物理世界との関わり方を根本から変える可能性を秘めたものだ。
なぜ今「世界モデル」が重要なのか?
世界モデルとは、平たくで言えば「物理世界の法則を内部にシミュレートする能力を持つAI」のことだ。MetaのチーフAIサイエンティストであり、この分野の第一人者であるYann LeCun氏は、これを「AIが世界を理解し、自らの行動がどのような結果を招くかを予測するための、現実の抽象的なデジタルツイン」と表現している。
これは、人間や動物がごく自然に行っていることに近い。例えば、私たちはボールを投げれば放物線を描いて落ちることを知っているし、視界から物が隠れてもそれが消滅したわけではないと理解している。こうした物理的な「常識」を、AIがデータから自律的に学習しようというのが世界モデルの狙いだ。
V-JEPA 2は、この世界モデルを、特に「動画(Video)」から学習することに特化している。そのアーキテクチャの根幹には、JEPA(Joint Embedding Predictive Architecture)という思想がある。これは、動画の次のフレームをピクセル単位で完璧に予測するような、計算コストが高く非効率な手法とは一線を画す。そうではなく、動画の重要な特徴を捉えた「抽象的な表現空間」で、一部が隠された情報を予測する。これにより、木の葉一枚一枚の揺れのような予測困難なディテールは無視し、物体の動きといった本質的な変化の予測に集中できるのである。
このアプローチにより、V-JEPA 2は、まるで幼い子供が世界を観察して常識を身につけていくように、物理法則の基礎を効率的に学習していくのだ。
「観察」と「実践」のハイブリッド学習:V-JEPA 2の革新性
V-JEPA 2の真の革新性は、そのユニークな2段階の学習プロセスにある。これは、ロボットAI開発におけるスケーラビリティとコストという長年の課題に対する、極めてクレバーな解答と言えるだろう。
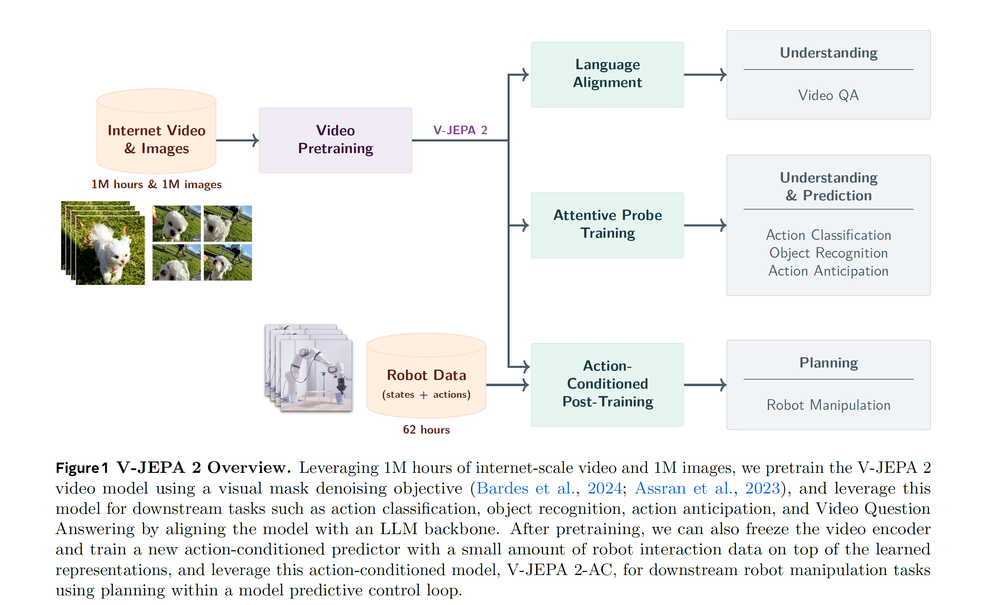
フェーズ1:100万時間の「観察」による一般知識の獲得
まずV-JEPA 2は、YouTubeなどに存在する100万時間以上もの膨大なインターネット動画を「観察」する。この段階では、特定のタスクや行動のラベルは一切与えられない。いわゆる「自己教師あり学習」によって、AIはただひたすらに動画を観続け、世界で物がどのように動き、相互作用するかの一般的なパターン、つまり物理法則の素地を学ぶ。これが、安価で大量に手に入るWebデータを活用した、知識の土台作りである。
フェーズ2:わずか62時間の「実践」による行動の学習
次に、この広範な一般知識を持つモデル(V-JEPA 2)に対し、ロボットのデータセット(Droidデータセット)を用いたファインチューニングが行われる。ここで重要なのは、そのデータ量がわずか「62時間」であることだ。この段階で、AIは初めて「自分の行動(アームの動きなど)」が「世界にどのような変化(物体が動くなど)」をもたらすかを学習する。
このハイブリッドアプローチの戦略的価値は計り知れない。ロボットを実際に動かしてデータを収集するのは非常に高コストで時間もかかる。V-JEPA 2の手法は、その高コストな「実践」の量を最小限に抑え、知識の大部分を低コストな「観察」で賄うことを可能にする。これは、ロボットAIの開発を、一部の研究室レベルから、業界全体でスケールさせるための重要なブレークスルーとなりうる。
驚異のゼロショット性能:未知の環境でタスクをこなすロボット
この学習手法がもたらした成果は、実に衝撃的だ。研究論文では、V-JEPA 2をベースに、行動を条件付けしたモデル「V-JEPA 2-AC」を実際のロボットアーム(Franka arm)に搭載した実験が報告されている。
その結果は驚くべきものだった。V-JEPA 2-ACは、学習データには含まれていない全く新しい研究室の環境で、見たことのない物体を掴んで移動させる「ピック・アンド・プレイス」といったタスクを成功させた。
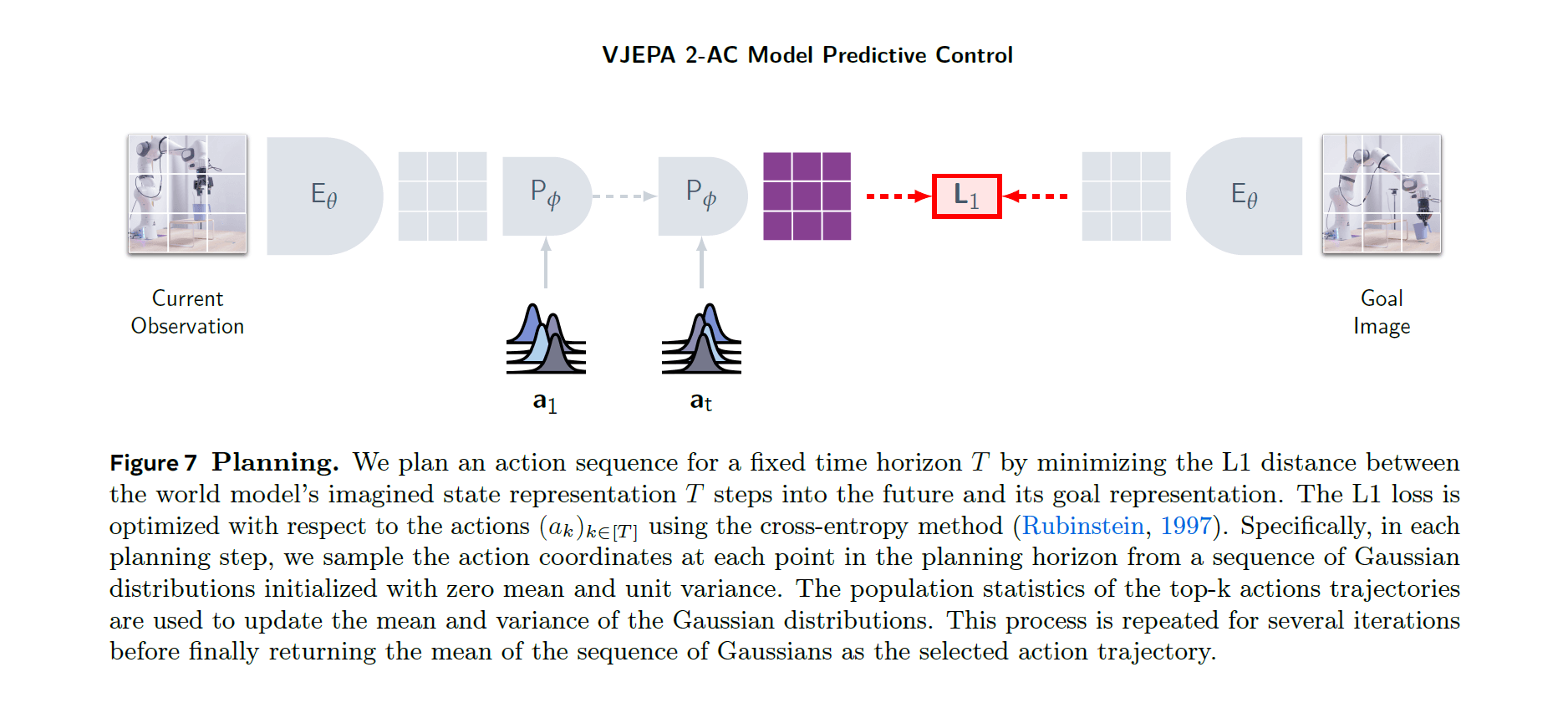
これは「ゼロショット」での達成である。ゼロショットとは、その新しい環境やタスクに対して、一切の追加学習やファインチューニングを行わないことを意味する。AIは、事前に学習した世界の仕組みに関する一般知識と、基本的な行動の知識だけを頼りに、目標(ゴールとなる画像)を与えられるだけで、未知の状況で何をすべきかを「計画」し、実行できたのだ。
これは、これまでのロボットAIの常識を覆すものだ。従来、ロボットに新しいタスクを教えるには、そのタスク専用の大量のデモンストレーションデータや、複雑な報酬設計が必要だった。V-JEPA 2は、そうしたタスク固有の教え込みを不要にし、より汎用的な知能への道筋を示したのである。
さらに、その性能は他のベンチマークでも証明されている。
- モーション理解: 人間の複雑な動作を分類する「Something-Something v2」データセットで77.3%という高い精度を達成。
- 人間行動予測: 料理中の次の行動を予測する「Epic-Kitchens-100」では、従来モデルを44%も上回る世界最高性能(SOTA)を記録した。
これらの結果は、V-JEPA 2が単にロボットを動かせるだけでなく、我々の世界で起こる出来事を深く理解し、予測する能力を持つことを示している。
言語モデルの先へ:なぜ今「世界モデル」が覇権争いの焦点なのか?
このMetaの発表を、単一企業の技術成果として見るのは早計だ。これは、AI業界全体の大きな地殻変動の兆候と捉えるべきである。
現在のAIブームを牽引する大規模言語モデル(LLM)は、テキストや画像を生成する能力においては驚異的な進化を遂げた。しかし、それらは物理世界に直接介入する「身体」を持たない。これがLLMの根源的な限界であり、AI開発の次なるフロンティアが「物理世界とのインタラクション」にあるとされる所以だ。
そして、このフロンティアの覇権を巡る競争は、すでに始まっている。
- Google DeepMindは、ゲーム環境をシミュレートできる世界モデル「Genie」を開発。
- NVIDIAは、産業用メタバースの基盤として、物理シミュレーションエンジン「Omniverse」を強力に推進。
- 著名なAI研究者であるFei-Fei Li氏も、「大規模世界モデル」の開発を目指すスタートアップ「World Labs」を立ち上げた。
まさに、巨大テック企業が次なるAIの聖杯として「世界モデル」に殺到している構図だ。言語モデルの戦いでOpenAIやGoogleに一定のリードを許したMetaにとって、この物理世界モデルの領域は、AI覇権のチェス盤で巻き返しを図るための最重要拠点なのである。
V-JEPA 2が拓く未来と残された課題
世界モデルが成熟した先には、どのような未来が待っているのだろうか。
- 家庭用・産業用ロボットの進化: 指示されたタスクをこなすだけでなく、予期せぬ状況にも柔軟に対応できる、真に賢いロボットが登場するだろう。床にこぼれたジュースを認識し、自分で拭き方を考えて実行するようなロボットが現実のものとなるかもしれない。
- 自動運転の高度化: 物理的な常識を持つAIは、前方の車が急ブレーキをかける可能性や、道路脇から子供が飛び出してくる危険性などを、より人間らしく予測できるようになる。これにより、安全性は飛躍的に向上する可能性がある。
- AR/VRとの融合: Meta自身の悲願であるメタバースにおいても、世界モデルは鍵となる。現実世界と見分けがつかないほどリアルな物理シミュレーションは、これまでにない没入感を持つ仮想空間や、より効果的なトレーニングシミュレーターを生み出すだろう。
もちろん、道はまだ半ばだ。論文でも指摘されているように、数秒先ではなく、より長期的な行動計画を立てる能力や、ゴールを画像ではなく「言語」で与える能力など、解決すべき課題は山積している。
しかし、V-JEPA 2が示した「観察からの学習」というアプローチは、AIが言語という仮想空間から、我々が住む物理世界へと降り立つための、力強く、そして極めて重要な一歩であることは間違いない。言語をマスターしたAIが、次に物理世界をマスターしたとき、私たちの社会は、想像を超えるほどの大きな変容を遂げることになるだろう。その未来の扉を、Metaが静かに、しかし確実にこじ開けた。それがV-JEPA 2の持つ、真のインパクトなのである。
Sources