
NVIDIAの最新AIチップ「Blackwell」が、業界標準の機械学習ベンチマーク「MLPerf Training v5.0」において、その圧倒的な性能を改めて証明した。特に、最も要求の厳しい大規模言語モデル(LLM)のトレーニングタスクで他を寄せ付けない結果を示し、AIインフラにおける同社のリーダーシップを強固なものにしている。しかし、その影ではAMDが着実に実力を高めており、AIの進化に伴うエネルギー消費という喫緊の課題もまた、浮き彫りになっている。
Blackwellが君臨するAIトレーニングの最前線 – MLPerf最新結果詳報
AIの性能を客観的に評価する指標として広く認知されているMLPerf。その最新ラウンド(v5.0)において、NVIDIAのBlackwellアーキテクチャは、まさに「王者の風格」を見せつけたと言えるだろう。NVIDIAおよびそのパートナー企業は、LLM、推薦システム、マルチモーダルLLM、物体検出、グラフニューラルネットワークといった、AIの主要なワークロード全てにおいて最高性能を叩き出した。
特筆すべきは、今回から新たに追加されたMeta社の「Llama 3.1 405B」モデルのプリトレーニング(事前学習)ベンチマークだ。これは、従来のGPT-3ベースのモデルよりも2倍以上のパラメータ数を持ち、コンテキストウィンドウ(一度に処理できるテキスト量)も4倍に拡大された、現行で最も計算資源を要求するタスクの一つである。この最難関ベンチマークにおいて、NVIDIAのBlackwellプラットフォームは他社の追随を許さず、全ての提出結果を独占した。
NVIDIAでアクセラレーテッドコンピューティング製品担当ディレクターを務めるDave Salvator氏は、「AIの性能評価は時に『ワイルドウェスト(無法地帯)』のようになりがちですが、MLPerfはその混沌に秩序をもたらそうとしています。これは簡単なことではありません」と、MLPerfの意義を強調する。同氏によれば、今回のBlackwellの成果は、製品ライフサイクルのまだ初期段階のものであり、今後のソフトウェア最適化によってさらなる性能向上が期待できるという。
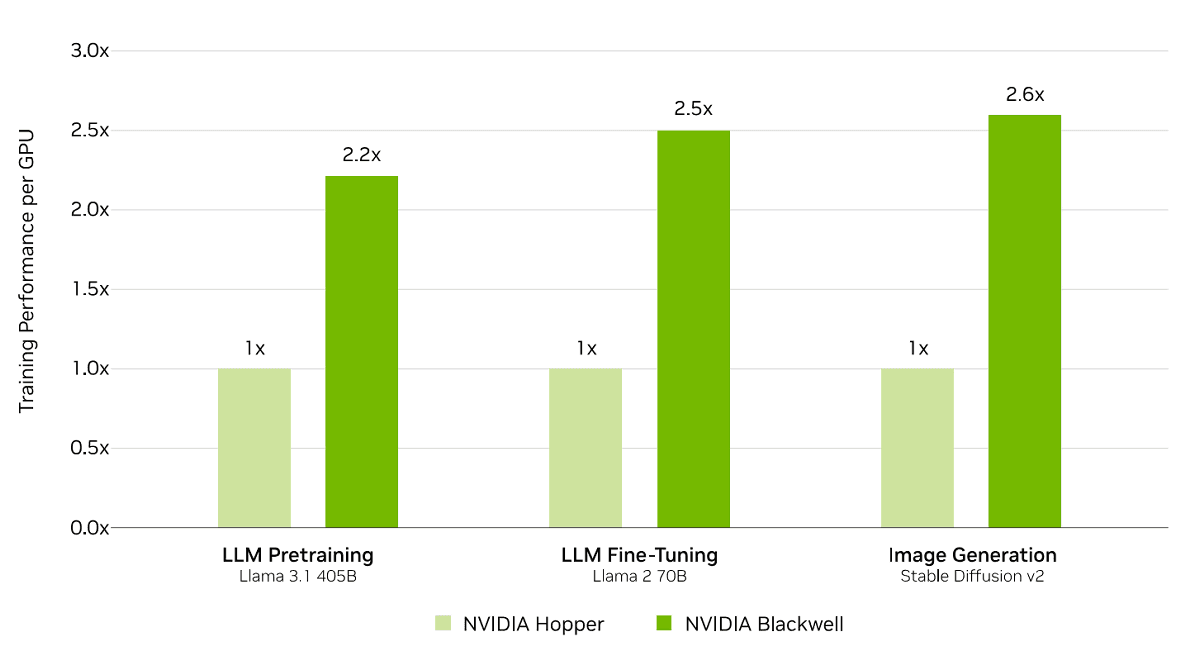
具体的には、Blackwellを搭載したNVIDIA GB200 NVL72ラック規模システム「Tyche」や、NVIDIA DGX B200システム「Nyx」などが用いられ、旧世代のHopperアーキテクチャと比較して、Llama 3.1 405Bプリトレーニング(同規模構成)で2.2倍、Llama 2 70B LoRAファインチューニング(8GPU構成)では2.5倍という目覚ましい性能向上を達成している。これらの飛躍は、高密度液冷ラック、ラックあたり13.4TBのコヒーレントメモリ、第5世代NVIDIA NVLinkおよびNVLink Switch、そしてNVIDIA Quantum-2 InfiniBandネットワーキングといったBlackwellアーキテクチャの革新技術と、NVIDIA NeMo Frameworkなどのソフトウェアスタックの進化によって実現されたものだ。
AMDの猛追 – MI325XがH200に肉薄、しかしBlackwellの背中は遠いか
NVIDIAの独壇場とも見えるAIチップ市場だが、最大のライバルであるAMDも着実にその存在感を増している。今回のMLPerf Trainingでは、AMDが初めて自社で結果を提出(過去には他社がAMD GPUを使用したシステムを提出した例はある)。その最新GPU「Instinct MI325X」が、最も一般的なLLMファインチューニングのベンチマークにおいて、NVIDIAの前世代ハイエンドモデルであるH200に匹敵する性能を示したことは注目に値する。
MI325Xは、前モデルMI300Xと比較して高帯域幅メモリ(HBM)を30%増量しており、これが性能向上に寄与したと考えられる。実際に、MI300X比で約30%の性能改善が見られたという。

しかし、IEEE Spectrum誌は、この結果をもって「AMDはNVIDIAに1世代遅れている」と示唆している。BlackwellがH200を大幅に上回る性能を示している現状を鑑みれば、MI325XがH200と同等ということは、Blackwellにはまだ及ばないという見方もできるだろう。AMDがNVIDIAとの差をどこまで詰められるのか、今後の開発競争から目が離せない。
一方で、Googleは独自のAIアクセラレータ「Trillium TPU」の第6世代モデルで、画像生成タスクのみに結果を提出した。その性能は注目されるものの、提出範囲が限定的であったため、NVIDIAやAMDとの総合的な比較は難しい状況だ。
大規模AIを支える至高の技術 – ネットワーキングの重要性がかつてなく高まる
LLMの巨大化に伴い、数千、数万という単位のGPUを連携させて処理を行う「大規模並列コンピューティング」が不可欠となっている。このような環境では、個々のGPU性能だけでなく、GPU間のデータ転送速度や効率性、すなわちネットワーキング技術がシステム全体の性能を左右する極めて重要な要素となる。
理想的には、GPUの数を増やせば処理時間はその数に反比例して短縮されるはずだが、実際にはGPU間の通信によるオーバーヘッドが発生するため、効率は必ず低下する。この損失をいかに最小限に抑えるかが、大規模モデルを効率的に学習させる鍵となる。
今回のMLPerfで、NVIDIAは最大8,192基のGPUを使用したシステムを提出した。NVIDIAのSalvator氏は、この規模での高いスケーリング効率(理想性能の90%を達成)の要因として、36基のGrace CPUと72基のBlackwell GPUをNVLinkで接続し、あたかも「単一の巨大なGPU」のように動作させる「NVL72」パッケージと、複数のNVL72システム間を接続するInfiniBandネットワーク技術の組み合わせを挙げている。
興味深いことに、Hewlett Packard EnterpriseのプリンシパルAI・機械学習エンジニアであるKenneth Leach氏は、今回のMLPerfでの最大GPU数が過去のラウンド(10,000基超)よりも減少した点について、GPU自体の性能向上とネットワーキング技術の改善により、より少ないサーバーノード数で同等以上の処理が可能になったためではないかと分析している。「以前はLLMのプリトレーニングに16のサーバーノードが必要でしたが、現在は4ノードで可能です。これが、巨大システムがあまり見られなくなった理由の一つだと考えています」と同氏は語る。
ネットワーキングのオーバーヘッドを回避する別のアプローチとして、Cerebras Systemsのように、ウエハー上に巨大な単一チップを形成する「ウエハー・スケール・エンジン」も存在する。同社は最近、推論タスクにおいてNVIDIA Blackwellを2倍以上上回る性能を達成したと主張しているが、これはMLPerfのような厳密な条件下での比較ではなく、第三者機関(Artificial Analysis)が異なるプロバイダーの環境で測定したものであり、単純な「りんごとりんご」の比較は難しい点に留意が必要だ。
見過ごせない「電力という名の巨人」 – AIのエネルギー消費問題
AI技術の目覚ましい進歩の裏で、その膨大なエネルギー消費に対する懸念が日増しに高まっている。今回のMLPerfでは、学習タスクを達成するために消費された電力量を測定する「パワーテスト」も実施されたが、驚くべきことに、Lenovo1社のみがこの電力測定結果を提出した。
Lenovoの提出によれば、2基のBlackwell GPUでLLMをファインチューニングするのに要したエネルギーは6.11ギガジュール、すなわち1,698キロワット時であったという。これは、おおよそ小さな家一軒の冬の暖房に必要なエネルギー量に匹敵する。
AIの学習と運用にかかる環境負荷は、今後ますます重要な検討事項となるだろう。IEEE Spectrumが指摘するように、この分野における透明性を高めるため、より多くの企業が将来のMLPerfラウンドで電力消費データを提出することが強く望まれる。AIの恩恵を社会全体が持続的に享受するためには、性能追求とエネルギー効率のバランスをどう取るかという、困難だが避けては通れない課題に、業界全体で取り組む必要があるのではないだろうか。
NVIDIAが見据える未来 – 「AI工場」構想とエコシステムの拡大
NVIDIAは、自らを単なるチップメーカーではなく、AIインフラ全体を提供する企業へと変貌させつつある。同社CEOのJensen Huang氏が提唱する「AI工場(AI Factories)」というコンセプトは、その戦略を象徴している。AI工場とは、データを投入すれば知能(トークンや洞察)を生成する、いわば「知の生産拠点」であり、あらゆる産業や学術分野に応用可能な価値を生み出すエンジンのことだ。
NVIDIAのプラットフォームは、GPU、CPU、高速ファブリック、ネットワーキングといったハードウェアだけでなく、CUDA-Xライブラリ、NeMo Framework、TensorRT-LLM、Dynamoといった広範なソフトウェア群を含む、高度に調整された統合システムとして提供される。これにより、企業や研究機関はモデルの学習と展開を迅速化し、価値実現までの時間を大幅に短縮できるとNVIDIAは主張する。
今回のMLPerfにおけるNVIDIAの成功は、こうしたハードウェアとソフトウェアの垂直統合戦略の賜物と言えるだろう。さらに、NVIDIAはCoreWeaveやIBMとの協業に加え、ASUS、Cisco、Dell Technologies、Google Cloud、Hewlett Packard Enterprise、Lambda、Lenovo、Oracle Cloud Infrastructure、Quanta Cloud Technology、Supermicroといった多数のパートナー企業とのエコシステムを拡大し、その影響力を強めている。
AIの進化は止まらない、しかし課題との向き合い方が問われる時代へ
NVIDIA Blackwellの登場は、AIトレーニングの性能を新たな次元へと引き上げた。MLPerfの結果は、その圧倒的な実力を裏付けるものであり、当面の間、NVIDIAの優位は揺るがない可能性が高い。しかし、AMDの着実な追い上げや、Google、Cerebrasといったプレイヤーの動向も注視が必要であり、競争こそが技術革新を加速させる原動力であることは間違いない。
一方で、AIの進化が加速すればするほど、そのエネルギー消費という「諸刃の剣」がより鋭利な問題として我々の前に立ちはだかる。技術の進歩は素晴らしいが、それが地球環境や社会システムに与える影響を考慮しない「進歩のための進歩」は、持続可能とは言えないだろう。MLPerfのようなベンチマークが、今後は電力効率も主要な評価軸としてより重視されるようになることを期待したい。
AIは今、まさに産業革命にも匹敵する変革を社会にもたらそうとしている。その中心で輝きを放つNVIDIA Blackwell。その光が、持続可能で豊かな未来を照らし出すものとなるか、それとも克服すべき新たな課題を浮き彫りにするのか。テクノロジー業界に関わる者として、そして一人の人間として、その行方を冷静に見守り、建設的な議論を続けていく必要がある。AIの未来は、技術者だけでなく、私たち一人ひとりの選択にかかっているのかもしれない。
Sources
- NVIDIA: NVIDIA Blackwell Delivers Breakthrough Performance in Latest MLPerf Training Results
- AMD: AMD Expands AI Momentum with First MLPerf Training Submission
- MLPerf: New MLCommons MLPerf Training v5.0 Benchmark Results Reflect Rapid Growth and Evolution of the Field of AI
- IEEE Spectrum: Nvidia’s Blackwell Conquers Largest LLM Training Benchmark

