
現代社会が直面する最も困難な課題の多くは、膨大な選択肢の中から「最適」な答えを見つけ出すという、一見単純ながらも計算機科学的には極めて難解な問題に集約される。新薬開発におけるタンパク質の構造予測、物流ネットワークの最適化、暗号解読、あるいは金融ポートフォリオの構築。これらの問題は、要素が増えるごとに解の候補が指数関数的に増大し、現在のスーパーコンピュータや、開発途上の量子コンピュータですら処理が追いつかない「組み合わせ爆発」の壁に突き当たっている 。
このような状況の中、カナダのクイーンズ大学のBhavin Shastri准教授(Canada Research Chair in Neuromorphic Photonic Computing)率いる研究チームは、従来の電子回路や超伝導量子ビットに代わり、「光」そのものの物理的特性を利用して複雑な計算を高速に解く、画期的な「光電子発振器(OEO)ベース・イジングマシン」を開発した 。
このマシンは、既存の光通信インフラで用いられている市販のハードウェアで構成され、室温で動作しながら、数時間にわたる高い安定性を維持するという、実用化に向けた決定的な進歩を遂げている 。
100年前の物理モデルが導く「計算の近道」
今回発表された技術の中核にあるのは、物理学において約1世紀前に提唱された「イジングモデル(Ising model)」という概念である 。
イジングモデルとは何か
イジングモデルは元々、磁性体における微小な磁石(スピン)の振る舞いを研究するために開発されたモデルである。個々のスピンは「上」または「下」の2つの状態のいずれかをとり、隣接するスピン同士は互いに影響を及ぼし合う。物理システムにおいて、これら無数のスピンが相互作用を通じて最終的に落ち着くのは、システム全体のエネルギーが最小となる「基底状態」である 。
興味深いことに、多くの実世界における最適化問題は、このイジングモデルのエネルギー関数(ハミルトニアン)にマッピング(翻訳)することが可能だ 。つまり、問題をスピンの相互作用として表現し、物理法則に従ってそのエネルギーが最小となる状態を見つけ出すことができれば、それがそのまま複雑な最適化問題の「最適解」となるのである 。
イジングマシンというアプローチ
イジングモデルを用いて計算を行う専用ハードウェアを「イジングマシン」と呼ぶ。従来のコンピュータ(フォン・ノイマン型)が論理ゲートを用いて一つずつ計算を積み上げるのに対し、イジングマシンは物理系そのものが安定状態へと収束するダイナミクスを直接利用する 。
しかし、これまで提案されてきたイジングマシン、特に量子アニーリングマシン(D-Waveなど)は、極低温の冷却環境が必要であったり、スピン同士の接続性(Connectivity)に物理的な制約があったりするなど、スケーラビリティと実用性の面で大きな課題を抱えていた 。クイーンズ大学の研究チームが挑んだのは、これらの制約を「光」の力で打破することであった。
アーキテクチャ:光通信技術を計算エンジンへ転換
研究チームが開発した「カスケード変調器イジングマシン(CMIM: Cascaded Modulator Ising Machine)」は、その名の通り、光通信の世界で完成された技術を計算に応用した独創的な構成を持っている 。
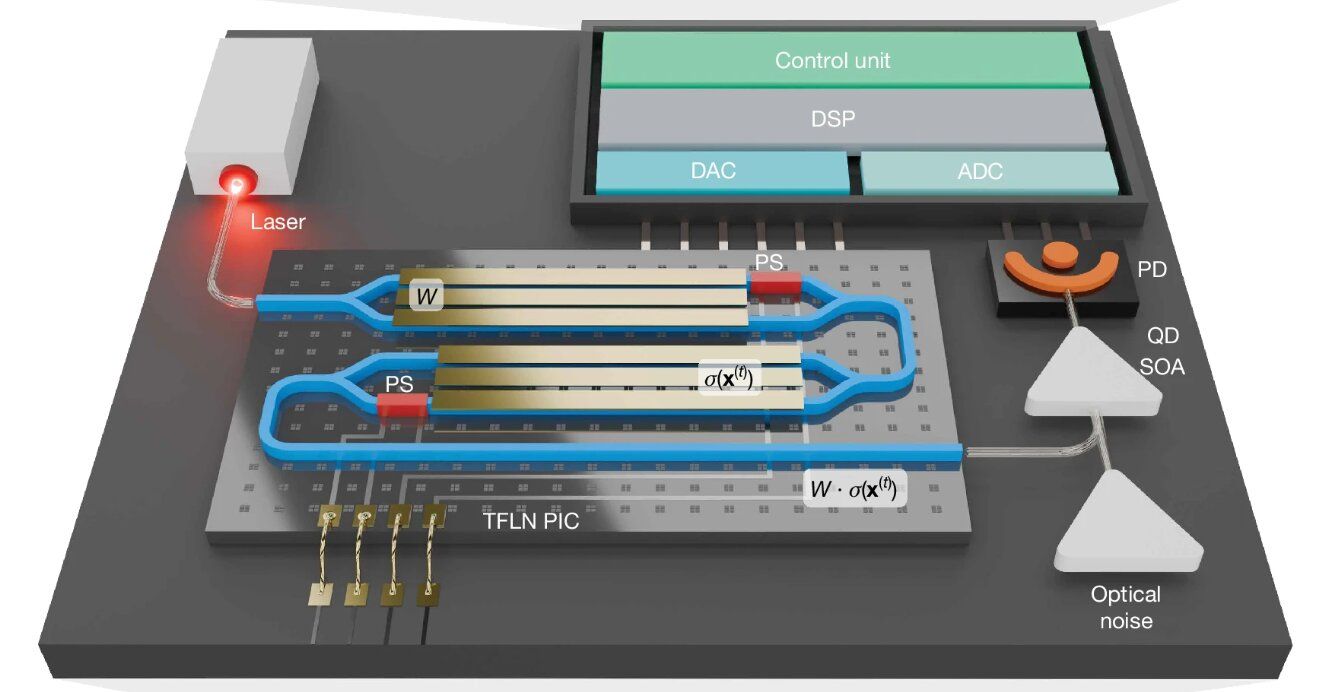
構成要素のシンプルさと高性能の両立
CMIMの驚くべき点は、以下の5つの基本コンポーネントのみで、世界トップクラスの性能を実現していることにある 。
- DFBレーザー: 光源として機能 。
- 薄膜ニオブ酸リチウム(TFLN)変調器: 電気信号を極めて高速かつ低損失に光信号へ変換する 。
- 半導体光増幅器(SOA): 光信号の増幅とともに、後述する「アニーリング」に必要なノイズ源としても機能する 。
- フォトディテクタ(PD): 計算結果である光信号を電気信号へ戻す 。
- デジタル信号処理(DSP)エンジン: 高速動作に伴う信号の歪みを補正し、計算の収束を加速させる 。
ホップフィールド・ネットワークに着想を得たダイナミクス
このシステムは、連想記憶やエネルギーベースのダイナミクスを特徴とする「ホップフィールド・ネットワーク(Hopfield neural network)」の原理を取り入れている 。
計算プロセスにおいて、個々の「スピン」は光パルスの有無や強度として表現される 。これらの光パルスは、光ファイバーのループ内を循環し、TFLN変調器を通過する際、問題の構造を記述した「重み行列(Weight Matrix)」に従って互いに干渉し合う。この「光による意見交換」を繰り返すことで、システムは徐々に安定したパターン(=基底状態)へと収束していく 。
TFLN技術の優位性
本システムにおける最大の実装上の進歩は、薄膜ニオブ酸リチウム(TFLN)変調器の採用である 。TFLNは広い帯域幅(110 GHz以上)と低い駆動電圧(1.5 V程度)を両立しており、これにより毎秒1,060億回(106 GBaud)という極めて高いボーレートでの動作を可能にした 。これは、従来の光イジングマシンを遥かに凌駕する速度である。
実証された圧倒的な計算能力と安定性
実験において、研究チームはこのCMIMを用いて、多様なベンチマーク問題でその性能を実証した。
256スピンの全結合と41,000スピンの疎結合
計算機の性能を測る指標の一つであるスピン数において、本マシンは「全結合(All-to-all connectivity)」において最大256スピン、すなわち65,536通りの全相互作用をプログラム可能な状態でサポートしている 。これは、既存の光電子発振器ベースのイジングマシンとしては世界最大の規模である 。
さらに、相互作用が限定的な「疎結合(Sparse)」な問題においては、41,209スピン(205,000以上の結合)という大規模な計算にも対応できることを示した 。
200 GOPSの高速処理
1波長チャンネルあたり200 GOPS(ギガ演算/秒)を超える計算スループットを達成しており、これは先行研究のほぼ2倍に相当する 。さらに、並列化(マルチプレキシング)戦略を導入することで、将来的には3,000万スピン以上をサポートし、毎秒9.3 POPS(ペタ演算/秒)という、最新のGPU(NVIDIA H100など)を凌駕する効率性を実現できる可能性も示唆されている 。
類を見ない安定性
従来の光イジングマシンは、光の位相や振幅の変動に極めて敏感で、計算の安定性がミリ秒単位で失われることが多かった。しかし、CMIMはDSP(デジタル信号処理)技術を計算ループ内に組み込むことで、ハードウェアの不完全性を補正することに成功した 。結果として、室温環境下で数時間にわたって安定して動作し続けることが可能となり、複雑な問題を繰り返し探索する実用的な計算プラットフォームとしての地位を確立した 。
タンパク質折り畳みと物流最適化
研究チームは、このマシンが単なる実験装置ではなく、現実の困難な問題を解決できることを証明するため、2つの代表的な応用事例に取り組んだ。
タンパク質折り畳み(Protein Folding)
新薬開発の鍵となるタンパク質構造の予測は、膨大なアミノ酸配列がどのように立体構造を形成するかを解明する難問である。研究チームは、アミノ酸を疎水性(H)と親和性(P)に簡略化した「HPモデル」をイジング形式にマッピングし、計算を行った 。
結果として、最大30アミノ酸の配列において、99%以上のエネルギー精度で構造を予測することに成功した 。これは、超伝導量子アニーラ(D-Wave)と同等のパフォーマンスでありながら、冷却不要かつリニアなスケーラビリティ(要素数に対して計算リソースが直線的に増える特性)で達成された 。
数値分割問題(Number Partitioning)
暗号理論やリソース割り当てに関連する「数値分割問題」は、与えられた数値の集合を、合計が等しくなる2つのグループに分けるというNP困難な問題である 。
CMIMはこの問題において、最大256個の数値セットに対し、100%の成功確率で正解(基底状態)を導き出した 。驚くべきことに、同じ問題をD-Waveの最新プロセッサ(Advantage 4.1)で実行した場合、32個以上の数値セットでは成功確率が0.03%まで急落した 。これは、量子アニーラが抱えるハードウェア的な結合の制約が、複雑な全結合問題において大きなボトルネックとなることを示しており、本研究の光ベース・アプローチの優位性を際立たせる結果となった。
5. 成功の秘訣:通信と計算の融合が生んだ「アニーリング効果」
本研究の技術的に最も興味深い知見の一つは、通信技術の「弱点」を計算の「強み」に変えた点にある。
制御されたノイズによる「焼きなまし」
物理システムがエネルギーの最小値を探す際、途中の「局所的な窪み(ローカルミニマム)」に陥って動けなくなることがある。これを回避するために必要なのが、一時的にシステムを揺さぶる「熱(ノイズ)」である 。
研究チームは、高速動作時に不可避的に発生する信号の歪みや、SOA(光増幅器)から発生するASEノイズを、意図的に「アニーリング(焼きなまし)」のプロセスとして利用した 。さらに、SOAのバイアス電流を調整することで、計算の進行に合わせてノイズ量を徐々に減らしていく「指数関数的アニーリング・スケジュール」を実装し、解の品質を劇的に向上させている 。
DSP(デジタル信号処理)の役割
光通信で長距離・大容量のデータ転送を支えるDSP技術を、計算ループの「同期」と「補正」に用いたことも決定的な要因である 。これにより、超高速動作に伴うシンボル間の干渉を排除し、高い精度(実効ビット精度3.3ビット以上)でのアナログ演算を維持することに成功した 。
光コンピュータの実用化へ
クイーンズ大学の研究チームは現在、このシステムのさらなるスケールアップと統合化(チップ化)に取り組んでいる。
産業界との連携
研究チームは、Milkshake Technologyなどの産業パートナーと協力し、物流、金融、製薬といった分野での実世界アプリケーションへの適用テストを開始している 。
汎用コンピュータとの住み分け
ただし、このマシンは従来のコンピュータを完全に置き換えるものではない 。高度な最適化に特化した「アクセラレータ(加速装置)」として、既存のシステムと連携することで、全体の計算効率を飛躍的に高めることが期待されている 。
「No chips, no qubits(チップ不要、量子ビット不要)」という衝撃的なメッセージとともに現れたこの光ベース・イジングマシンは、計算機科学における一つのパラダイムシフトを象徴している 。
汎用的な通信コンポーネントを用い、室温で安定動作しながら、特定の複雑な問題において量子コンピュータを凌駕する性能を示す。この事実は、私たちが直面する「組み合わせ爆発」という巨大な壁を乗り越えるための現実的かつ強力な手段が、すでに私たちの手元にある光ファイバーの中に眠っていることを示唆している。
クイーンズ大学の研究成果は、光コンピュータが単なる科学的好奇心の対象から、産業を支える実用的な計算基盤へと進化する、新たな時代の幕開けを告げるものである。
論文
参考文献
- Queen’s University: Using light-based computing to tackle complex challenges


