
半導体の歴史において、これほど象徴的な協調は稀である。数十年にわたりPCとサーバーの心臓部を巡って熾烈な陣取り合戦を繰り広げてきたIntelとAMDが、同じ設計図を囲んで座っている。彼らを結びつけたのは、友情や妥協ではない。背後に迫る圧倒的な脅威、すなわちAIという新たな演算パラダイムにおけるx86アーキテクチャの陳腐化という恐怖である。
大規模言語モデル(LLM)やニューラルネットワークの台頭により、現代のコンピューティングは途方もない規模の行列乗算を要求している。従来のx86プロセッサは、複雑な条件分岐や汎用的な計算を高速にこなす能力には長けていた。しかし、膨大なデータを並列で掛け合わせるAIの土俵では、NVIDIAのGPUや各社が乱立させる専用NPU(Neural Processing Unit)の後塵を拝してきた。既存のベクトル演算命令の延長線上で計算機を駆動させても、物理的な回路面積と電力効率の壁に阻まれ、計算密度の限界を突破することは不可能になっていたのである。
汎用CPUは、AI時代において高価な周辺機器を制御するための単なる裏方に成り下がるのか。NVIDIAのCUDAエコシステムやArmアーキテクチャの猛追を前に、PCの覇者たちは決断を迫られた。この長年立ちはだかってきた難題に対し、両社が設立した「x86 Ecosystem Advisory Group(EAG)」が導き出した解答が、2026年4月に公開された新たな命令セットアーキテクチャ「AI Compute Extensions(ACE)」である。
本研究は、既存の枠組みを微修正するレベルにとどまらない。演算の次元そのものを引き上げることで、x86プロセッサに従来の16倍という行列計算能力を宿させる。ラップトップからスーパーコンピュータに至るまで、あらゆる階層のコンピュータが専用ハードウェアに依存することなくAIモデルを直接解釈・実行する未来に向けた、反撃のメカニズムを解読する。
線から面への次元跳躍。外積演算が打ち破る計算密度の壁
AIの推論や学習における計算負荷の大部分は、順伝播や逆伝播に伴う行列乗算が占めている。これまでのx86プロセッサは、AVX10に代表されるSIMD(単一命令・複数データ)拡張命令を用いてこの行列計算を処理してきた。SIMDはいわば、1列に並んだ職人がそれぞれ1つの部品を同時に加工する流れ作業である。データの束(ベクトル)を読み込み、要素ごとにドット積(内積)を計算する手法は、ある程度の並列化をもたらした。
しかし、AIモデルの規模が指数関数的に増大する中で、この1次元的なアプローチは破綻を迎えつつある。一度の演算で得られる結果が少ないため、幾度もメモリからデータを呼び出し、計算を繰り返さなければならない。結果として、プロセッサの演算器が空回りし、メモリ帯域幅がボトルネックとなる「データの渋滞」が発生していた。
ACEが導入した最大のブレイクスルーは、計算の基礎アルゴリズムを内積から「外積(Outer Product)」へと転換した点にある。外積演算は、2つの入力ベクトルから一気に行列(2次元の面)を作り出す手法である。縦糸と横糸を交差させて一瞬で広大な織物を完成させる機織り機を想像してほしい。
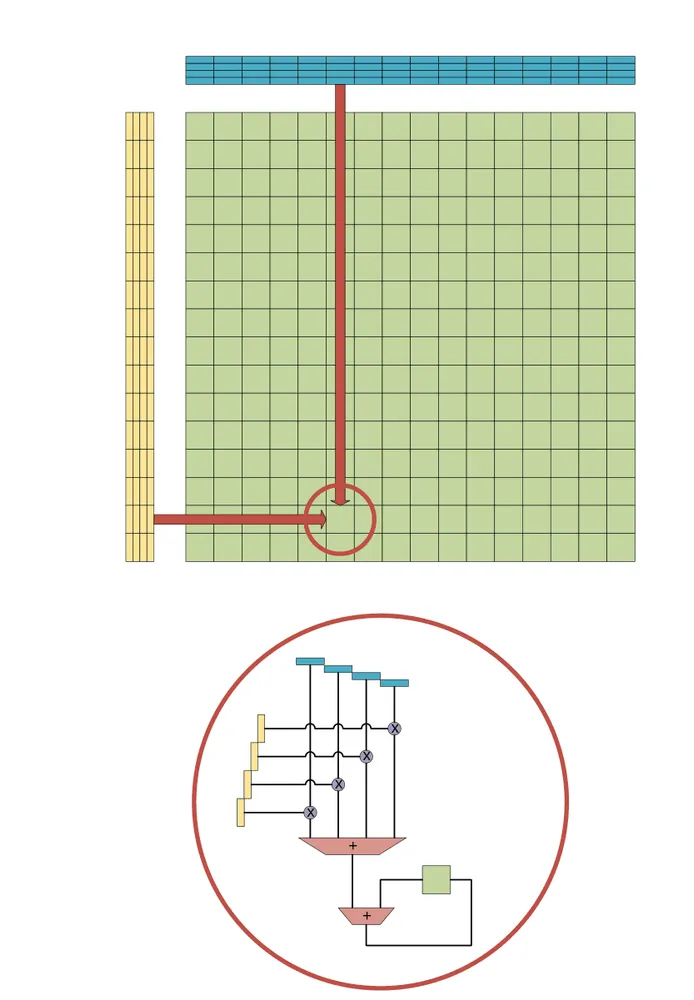
ACEは、既存のAVX10が備える512ビットのZMMベクトルレジスタを2つ入力として受け取る。INT8(8ビット整数)データの場合、それぞれのベクトルには16×4の要素が格納されている。これらを外積で掛け合わせることで、交差点となるすべてのグリッドで同時に積が計算され、結果が2次元のタイルレジスタに蓄積される。
この次元の跳躍がもたらす効果は圧倒的である。同じ2つの入力ベクトルを消費する条件下において、従来のAVX10による積和演算(VNNI INT8)が1命令あたり64回の乗算を実行するのに対し、ACEの外積演算は1命令で1024回の乗算を完了させる。実に16倍の計算密度向上である。面積と電力が厳しく制限されたシリコンダイの上で、これほど劇的な効率化を実現したアーキテクチャの刷新は稀有である。
| 比較項目 | 従来のSIMD (AVX10) | 新アーキテクチャ (ACE) |
|---|---|---|
| 演算アルゴリズム | ドット積 (内積) | 外積 (Outer Product) |
| INT8時の乗算回数/命令 | 64回 | 1024回 |
| BF16時の乗算回数/命令 | 32回 | 512回 |
| スケーリング特性 | 1次元的 (線形) | 2次元的 () |
| 消費する入力ベクトル数 | 2 | 2 |
8つの専用キャンバスがもたらす兵站革命。データ供給の枯渇を防ぐタイルレジスタ
演算器をいかに高速化しても、そこに供給するデータが遅れて到着すればシステム全体は停滞する。16倍に跳ね上がった計算密度を支えるためには、計算結果を一時的に保持し、キャッシュメモリへのアクセスを極限まで減らす新たなデータの保管場所が必要となる。
ここでACEが導入したのが、CPUコア内部に新設された8つの「タイルレジスタ」である。1つのタイルレジスタは512ビット×16行(合計1KB)の容量を持ち、2次元のデータをそのままの形で保持する。これは、画家がいちいち倉庫へ絵の具を取りに行く手間を省くため、手元に広大な専用パレットを8枚用意したような状態である。
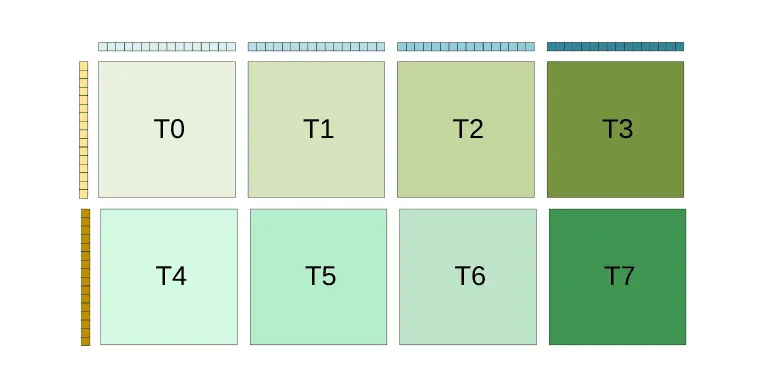
ソフトウェアはこの8つのタイルレジスタを組み合わせ、「4×2のブロックレジスタカーネル」といったより大きな演算ウィンドウを構築できる。このブロック化の恩恵は、メモリ帯域幅の節約という形で顕著に表れる。単一のタイルレジスタ(1×1)を使用する場合、1回の外積演算あたり2回のベクトルロードが必要である。しかし、4×2の構成を組んで入力データを複数のレジスタ間で共有(再利用)することで、1演算あたりのロード回数を0.75回まで削減できる。
Intelは過去にサーバー向けXeonプロセッサ(Sapphire Rapids)において「AMX(Advanced Matrix Extensions)」という独自規格を導入し、巨大な演算ユニットとレジスタを実装した実績を持つ。AMXはサーバー領域において極めて強力なAI推論性能を発揮したが、実装に必要なシリコン面積が大きく、発熱量も桁違いであった。そのため、限られた電力予算で動作するクライアントPC向けのCPUへそのまま搭載することは物理的に不可能に近かった。
なぜIntelは自社の強力なAMXを手放し、AMDとともにACEへ合流したのか。その理由はここにある。ACEは、AMXの「面的にデータを保持する」という優れた設計思想を継承しつつ、AVX10のベクトルレジスタを巧妙に流用することでハードウェアの追加コストを最小限に抑えている。専用の巨大な演算器を丸ごと載せるのではなく、既存のベクトル演算器の隣に外積計算用の小さな回路とタイルレジスタを添えるアプローチを採った。これにより、発熱や面積に制約のあるノートPCのCPUにまで、高度な行列加速機能を搭載する道を拓いたのである。サーバーからエッジまで、x86のあらゆる階層をカバーする普遍的なAI対応力こそが、EAGが目指した到達点である。
低精度フォーマットの迷宮を抜ける。ハードウェアによる規格の吸収
AIモデルの進化は、パラメータのデータ幅を切り詰める「低精度化」の歴史でもある。32ビットの浮動小数点数(FP32)から始まった計算は、今や16ビット、8ビット、さらには4ビット以下の極小フォーマットへと移行している。数百億、数千億というパラメータを持つLLMを限られたメモリ容量に収め、推論速度を引き上げるための必然的な進化である。
一方で、低精度化はモデルの回答精度の劣化という深刻なトレードオフを抱えている。単にデータ幅を切り捨てるだけでは、数値表現のダイナミックレンジが失われ、計算結果が破綻してしまう。この精度の壁を乗り越えるために考案されたのが、業界標準化団体OCP(Open Compute Project)が策定したMX(Microscaling Formats)という特殊なデータ構造である。
ACEは、商用プロセッサとして初めてこのOCP MX標準にネイティブ対応した。一般的なINT8やBF16に加え、OCP FP8、MXFP8、MXINT8といったフォーマットを直接ハードウェアで処理する。
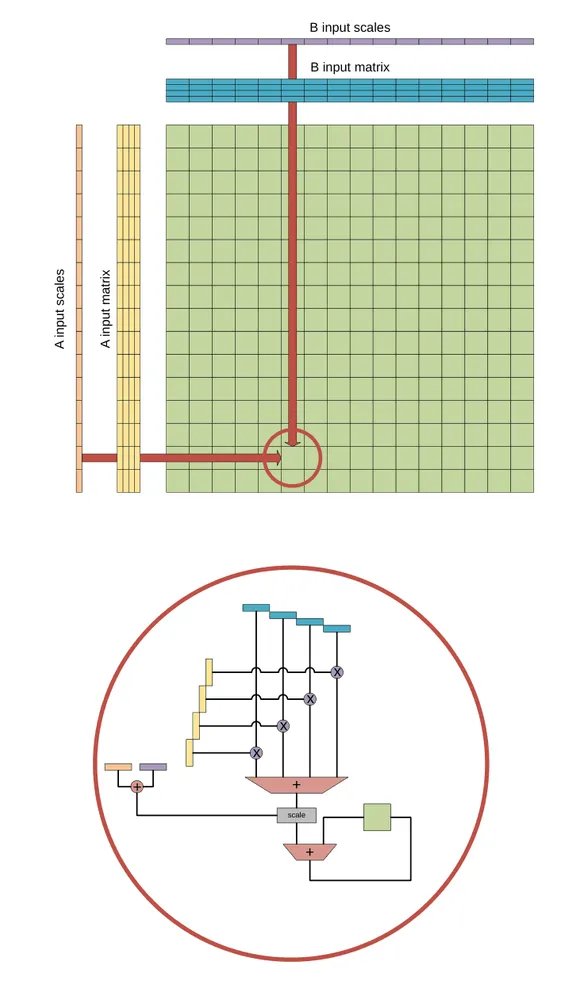
特筆すべきは「インラインブロックスケーリング」のサポートである。これは、小さなデータ幅(例えば8ビット)の数値群に対して、共通の倍率(スケール値)をグループごとに掛け合わせる仕組みである。これにより、全体としてのデータサイズを極小化しながら、必要な箇所で十分な数値の広がりを持たせることができる。ACEは、この倍率を格納するための1024ビットの専用レジスタ(Block Scale Register)を搭載し、乗算とスケーリングを命令サイクルの中に完全に組み込んだ。メモリへの負荷を激減させつつ、推論精度を高く保つという難題をシリコンの物理回路で解決したのである。
さらに、未知の次世代フォーマットへの適応力も備えている。データフォーマットの流行が半年単位で移り変わるAI業界において、ハードウェアを固定化させることは死を意味する。AVX10が持つVPERM命令(ルックアップテーブルを用いたデータ変換)や、新設されたVUNPACKB命令を駆使することで、2ビットや7ビットといった非標準の奇抜なデータ幅であっても、ソフトウェア定義で効率的に8ビット幅へ変換し、演算器へ流し込むことが可能である。
近年、大規模なLLMをスマートフォンのような極小環境で動かすために「Hadamard incoherence」や「lattice codebooks」といった複雑な量子化アルゴリズムの研究が進んでいる。ACEの設計思想は、こうした未来の符号化技術が主流になった際にも、即座にCPU側で対応できる俊敏性(Agility)を確保している。
断片化したエコシステムの統合。摩擦なきソフトウェア基盤の構築
ハードウェアがいかに優れていても、ソフトウェア開発者がそれを容易に利用できなければ砂上の楼閣に過ぎない。現在、エッジデバイスでAIを動かすためには特定のNPU向けにコードをコンパイルし直し、サーバーで動かすためにはGPU向けのCUDAコードを記述しなければならないという、深刻なエコシステムの断片化が起きている。
ACEが業界全体に与える最もマクロなインパクトは、x86エコシステムの再統一と「開発者の摩擦」の消滅である。IntelとAMDがEAGを通じて命令セットを完全に標準化したことで、NumPy、SciPyといった数値計算ライブラリや、PyTorch、TensorFlowといった機械学習フレームワークは、単一のコードベースで地球上のほぼすべてのx86マシンをターゲットにできるようになる。
ソフトウェア開発者の視点に立てば、これはNVIDIAが構築した堅牢なCUDAエコシステムに対する強力な防波堤となる。特定のハードウェアベンダーに縛られることなく、手元のラップトップで開発・テストしたAIモデルを、一切のコード改変なしでクラウド上の巨大なサーバー群へデプロイし、シームレスに行列加速の恩恵を受けられる。オープンな標準規格こそが、寡占状態にあるAIチップ市場に競争を取り戻す最大の武器となる。
ダークシリコンの呪縛と未来のプロセッサ設計。圧倒的計算力と熱のトレードオフ
1命令で1024回もの乗算を瞬時に叩き出すアーキテクチャは、シリコン工学における物理法則との戦いを引き起こす。プロセッサのチップ内で極度に演算が密集すると、その部分だけが異常な熱を発し、冷却が追いつかなくなる。結果として、熱設計電力(TDP)の制約を超えないようにクロック周波数を強制的に下げるか、チップの一部の電源を落とさざるを得ない。この、トランジスタは存在するが熱の制約で稼働させられない領域を「ダークシリコン問題」と呼ぶ。
ACEの実装において、この熱の壁は避けて通れない課題である。特に薄型のノートPCにおいて、外積演算器をフル稼働させれば、バッテリーは瞬時に消耗し、冷却ファンは限界を超えて回転することになる。データセンターにおいても、ラックあたりの冷却コストが高騰し、TCO(総所有コスト)を圧迫するリスクを孕んでいる。
この物理的限界に対し、IntelとAMDの次世代チップ設計は高度な熱管理とタスクのオーケストレーションを迫られる。具体的には、プロセッサ内のスケジューラがAIワークロードを検知した瞬間、背後で動いている不要なバックグラウンドタスクを効率的な省電力コア(EコアやZen 4cなど)へ退避させ、メインコアの演算器へ電力予算を集中させるような動的な電力ルーティングが必須となる。
数年後の市場を見据えると、単に命令セットを実装するだけでは競争に勝つことはできない。Apple Siliconがユニファイドメモリと専用マトリックスコプロセッサで実現しているワットパフォーマンスの高さや、QualcommのSnapdragon Xシリーズが提示する持続的な処理能力に対し、x86は「ピーク性能の高さ」だけでなく「熱の分散と持続力」でも答えを出さなければならない。ACEという強力なエンジンを手に入れたことで、今後のx86プロセッサの競争軸は、純粋な演算能力から、熱と電力の最適化アルゴリズムという新しいフェーズへと移行する。
AIという不可逆の潮流の中で、x86アーキテクチャは長らく防戦を強いられてきた。しかし、かつてない計算密度を誇る外積演算エンジンと、両巨頭の歴史的な歩み寄りによって生み出されたACEは、CPUの反撃の起点である。計算の次元を物理的に引き上げたこの拡張命令は、世界中のデータセンターや個人のデスクで稼働する数十億台のマシンを、一斉に高性能なAIエンジンへと変貌させるポテンシャルを秘めている。


