
AIスタートアップd-Matrixが、推論インフラの深刻なボトルネックを解決する可能性を秘めたネットワークカード「JetStream」を発表した。標準Ethernet上で2マイクロ秒という驚異的な低遅延を実現し、大規模モデルの分散処理を加速する。GPUが支配する市場に、果たして新たな選択肢は生まれるのだろうか。
AI推論時代の新たなボトルネック、「ネットワーク」という壁
生成AIの進化が指数関数的な様相を呈する中、AIコンピューティングの主戦場は「訓練」から、サービス提供の根幹をなす「推論」へと明確にシフトしている。自律的に思考し行動するエージェントAIや、テキスト、画像、音声をリアルタイムで扱うマルチモーダルAIの台頭は、ユーザーとのインタラクティブな応答性を極限まで高めることを要求する。
この要求に応えるため、数百億から数兆パラメータにも及ぶ巨大モデルを複数のサーバー、あるいは複数のラックにまたがって分散処理する「スケールアウト」アーキテクチャが不可欠となった。しかし、ここで新たな壁が立ちはだかる。それがサーバー間の通信によって生じる「ネットワーク遅延」だ。どれだけ個々のプロセッサが高速であっても、ノード間のデータ連携が滞れば、システム全体の性能は著しく低下する。このネットワークこそが、現代AIインフラにおける最大のボトルネックとなりつつあるのだ。
この根源的な課題に対し、AIチップのスタートアップd-Matrixが真正面から挑む。同社が発表した「JetStream I/Oカード」は、この壁を打ち破るためにゼロから設計された、いわばAI推論専用の神経系だ。
d-Matrixの解:標準技術で実現する「2マイクロ秒」の世界
一見すると、JetStreamは標準的なPCIe 5.0対応のネットワークインターフェースカード(NIC)に見える。200Gb/sのポートを2つ、または単一の400Gb/sポートとして構成可能で、接続には広く普及している標準的なEthernetを用いる。 この「標準技術への準拠」こそが、d-Matrixの最初の戦略的選択なのだ。
「我々はエコシステムとの接続において、何かエキゾチックなものを構築したくありませんでした。これは我々の顧客が求めていることだからです。『私のデータセンターにあるものに、簡単にプラグアンドプレイで接続できるのか?』と。我々は『はい、あなたがお使いの標準Ethernetスイッチをそのまま使い続けられます』と答えられるのです」
– Sree Ganesan, d-Matrix Vice President of Product
しかし、その心臓部は既製品とは全く異なる。d-MatrixのCEO、Sid Sheth氏によれば、NVIDIAなどの市販NICの利用も検討したが、達成可能なレイテンシに満足できなかったという。 そこで彼らが選んだのは、約150Wを消費する独自設計のFPGA(Field Programmable Gate Array)を搭載し、ネットワーク遅延をわずか2マイクロ秒にまで削減するという、極めて野心的な道だった。
この「2マイクロ秒」という数値が、JetStreamを特別な存在にしている。データセンター内で一般的に観測されるネットワーク遅延が数十から数百マイクロ秒であることを考えれば、その差は歴然だ。AIモデルが複数のノードに分割され、推論処理がリレーのように次々と受け渡されるパイプライン並列処理において、この遅延の短縮はトークン生成速度の劇的な向上に直結する。
推論エンジン「Corsair」との相乗効果:SRAMとLPDDR5の二刀流
JetStreamの真価は、d-Matrixが提供するAI推論アクセラレーター「Corsair」と組み合わせることで初めて発揮される。d-Matrixは、コンピュート(Corsair)、ネットワーク(JetStream)、そしてソフトウェア(Aviator)を垂直統合した、AI推論に最適化された完全なプラットフォームを提供しようとしているのだ。
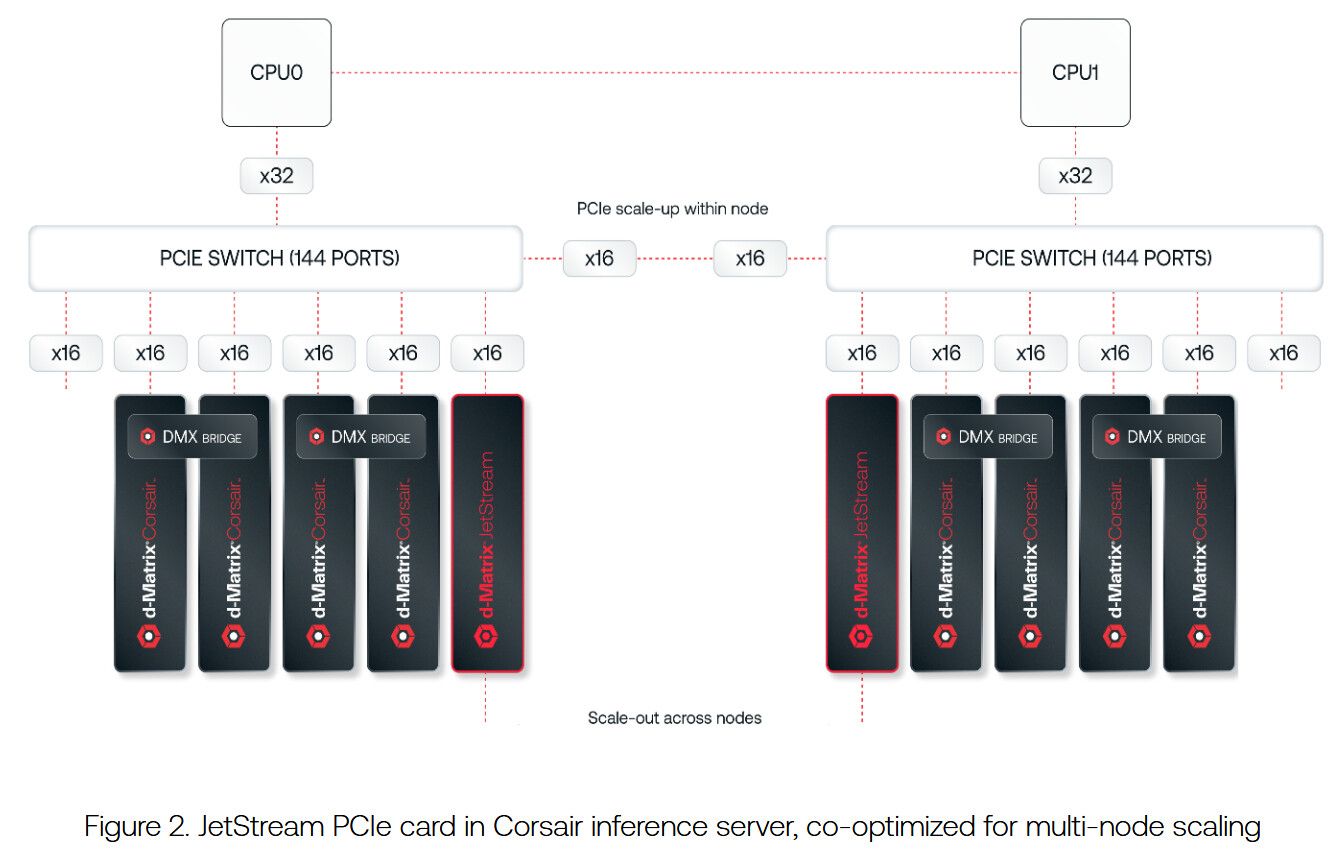
Corsairのアーキテクチャは、NVIDIAのGPUとは思想が大きく異なる。その核心は、メモリと演算の関係性を再定義するユニークなメモリ階層にある。
メモリ階層の妙:超高速SRAMと大容量LPDDR5
AI推論、特にTransformerモデルの処理は、演算能力(FLOPS)よりもメモリ帯域幅が性能を決定づける「帯域幅律速」のワークロードである。モデルの巨大なパラメータをいかに高速に演算器へ供給できるかが鍵となる。
この課題に対し、Corsairは二段構えの戦略をとる。
- 超高速SRAM: 各Corsairカードは、合計2GBのSRAMを搭載し、150 TB/sという驚異的な帯域幅を誇る。これは、NVIDIAのフラッグシップであるB200が搭載するHBM3eメモリの帯域幅(8 TB/s)を遥かに凌駕する数値だ。
- 大容量LPDDR5: 同時に、ハイエンドノートPCなどで採用されるLPDDR5メモリを256GB搭載。帯域幅は400 GB/sとSRAMには及ばないものの、巨大なモデル全体を格納する十分な容量を確保する。
この設計思想は、d-MatrixのCEO、Sid Sheth氏が語る「顧客が速度とコストの間でどのようなトレードオフを望むかに応じて、モデルを実行するメモリの種類を選べる」という柔軟性につながる。
SRAMで実現する究極のパフォーマンス
最高のパフォーマンスを求める場合、モデルのパラメータはSRAM上で処理される。d-Matrixによれば、このアプローチにより、Llama 3.1 70B(700億パラメータ)のようなモデルで、トークンあたりの生成遅延をわずか2ミリ秒まで短縮できるという。 これは、HBMに依存せず、膨大なSRAMをチップ上に集積することで超低遅延を実現するGroqやCerebrasといった他のAIチップスタートアップと共通する戦略であり、AI推論における一つの潮流となりつつある。
しかし、この戦略には課題もある。Corsairアクセラレーター8基で構成される1ノードあたりのSRAM容量は合計16GBに留まるため、2000億パラメータクラスのモデルをSRAM上で実行するには、8ノード(64アクセラレーター)を収容するラックが必要になる。 より大規模なモデルでは、さらに多くのノード、場合によっては複数のラックが必要不可欠だ。
そして、この多数のノードを一つの巨大な仮想アクセラレーターとして機能させるための神経網こそが、JetStreamの役割なのである。
d-MatrixはNVIDIAの牙城を崩せるか
d-Matrixが描く戦略は、推論市場に特化し、GPUとは根本的に異なるアーキテクチャで戦いを挑むという、明確な意志の表れだ。同社の中核技術であるDigital In-Memory Compute (DIMC)は、メモリセル自体が演算能力を持つことで、データ移動を原理的に削減する。 これは、プロセッサとメモリの間でデータを往復させる従来のフォン・ノイマン型アーキテクチャの軛からAIを解放しようとする試みと言える。
JetStreamが実現する「スケールアウト」は、各ノードが独立して処理を進め、結果をリレーしていくパイプライン並列などに最適化されている。これは、NVIDIAがNVLinkによって超広帯域のチップ間接続を実現し、単一の巨大なGPUとして振る舞わせる「スケールアップ」型のアプローチとは対照的だ。
現時点での課題は、ノードあたりの総帯域幅が800Gb/sに留まる点だろう。NVIDIAのNVL72ラックシステムなどが実現する数TB/sクラスの総帯域幅と比較すると見劣りする。しかし、これはd-Matrixが異なる並列化戦略を選択した結果であり、優劣の問題ではないのかもしれない。
未来へのロードマップ:3DIMCと次世代「Raptor」
注目すべきは、JetStreamとCorsairが決してd-Matrixの最終到達点ではないという事実だ。同社はすでに、AIの「メモリ・ウォール」問題を完全に打破しうる次世代アーキテクチャ「Raptor」と、その中核技術「3DIMC (3D stacked digital in-memory compute)」へのロードマップを公開している。
3DIMCは、DIMC技術を実装したロジックダイの上に、複数のDRAMダイを垂直に3D積層する技術だ。 これにより、チップの水平方向の制約から解放され、桁違いの数のI/Oを確保できる。d-Matrixは、この技術によって、次世代メモリ規格であるHBM4と比較しても「10倍のメモリ帯域幅」と「10倍のエネルギー効率」という、極めて野心的な目標を掲げている。

このロードマップから見えてくるのは、JetStreamが、来るべき超広帯域メモリ時代への重要な布石であるということだ。将来的には、電気的なI/Oチップレットから、ラックや列をまたいでスケールする光I/Oチップレットへと進化させる計画も示されている。
AIインフラの地殻変動は「ネットワーク」から始まる
d-MatrixのJetStream発表は、単なる高性能NICの登場を意味しない。これは、AI推論のボトルネックが、演算からメモリ、そして今まさにネットワークへと移行しつつある時代の象徴的な出来事である。
ハードウェア(Corsair, JetStream)とソフトウェア(Aviator)を密に連携させ、推論ワークロードに最適化されたソリューションをエンドツーエンドで提供する。この垂直統合アプローチは、NVIDIAがCUDAエコシステムで築き上げた牙城に対する、最も現実的な挑戦状かもしれない。
JetStreamは現在、顧客へのサンプリングが開始されており、年内には量産体制に入る予定だ。 この新しいアーキテクチャが、超低遅延を求めるクラウドプロバイダーやAIサービス事業者に受け入れられ、AIインフラの勢力図を塗り替えるきっかけとなるのかが今後の焦点となっていくだろう。
Sources

